
Mastering Large Language Models: A 7-Step Learning Journey
Mastering Large Language Models: A 7-Step Learning Journey
GPT-4, Llama, Falcon, and various other Large Language Models (LLMs) have taken center stage in the world of technology. It’s likely that you’ve already interacted with one of these LLMs, whether through a chat interface or an API.
If you’ve ever pondered over what LLMs truly entail, how they operate, and what possibilities they hold, then this guide is tailored to meet your needs. Whether you’re a data professional with a keen interest in large language models or simply someone intrigued by their capabilities, this comprehensive guide serves as your compass for navigating the vast landscape of LLMs.

Are you looking to start a career in data science and AI and need to learn how? I offer data science mentoring sessions and long-term career mentoring:
- Mentoring sessions: https://lnkd.in/dXeg3KPW
- Long-term mentoring: https://lnkd.in/dtdUYBrM
Subscribe to my newsletter To Data & Beyond for free to get full and early access to my articles:
1. Understanding the Basics
If you’re new to the world of Large Language Models (LLMs), it’s beneficial to begin with a high-level overview to grasp their significance and power. Let’s start by addressing some fundamental questions:
- What exactly are LLMs?
- Why have they gained such widespread popularity?
- How do LLMs differ from other deep-learning models?
- What are the common use cases for LLMs?
Let’s explore these questions together one by one:
1. What Are LLMs?
Large Language Models, often abbreviated as LLMs, represent a subset of deep learning models that undergo training on vast collections of text data. These models are characterized by their sheer size, boasting tens of billions of parameters, and they exhibit exceptional performance across a wide spectrum of natural language processing tasks.
2. Why Are They Popular?
The popularity of LLMs can be attributed to their unique capacity to comprehend and generate coherent, contextually relevant, and grammatically accurate text. Key reasons behind their widespread adoption include:
- Exceptional proficiency across a diverse range of language-related tasks.
- The accessibility and availability of pre-trained LLMs have democratized the field of AI-powered natural language understanding and generation.
3. So How Are LLMs Different from Other Deep Learning Models?
LLMs distinguish themselves from other deep learning models through their monumental size and distinctive architecture, which prominently feature self-attention mechanisms. Notable differentiators encompass:
- The Transformer architecture revolutionized natural language processing and serves as the foundation for LLMs (we’ll delve into this in our guide).
- The capability to capture long-range dependencies within the text facilitates a more profound contextual comprehension.
- Versatility in handling a broad array of language tasks, spanning from text generation and translation to summarization and question-answering.
4. What Are the Common Use Cases of LLMs?
LLMs find application in a multitude of language-related tasks, including:
- Natural Language Understanding: Proficiency in tasks like sentiment analysis, named entity recognition and question answering.
- Text Generation: Generating human-like text suitable for chatbots and other content generation purposes (an experience you might have encountered with ChatGPT or similar models).
- Machine Translation: Considerable enhancements in the quality of machine translation.
- Content Summarization: The ability to produce concise summaries of lengthy documents, which can be especially handy for tasks like summarizing YouTube video transcripts.
2. Exploring LLM Architectures
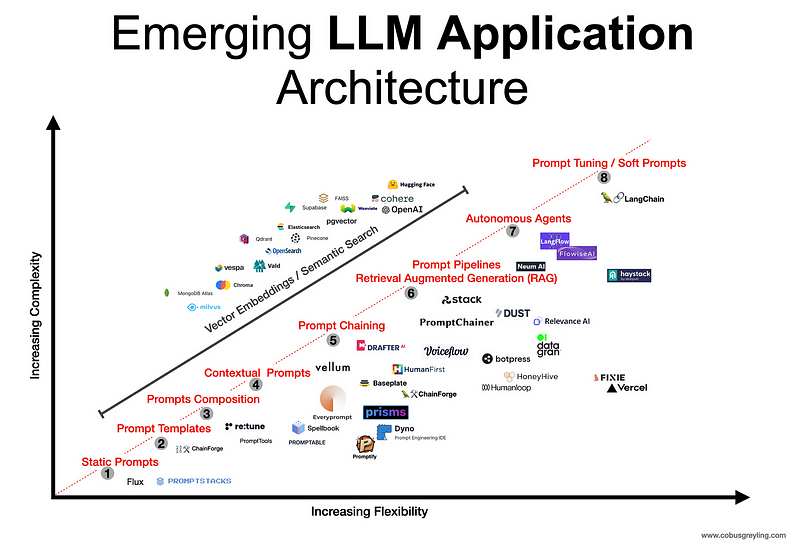
Now, as you progress in your exploration of Large Language Models (LLMs), it’s essential to focus on the foundational transformer architecture that underlies these remarkable models. In this phase of your journey, Transformers demand your full attention, and there’s no wordplay intended here.
The original Transformer architecture, as introduced in the influential paper “Attention Is All You Need,” brought about a paradigm shift in natural language processing:
Key Features: This architecture incorporates self-attention layers, multi-head attention mechanisms, and feed-forward neural networks. It often employs an encoder-decoder structure to tackle various NLP tasks.
Use Cases: Transformers serve as the cornerstone for notable LLMs such as BERT and GPT, which have made significant strides in language understanding and generation.
While the original Transformer architecture typically utilizes an encoder-decoder design, it’s important to note that variations exist, including encoder-only and decoder-only configurations, offering flexibility in addressing specific tasks and requirements.
3. Using Pre-trained LLM
Now that you’ve established a foundational understanding of Large Language Models (LLMs) and the underlying transformer architecture, it’s time to delve into the concept of pre-training these models. Pre-training is the bedrock upon which LLMs are built, as it exposes them to vast corpora of textual data, equipping them with the ability to grasp the intricacies of language.
Here’s a summary of key aspects you should familiarize yourself with:
- Objectives of Pre-training LLMs: Pre-training entails subjecting LLMs to extensive text corpora to enable them to grasp language patterns, grammar, and context. This involves specific pre-training tasks such as masked language modeling and next-sentence prediction, which facilitate the model’s language understanding.
- Text Corpus for LLM Pre-training: LLMs are trained on extensive and diverse text corpora, encompassing a wide array of sources like web articles, books, and more. These datasets are typically massive, containing billions to trillions of text tokens. Some common datasets include C4, BookCorpus, Pile, OpenWebText, and others.
- Training Procedure: Gain insight into the technical aspects of the pre-training process, including the use of optimization algorithms, batch sizes, and the number of training epochs. Additionally, be aware of challenges associated with pre-training, such as the need to mitigate biases in the training data.
4. Fine Tuning LLM
Following the initial pre-training of Large Language Models (LLMs) on extensive text corpora, the subsequent imperative task is fine-tuning, which tailors these models to specific natural language processing tasks. Fine-tuning is instrumental in adapting pre-trained models for tasks like sentiment analysis, question answering, or translation, enhancing their precision and efficiency.
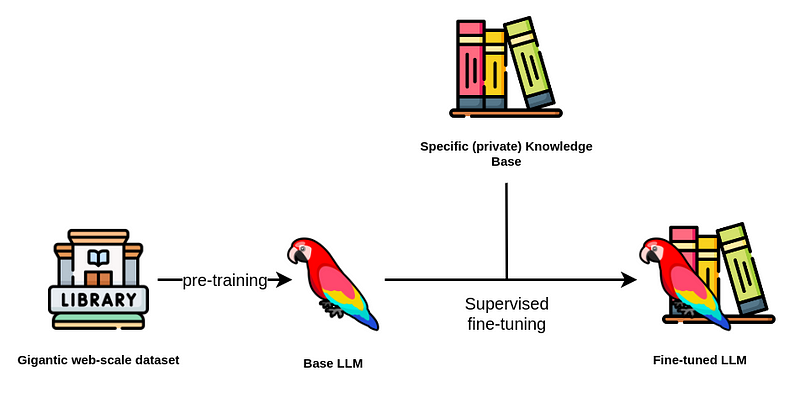
Fine-tuning serves several crucial purposes:
- Pre-trained LLMs exhibit a broad grasp of language but require fine-tuning to excel in specific tasks. This process enables the model to comprehend the subtleties inherent in the target task.
- Fine-tuning significantly reduces the amount of data and computational resources required compared to training a model from scratch. By building upon the foundational understanding provided by pre-training, fine-tuning can operate with a considerably smaller dataset than pre-training.
Now, let’s delve into the methodology of fine-tuning LLMs:
- Select the Pre-trained LLM: Carefully choose the pre-trained LLM that aligns with your intended task. For instance, if you’re addressing a question-answering task, opt for a pre-trained model with an architecture suited for natural language comprehension.
- Data Preparation: Assemble a dataset tailored to the specific task you want the LLM to perform. Ensure that this dataset includes labeled examples and adheres to the required formatting standards.
- Fine-Tuning: Once you have identified the base LLM and organized the task-specific dataset, it’s time to initiate the fine-tuning process. However, you might be faced with various challenges, particularly when LLMs possess tens of billions of parameters, and accessing the model’s weights can be problematic.
Fine-Tuning Without Access to Model Weights
In cases where you lack direct access to the model’s weights and rely on utilizing the model through an API, you can employ in-context learning, avoiding the need for explicit fine-tuning. This approach leverages the model’s capacity to acquire knowledge through analogy by providing input and sample output examples of the desired task.
Prompt Tuning offers two strategies
- Hard Prompt Tuning involves direct modifications to the input tokens within the prompt, without altering the model’s weights.
- Soft Prompt Tuning appends the input embedding with a learnable tensor. A related concept is prefix tuning, where learnable tensors are incorporated with each Transformer block, as opposed to only the input embeddings.
Given the substantial number of parameters in LLMs, fine-tuning the weights in all layers can be resource-intensive. Recently, Parameter-Efficient Fine-Tuning Techniques (PEFT) like LoRA and QLoRA have gained popularity. QLoRA, for instance, enables fine-tuning of a 4-bit quantized LLM on a single consumer GPU without compromising performance. These techniques introduce a small set of learnable parameters called adapters, which are fine-tuned instead of the entire weight matrix, streamlining the process.
5. Alignment and LLM Post-Training
Large Language models have the potential to produce content that might be problematic, biased, or not in line with user expectations. Aligning an LLM refers to the process of harmonizing its behavior with human preferences and ethical standards. This endeavor seeks to minimize the risks associated with model behavior, such as biases, contentious responses, and the generation of harmful content.
You can explore various techniques to achieve alignment, including:
- Reinforcement Learning from Human Feedback (RLHF): RLHF involves gathering human preference annotations for LLM outputs and building a reward model based on these annotations. This method helps the model learn to generate content that is more in line with human preferences.
- Contrastive Post-training: Contrastive post-training aims to use contrastive techniques to automate the creation of preference pairs for LLMs. By contrasting different model outputs and learning from these comparisons, the model can be fine-tuned to generate content that better aligns with desired preferences and ethical standards.
6. LLM Evaluation and Continuous Learning
After fine-tuning a Language Model (LLM) for a specific task, it’s crucial to assess its performance and plan for ongoing learning and adaptation. This step is vital to ensure that your LLM remains effective and up-to-date.

1. Assessing LLM Performance
Evaluating the performance of LLMs allows you to gauge their effectiveness and pinpoint areas for enhancement. Here are key elements to consider when evaluating LLMs:
- Task-Specific Metrics: Select appropriate metrics tailored to your specific task. For instance, in text classification, you might employ traditional evaluation metrics like accuracy, precision, recall, or F1 score. For language generation tasks, metrics such as perplexity and BLEU scores are commonly used.
- Human Evaluation: Engage experts or crowdsourced annotators to assess the quality of the generated content or the model’s responses in real-world scenarios. This human perspective provides valuable insights.
- Bias and Fairness: Evaluate LLMs for biases and fairness concerns, particularly when deploying them in real-world applications. Analyze how models perform across different demographic groups and address any disparities to ensure equitable outcomes.
- Robustness and Adversarial Testing: Test the LLM’s resilience by subjecting it to adversarial attacks or challenging inputs. This practice helps uncover vulnerabilities and strengthens the model’s security against potential threats.
2. Continuous Learning and Adaptation
To ensure that LLMs remain updated with new data and tasks, consider implementing the following strategies:
- Data Augmentation: Continuously expand your data repository to prevent performance degradation resulting from outdated information. A well-rounded data set is essential for maintaining model accuracy.
- Retraining: Periodically retrain the LLM with new data and fine-tune it for evolving tasks. Regular fine-tuning of recent data helps the model stay current and aligned with changing requirements.
- Active Learning: Employ active learning techniques to identify instances where the model is uncertain or likely to make errors. Collect annotations for these instances to refine the model and enhance its performance.
In addition to these considerations, it’s important to address the issue of hallucinations in LLMs. Exploring techniques such as Retrieval augmentation can help mitigate the occurrence of hallucinations, improving the model’s overall reliability.
7. Building and Deploying LLM Applications
Once you’ve developed and fine-tuned a Language Model (LLM) for specific tasks, it’s time to move forward with creating and utilizing applications that make the most of the LLM’s capabilities. In other words, let’s explore how to harness LLMs to construct practical real-world solutions.
1. Constructing Applications Utilizing LLMs
- Custom Application Development: Craft applications designed to meet your precise requirements. This might encompass developing web-based interfaces, mobile apps, chatbots, or integrating the LLM into existing software systems.
- User Experience (UX) Design: Emphasize a user-centric design approach to ensure that your LLM application is intuitive and user-friendly.
- API Integration: If your LLM serves as the backend for a language model, create RESTful APIs or GraphQL endpoints to enable seamless interaction with other software components.
- Scalability and Performance: Design your applications to accommodate varying levels of traffic and demand. Prioritize optimization for performance and scalability to guarantee a smooth user experience.
2. Deploying LLM-Based Applications
You’ve successfully built your LLM application and are prepared to deploy it into a production environment. Here’s what you should take into account:
- Cloud Deployment: Consider deploying your LLM applications on cloud platforms such as AWS, Google Cloud, or Azure to ensure scalability and simplified management.
- Containerization: Utilize containerization technologies like Docker and Kubernetes to package your applications, ensuring consistent deployment across diverse environments.
- Monitoring: Implement a monitoring system to keep track of the performance of your deployed LLM applications and promptly detect and address any issues that may arise.
3. Compliance and Ethical Considerations
Data privacy and ethical concerns are fundamental aspects to keep in mind:
- Data Privacy: Make sure to comply with data privacy regulations when dealing with user data and personally identifiable information (PII).
- Ethical Considerations: Adhere to ethical guidelines when deploying LLM applications to mitigate potential biases, misinformation, or the generation of harmful content.
If you like the article and would like to support me, make sure to:
- 👏 Clap for the story (50 claps) to help this article be featured
- Subscribe to To Data & Beyond Newsletter
- Follow me on Medium
- 📰 View more content on my medium profile
- 🔔 Follow Me: LinkedIn |Youtube | GitHub | Twitter
Subscribe to my newsletter To Data & Beyond to get full and early access to my articles:
Are you looking to start a career in data science and AI and do not know how? I offer data science mentoring sessions and long-term career mentoring:
- Mentoring sessions: https://lnkd.in/dXeg3KPW
- Long-term mentoring: https://lnkd.in/dtdUYBrM
