
Mastering Design Principles for Machine Learning
Applying Software Design Principles to Machine Learning Model Development

Software design principles are general guides for developing clean, readable and maintainable code. Design principles are important because they provide best practices that help ensure that code can be easily understood, reused, scaled and tested. Writing code without incorporating at least some of the known best practices can lead to code that is hard to understand. If code is hard to read that makes it more difficult to explain, modify, and maintain. There are many design principles used for software development. Generally, these principles can be place into three buckets: Clarity, maintainability and collaboration.
In the clarity bucket important concepts include readability, Keep it Simple Stupid (KISS), Don’t Repeat Yourself (DRY) and modularity. In the maintenance bucket we have single responsibility principle (SRP), testability, and error handling. In the collaboration bucket we have Version Control and Documentation. Obviously, these categories have significant overlap. For example, modular code usually adheres to SRP. Despite this, it helps to consider each of these concepts independently.
Clarity
There are many ways to improve code readability, particularly in python. These include descriptive naming, consistent indentation, breaking down complex tasks, minimizing long lines of code, grouping related code, and more. Modularity also helps with code readability and clarity. Modularity involves grouping similar code logic using modules, classes, methods and functions. This also makes code easy to maintain, reuse and share with other developers. Lack of modularity in code can lead to tightly couple functionality which can become very complex. This can make adding new features or debugging difficult or even impossible.
Simplicity, also called the “keep it simple stupid” (KISS) principle, in code involves clear and concise logic that highlight the task being done. This can mean using simpler algorithms or using built-in functions instead of writing them from scratch. It can also mean writing fewer lines of code to perform a task. Finally, DRY is pretty self explanatory. Duplicate logic in code can be very confusing and make code maintenance more difficult. For this reason it is good practice to avoid duplicate logic in code.
Maintainability
The Single Responsibility Principle (SRP) states that every class, function or module should have a single task associated with it. This further reinforces code clarity and makes code much easier to maintain. For example, changing a function that does one thing is much easier than changing a function that does ten things. SRP also aids with testability, which includes writing code that is easy to debug, update, maintain. It is also modular and loosely coupled, meaning that the modular parts are independent from each other. Testable code also makes it easier to collaborate with other developers. Further, writing code that performs appropriate error handling also makes code easier to debug and maintain.
Collaboration
Version control of code involves managing and tracking changes made to code over time. It is important for documenting changes in code, collaborating with other developers who have also made changes, reverting back to previous versions when necessary and more. Finally, documentation is a very important part of code collaboration. Good documentation of code makes it easier for people to understand the logic being used in code, which makes the code easier to maintain, read and share.
In this post, we will cover how to implement these best practice when writing code for machine learning model development. For our purposes we will be working with the Synthetic Credit Card Transaction data available on DataFabrica. The data contains synthetic credit card transaction amounts, credit card information, transaction IDs and more. The free tier is free to download, modify, and share under the Apache 2.0 license.
Getting Started
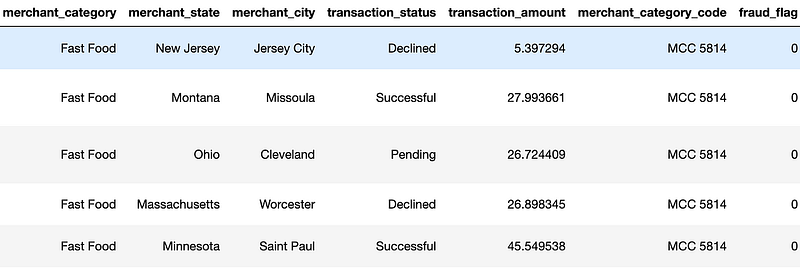
To start let’s read our data into a pandas dataframe and display the first five rows of data:
df = pd.read_csv("synthetic_transaction_data_Dining.csv")
print(df.head())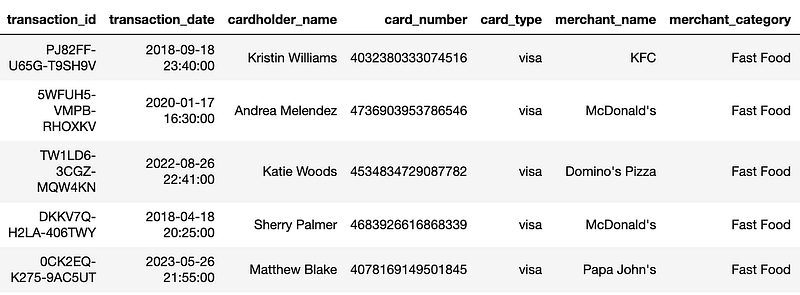
Clarity in Machine Learning Code
Readability
Let’s build a Catboost fraud classifier with our credit card transaction data. Here we will walk through an example of poorly written code that reads in the data, splits the data for training and testing and evaluates model performance.
First let’s import the packages:
import pandas as p
import catboost as cb
from sklearn.model_selection import train_test_split as tts
from sklearn.metrics import classification_report as crNext let’s read in our data set, d, and define our feature, ‘f’, and target, ‘t’:
d=p.read_csv('dining/synthetic_transaction_data_Dining.csv')
f=['cardholder_name', 'card_number', 'card_type', 'merchant_name', 'merchant_category',
'merchant_state', 'merchant_city', 'transaction_amount', 'merchant_category_code']
t='fraud_flag'Next we will use train test split, ‘tts’, to split our data for training and testing:
X_t,X_ts,y_t,y_ts=tts(d[f],d[t],test_size=0.2,random_state=42)We can then define our Catboost model, generate predictions and evaluate performance:
cf = ['cardholder_name', 'card_number', 'card_type', 'merchant_name', 'merchant_category',
'merchant_state', 'merchant_city', 'merchant_category_code']
m=cb.CatBoostClassifier(iterations=10, cat_features=cf)
m.fit(X_t,y_t)
p= m.predict(X_ts)
print(cr(y_ts,p))The full code is as follows:
import pandas as p
import catboost as cb
from sklearn.model_selection import train_test_split as tts
from sklearn.metrics import classification_report as cr
d=p.read_csv('dining/synthetic_transaction_data_Dining.csv')
f=['cardholder_name', 'card_number', 'card_type', 'merchant_name', 'merchant_category',
'merchant_state', 'merchant_city', 'transaction_amount', 'merchant_category_code']
t='fraud_flag'
cf = ['cardholder_name', 'card_number', 'card_type', 'merchant_name', 'merchant_category',
'merchant_state', 'merchant_city', 'merchant_category_code']
X_t,X_ts,y_t,y_ts=tts(d[f],d[t],test_size=0.2,random_state=42)
m=cb.CatBoostClassifier(iterations=10, cat_features=cf)
m.fit(X_t,y_t)
p= m.predict(X_ts)
print(cr(y_ts,p))This code lacks readability due to vaguely renamed imported packages and poor variable naming. Let’s improve this. Let’s import packages and leave the package names as is:
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.metrics import classification_report
from catboost import CatBoostClassifierNow let’s read in data, define inputs/output and split for training and testing with clear variable names:
data = pd.read_csv('dining/synthetic_transaction_data_Dining.csv')
features = ['cardholder_name', 'card_number', 'card_type', 'merchant_name', 'merchant_category',
'merchant_state', 'merchant_city', 'transaction_amount', 'merchant_category_code']
target = 'fraud_flag'
X_train, X_test, y_train, y_test = train_test_split(data[features], data[target], test_size=0.2, random_state=42)And generate predictions and performance calculations, also naming each variable appropriately:
categories = ['cardholder_name', 'card_number', 'card_type', 'merchant_name', 'merchant_category',
'merchant_state', 'merchant_city', 'merchant_category_code']
model = CatBoostClassifier(iterations=10, cat_features=categroies)
model.fit(X_train, y_train)
predictions = model.predict(X_test)
print(classification_report(y_test, predictions))The full code is:
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.metrics import classification_report
from catboost import CatBoostClassifier
data = pd.read_csv('dining/synthetic_transaction_data_Dining.csv')
features = ['cardholder_name', 'card_number', 'card_type', 'merchant_name', 'merchant_category',
'merchant_state', 'merchant_city', 'transaction_amount', 'merchant_category_code']
target = 'fraud_flag'
X_train, X_test, y_train, y_test = train_test_split(data[features], data[target], test_size=0.2, random_state=42)
categories = ['cardholder_name', 'card_number', 'card_type', 'merchant_name', 'merchant_category',
'merchant_state', 'merchant_city', 'merchant_category_code']
model = CatBoostClassifier(iterations=10, cat_features=categories)
model.fit(X_train, y_train)
predictions = model.predict(X_test)
print(classification_report(y_test, predictions))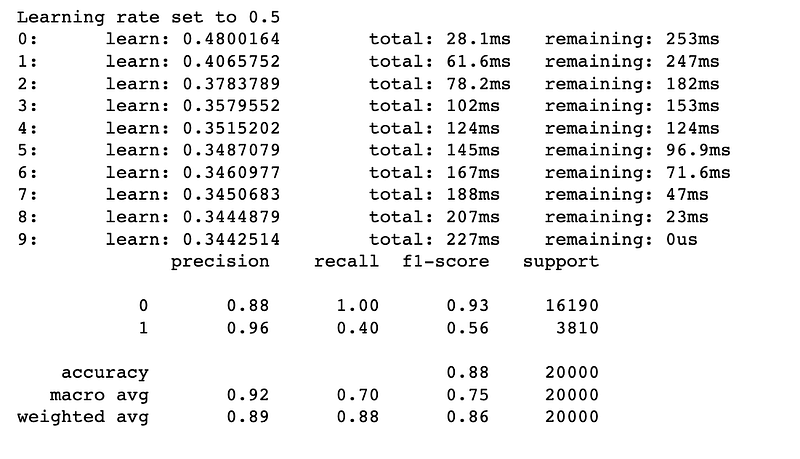
In the above code, package and variable names are clear and easy to understand. The variable names have some information about what information is being stored, which makes the code easier to read.
Keep it Simple Stupid (KISS)
KISS emphasizes simplicity in code development. This means taking aims to ensure solutions to problems are as simple as possible. In the context of machine learning model development this can mean the following:
- Choosing a simple algorithm: Choosing a relatively simple algorithm can be an example of adhering to KISS. For example, opt for a tree-based model instead of a deep neural network
- Selecting a subset of features: Try to limit the number of features used based on EDA and domain expertise. Avoid trying to use every column available as a feature. This can increase model explainability, prevent overfitting and lead to better performance.
- Avoiding over-parameterization: Limit computationally intensive hyper-parameter tuning. Oftentimes, default parameters are good enough for a performant model. Further, if you choose to tune hyper-parameters make sure you understand the implications of tuning each hyperparameter. Use domain expertise and experimentation to select a subset of the most crucial hyper-parameters you wish to tune.
Let’s expand upon this with code that violates KISS. We will build a neural network credit card fraud classifier. Let’s start by importing necessary packages:
import pandas as pd
import numpy as np
from sklearn.model_selection import train_test_split, GridSearchCV
from sklearn.preprocessing import MinMaxScaler
from sklearn.metrics import accuracy_score, precision_score, confusion_matrix
import tensorflow as tf
import plotly.graph_objects as goNext we read in the data, define input/output, encode categorical features, and split data for training and testing:
data = pd.read_csv('dining/synthetic_transaction_data_Dining.csv')
input_features = ['cardholder_name', 'card_number', 'card_type', 'merchant_name', 'merchant_category',
'merchant_state', 'merchant_city', 'transaction_amount', 'merchant_category_code']
output_variable = 'fraud_flag'
for feature in input_features:
if data[feature].dtype == 'object':
data[feature] = data[feature].astype('category').cat.codes
X = data[input_features]
y = data[output_variable]
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)Next we’ll perform some data transformations:
X_train['transaction_amount'] = np.log1p(X_train['transaction_amount'])
X_test['transaction_amount'] = np.log1p(X_test['transaction_amount'])
scaler = MinMaxScaler()
X_train_scaled = scaler.fit_transform(X_train)
X_test_scaled = scaler.transform(X_test)Define a function that specifies our neural network architecture. Here, we’ve deliberately made it unnecessarily complex:
def build_model():
model = tf.keras.models.Sequential()
model.add(tf.keras.layers.Dense(5, activation='relu', input_shape=(len(input_features),)))
model.add(tf.keras.layers.Dense(5, activation='relu'))
model.add(tf.keras.layers.Dense(5, activation='relu'))
model.add(tf.keras.layers.Dense(5, activation='relu'))
model.add(tf.keras.layers.Dense(5, activation='relu'))
model.add(tf.keras.layers.Dense(1, activation='sigmoid'))
model.compile(optimizer='adam', loss='binary_crossentropy', metrics=['accuracy'])
return modelPerform a grid search to find the best model:
# Create the model
model = tf.keras.wrappers.scikit_learn.KerasClassifier(build_model)
# Define the hyperparameter grid for grid search
param_grid = {
'epochs': [10, 20],
'batch_size': [32, 64],
}
# Perform grid search for hyperparameter tuning
grid_search = GridSearchCV(model, param_grid=param_grid, cv=3)
grid_search.fit(X_train_scaled, y_train)
# Get the best model
best_model = grid_search.best_estimator_We can then generate predictions, calculate accuracy, calculate precision and generate a confusion matrix:
y_pred = best_model.predict(X_test_scaled) accuracy = accuracy_score(y_test, y_pred) precision = precision_score(y_test, y_pred) confusion_mat = confusion_matrix(y_test, y_pred)
And visualize our confusion matrix:
# Define labels
labels = ['Not Fraud', 'Fraud']
# Plot the confusion matrix heatmap
sns.heatmap(confusion_mat, annot=True, fmt="d", cmap="YlGnBu", xticklabels=labels, yticklabels=labels)
# Set axis labels and title
plt.xlabel('Predicted')
plt.ylabel('True')
plt.title('Confusion Matrix')
# Display the plot
plt.show()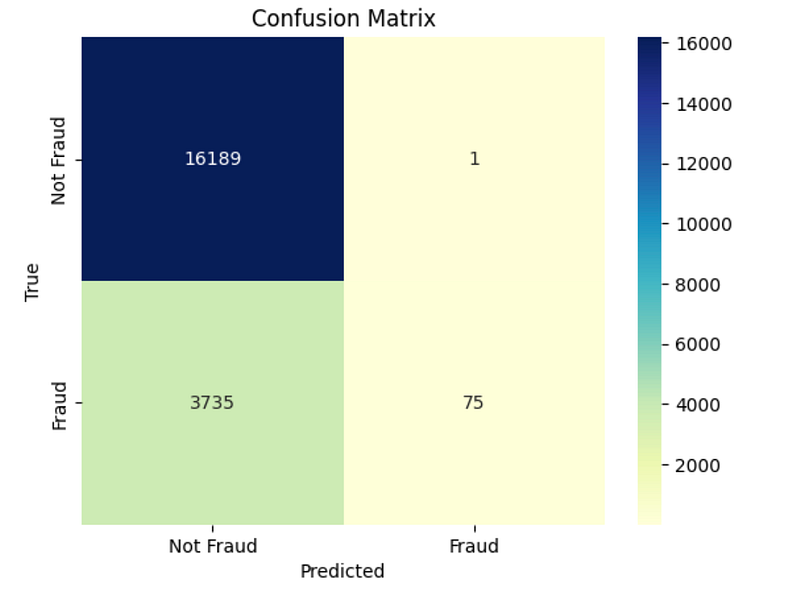
There are many ways that this code can be simplified with KISS principles. First, let’s choose a more simple algorithm. We can use a Catboost model (or any tree based model) instead of a neural network. Catboost is also nice because you can pass in categorical columns directly without having to encode them, which makes the code more simple. Let’s import necessary packages:
import pandas as pd
import numpy as np
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score, precision_score, confusion_matrix
import seaborn as sns
import matplotlib.pyplot as plt
from catboost import CatBoostClassifier, PoolPrepare data for training:
data = pd.read_csv('dining/synthetic_transaction_data_Dining.csv')
input_features = ['cardholder_name', 'card_number', 'card_type', 'merchant_name',
'merchant_category', 'merchant_state', 'merchant_city',
'transaction_amount', 'merchant_category_code']
categories = ['cardholder_name', 'card_number', 'card_type', 'merchant_name',
'merchant_category', 'merchant_state', 'merchant_city'
, 'merchant_category_code']
output_variable = 'fraud_flag'
X_train, X_test, y_train, y_test = train_test_split(data[input_features], data[output_variable], test_size=0.2, random_state=42)Since we’ve chosen a Catboost model we no longer need to encode categories and scale the data which simplifies our code.
Next, let’s perform feature selection using our training data. Catboost allows us to easily use our training data for feature selection, which would be much more complicated to do with a neural network:
model = CatBoostClassifier(iterations=60, depth=6, learning_rate=0.1, random_state=42, verbose=0)
train_pool = Pool(X_train, y_train, cat_features=cats)
model.fit(train_pool)
importance = model.get_feature_importance(train_pool)
feature_importance_df = pd.DataFrame({'Feature': input_features, 'Importance': importance})
selected_features = feature_importance_df[feature_importance_df['Importance'] > 0].sort_values(by='Importance')['Feature'].tolist()
X_train_selected = X_train[selected_features]
X_test_selected = X_test[selected_features]We can then train our model on the selected features and generate feature importance:
selected_categories = [x for x in selected_features if x!= 'transaction_amount']
model = CatBoostClassifier(iterations=60, depth=6, learning_rate=0.1, cat_features=selected_categories, random_state=42, verbose=0)
model.fit(X_train_selected, y_train)
y_pred = model.predict(X_test_selected)
importance = model.get_feature_importance(train_pool)
feature_importance_df = pd.DataFrame({'Feature': selected_features, 'Importance': importance})And we can calculate performance, visualize our confusion matrix and visualize feature importance:
accuracy = accuracy_score(y_test, y_pred)
precision = precision_score(y_test, y_pred)
confusion_mat = confusion_matrix(y_test, y_pred)
sns.heatmap(confusion_mat, annot=True, fmt="d", cmap="YlGnBu")
plt.xlabel('Predicted')
plt.ylabel('True')
plt.title('Confusion Matrix')
plt.show()
feature_importance_df = feature_importance_df.sort_values(by='Importance', ascending=False)
sns.barplot(x='Importance', y='Feature', data=feature_importance_df)
plt.xlabel('Importance')
plt.ylabel('Feature')
plt.title('Feature Importance')
plt.show()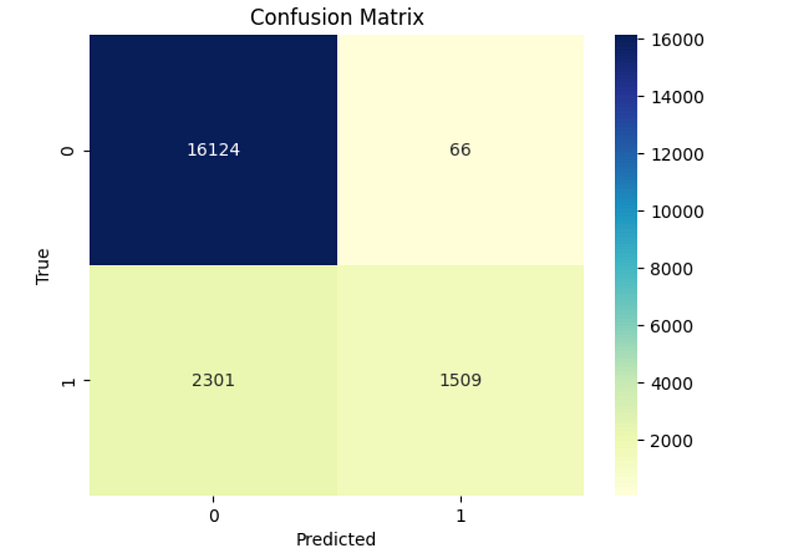
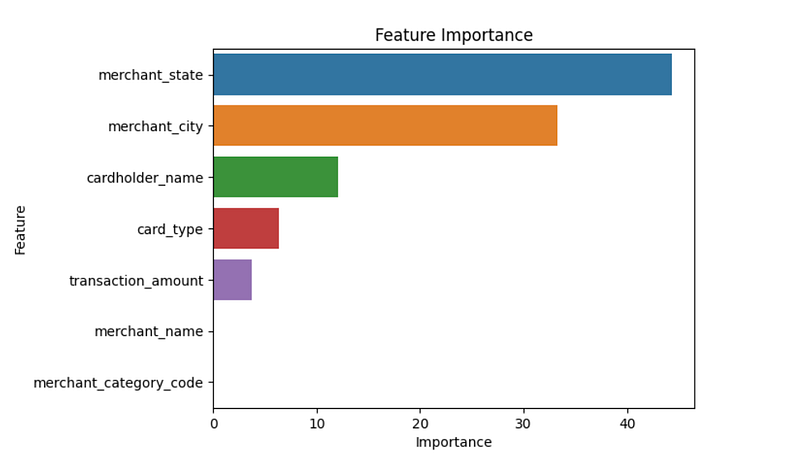
We see that our model does a better job at capturing true fraud cases even though it is a simpler algorithm that uses fewer data transformations and features. This is what KISS is all about!
Don’t Repeat Yourself (DRY) & Modularity
Both DRY and code modularity emphasize limiting code duplication. DRY focuses more on extracting common functionality to define reusable components. Similarly, modularity focuses on organizing code such that complex tasks are broken down into simple independent components. Both can be used to guide code refactoring. Consider the following code:
import pandas as pd
import catboost
data = pd.read_csv('dining/synthetic_transaction_data_Dining.csv')
input_features1 = ['merchant_category_code', 'merchant_name', 'transaction_amount', 'card_type', 'cardholder_name', 'merchant_state', 'merchant_city']
input_features2 = ['merchant_category_code', 'merchant_name', 'transaction_amount', ]
output_variable = 'fraud_flag'
categories1 = [x for x in input_features1 if x!='transaction_amount']
categories2 = [x for x in input_features2 if x!='transaction_amount']
X_train = data.sample(frac=0.8, random_state=42)
y_train = X_train[output_variable]
X_train = X_train[input_features1]
X_test = data.drop(X_train.index)
y_test = X_test[output_variable]
X_test = X_test[input_features1]
model1 = catboost.CatBoostClassifier(iterations = 5, cat_features=categories1, random_state=42)
model1.fit(X_train, y_train)
y_pred1 = model1.predict(X_test)
X_train = data.sample(frac=0.8, random_state=42)
y_train = X_train[output_variable]
X_train = X_train[input_features2]
X_test = data.drop(X_train.index)
y_test = X_test[output_variable]
X_test = X_test[input_features2]
model2 = catboost.CatBoostClassifier(iterations = 100, cat_features=categories2, random_state=42)
model2.fit(X_train, y_train)
y_pred2 = model2.predict(X_test)
accuracy1 = (y_pred1 == y_test).mean()
print("Accuracy1:", accuracy1)
accuracy2 = (y_pred2 == y_test).mean()
print("Accuracy2:", accuracy2)This code violates DRY in a few ways. The input definitions, model definition and training, and model accuracy calculations are all duplicated. This code can be refactored with functions to remove duplicate logic as follows:
import pandas as pd
import catboost
data = pd.read_csv('dining/synthetic_transaction_data_Dining.csv')
def train_model(X_train, y_train, categories, iterations):
model = catboost.CatBoostClassifier(iterations=iterations, cat_features=categories, random_state=42)
model.fit(X_train, y_train)
return model
def evaluate_model(model, X_test, y_test):
y_pred = model.predict(X_test)
accuracy = (y_pred == y_test).mean()
return accuracy
def split_data(data, input_features, output_variable):
X_train = data.sample(frac=0.8, random_state=42)
y_train = X_train[output_variable]
X_train = X_train[input_features]
X_test = data.drop(X_train.index)
y_test = X_test[output_variable]
X_test = X_test[input_features]
return X_train, X_test, y_train, y_test
input_features1 = ['merchant_category_code', 'merchant_name', 'transaction_amount', 'card_type', 'cardholder_name', 'merchant_state', 'merchant_city']
input_features2 = ['merchant_category_code', 'merchant_name', 'transaction_amount']
output_variable = 'fraud_flag'
categories1 = [x for x in input_features1 if x != 'transaction_amount']
categories2 = [x for x in input_features2 if x != 'transaction_amount']
X_train, X_test, y_train, y_test = split_data(data, input_features1, output_variable)
model1 = train_model(X_train, y_train, categories1, iterations=5)
accuracy1 = evaluate_model(model1, X_test, y_test)
print("Accuracy1:", accuracy1)
X_train, X_test, y_train, y_test = split_data(data, input_features2, output_variable)
model2 = train_model(X_train, y_train, categories2, iterations=100)
accuracy2 = evaluate_model(model2, X_test, y_test)
print("Accuracy2:", accuracy2)Both perform identical tasks. The latter is easier to read, debug and maintain. You can further increase modularity by grouping similar code logic into separate files!
Maintainability
Single Responsibility Principle(SRP) states that each module, classes, method or function should have a single responsibility. Our Modular version of this code adheres pretty well to this principle.
Testability
Testability is the extent to which our code can be tested and validated to ensure performance and correctness. We can make our code more testable by adding a main function to the modular version of our earlier code:
import pandas as pd
import catboost
def train_model(X_train, y_train, categories, iterations):
model = catboost.CatBoostClassifier(iterations=iterations, cat_features=categories, random_state=42)
model.fit(X_train, y_train)
return model
def evaluate_model(model, X_test, y_test):
y_pred = model.predict(X_test)
accuracy = (y_pred == y_test).mean()
return accuracy
def split_data(data, input_features, output_variable):
X_train = data.sample(frac=0.8, random_state=42)
y_train = X_train[output_variable]
X_train = X_train[input_features]
X_test = data.drop(X_train.index)
y_test = X_test[output_variable]
X_test = X_test[input_features]
return X_train, X_test, y_train, y_test
def main():
data = pd.read_csv('dining/synthetic_transaction_data_Dining.csv')
input_features1 = ['merchant_category_code', 'merchant_name', 'transaction_amount', 'card_type', 'cardholder_name', 'merchant_state', 'merchant_city']
input_features2 = ['merchant_category_code', 'merchant_name', 'transaction_amount']
output_variable = 'fraud_flag'
categories1 = [x for x in input_features1 if x != 'transaction_amount']
categories2 = [x for x in input_features2 if x != 'transaction_amount']
X_train, X_test, y_train, y_test = split_data(data, input_features1, output_variable)
model1 = train_model(X_train, y_train, categories1, iterations=5)
accuracy1 = evaluate_model(model1, X_test, y_test)
print("Model 1 Accuracy:", accuracy1)
X_train, X_test, y_train, y_test = split_data(data, input_features2, output_variable)
model2 = train_model(X_train, y_train, categories2, iterations=100)
accuracy2 = evaluate_model(model2, X_test, y_test)
print("Model 2 Accuracy:", accuracy2)
if __name__ == "__main__":
main()Error handling
Error handling is also important for maintainability. It works to catch and handle errors to prevent program crashes. We can add erorr handling to our code as well:
import pandas as pd
import catboost
def train_model(X_train, y_train, categories, iterations):
try:
model = catboost.CatBoostClassifier(iterations=iterations, cat_features=categories, random_state=42)
model.fit(X_train, y_train)
return model
except Exception as e:
print(f"An error occurred while training the model: {e}")
def evaluate_model(model, X_test, y_test):
try:
y_pred = model.predict(X_test)
accuracy = (y_pred == y_test).mean()
return accuracy
except Exception as e:
print(f"An error occurred while evaluating the model: {e}")
def split_data(data, input_features, output_variable):
try:
X_train = data.sample(frac=0.8, random_state=42)
y_train = X_train[output_variable]
X_train = X_train[input_features]
X_test = data.drop(X_train.index)
y_test = X_test[output_variable]
X_test = X_test[input_features]
return X_train, X_test, y_train, y_test
except Exception as e:
print(f"An error occurred while splitting the data: {e}")
def main():
try:
data = pd.read_csv('dining/synthetic_transaction_data_Dining.csv')
except Exception as e:
print(f"An error occurred while reading the data: {e}")
return
input_features1 = ['merchant_category_code', 'merchant_name', 'transaction_amount', 'card_type', 'cardholder_name', 'merchant_state', 'merchant_city']
input_features2 = ['merchant_category_code', 'merchant_name', 'transaction_amount']
output_variable = 'fraud_flag'
categories1 = [x for x in input_features1 if x != 'transaction_amount']
categories2 = [x for x in input_features2 if x != 'transaction_amount']
try:
X_train, X_test, y_train, y_test = split_data(data, input_features1, output_variable)
except Exception as e:
print(f"An error occurred while splitting data for Model 1: {e}")
return
try:
model1 = train_model(X_train, y_train, categories1, iterations=5)
accuracy1 = evaluate_model(model1, X_test, y_test)
print("Model 1 Accuracy:", accuracy1)
except Exception as e:
print(f"An error occurred while training or evaluating Model 1: {e}")
return
try:
X_train, X_test, y_train, y_test = split_data(data, input_features2, output_variable)
except Exception as e:
print(f"An error occurred while splitting data for Model 2: {e}")
return
try:
model2 = train_model(X_train, y_train, categories2, iterations=100)
accuracy2 = evaluate_model(model2, X_test, y_test)
print("Model 2 Accuracy:", accuracy2)
except Exception as e:
print(f"An error occurred while training or evaluating Model 2: {e}")
return
if __name__ == "__main__":
main()Collaboration: Version Control and Documentation
Version control is one of the most important aspects of software development. It ensures that code changes are tracked overtime which provides a history of bug fixes, feature enhancements, feature additions, and other modifications. Consider our DRY/Modularity example from earlier. It is conceivable that a data scientist or engineer is assigned the task of refactoring the original code, with the duplicated logic, into the more modular version. It is important to track these types of changes and have access to each code version as changes are made. Some common version control platforms include Git, Subversion and Mercurial.
In addition to version control, documentation is also very important. It is the process of providing information that helps explains code logic. Example of documentation include comments and doc-strings. Code comments are simply within code lines of text that explain lines of codes or code blocks.
A doc-string is a python string literal that provides information about modules, classes, methods and functions. It usually provides information about what the code does, the inputs that are needed, and outputs. Doc-strings make code much easier to read, debug and collaborate.
We add comments and doc-strings to our code below:
import pandas as pd
import catboost
def train_model(X_train, y_train, categories, iterations):
"""
Trains a CatBoostClassifier model.
Args:
X_train (DataFrame): The input features of the training data.
y_train (Series): The target variable of the training data.
categories (list): List of categorical feature names.
iterations (int): The number of iterations for training the model.
Returns:
CatBoostClassifier: The trained CatBoost model.
"""
try:
model = catboost.CatBoostClassifier(iterations=iterations, cat_features=categories, random_state=42)
model.fit(X_train, y_train)
return model
except Exception as e:
print(f"An error occurred while training the model: {e}")
def evaluate_model(model, X_test, y_test):
"""
Evaluates a trained model on test data.
Args:
model (CatBoostClassifier): The trained model to evaluate.
X_test (DataFrame): The input features of the test data.
y_test (Series): The target variable of the test data.
Returns:
float: The accuracy of the model on the test data.
"""
try:
y_pred = model.predict(X_test)
accuracy = (y_pred == y_test).mean()
return accuracy
except Exception as e:
print(f"An error occurred while evaluating the model: {e}")
def split_data(data, input_features, output_variable):
"""
Splits the data into train and test sets.
Args:
data (DataFrame): The input data.
input_features (list): List of input feature names.
output_variable (str): The name of the target variable.
Returns:
DataFrame: X_train - The input features of the training data.
DataFrame: X_test - The input features of the test data.
Series: y_train - The target variable of the training data.
Series: y_test - The target variable of the test data.
"""
try:
X_train = data.sample(frac=0.8, random_state=42)
y_train = X_train[output_variable]
X_train = X_train[input_features]
X_test = data.drop(X_train.index)
y_test = X_test[output_variable]
X_test = X_test[input_features]
return X_train, X_test, y_train, y_test
except Exception as e:
print(f"An error occurred while splitting the data: {e}")
def main():
"""
The main function that orchestrates the model training and evaluation.
"""
#read in data
try:
data = pd.read_csv('dining/synthetic_transaction_data_Dining.csv')
except Exception as e:
print(f"An error occurred while reading the data: {e}")
return
#define input features
input_features1 = ['merchant_category_code', 'merchant_name', 'transaction_amount', 'card_type', 'cardholder_name', 'merchant_state', 'merchant_city']
input_features2 = ['merchant_category_code', 'merchant_name', 'transaction_amount']
output_variable = 'fraud_flag'
#define categories
categories1 = [x for x in input_features1 if x != 'transaction_amount']
categories2 = [x for x in input_features2 if x != 'transaction_amount']
#try splitting data
try:
X_train, X_test, y_train, y_test = split_data(data, input_features1, output_variable)
except Exception as e:
print(f"An error occurred while splitting data for Model 1: {e}")
return
#try training first model
try:
model1 = train_model(X_train, y_train, categories1, iterations=5)
accuracy1 = evaluate_model(model1, X_test, y_test)
print("Model 1 Accuracy:", accuracy1)
except Exception as e:
print(f"An error occurred while training or evaluating Model 1: {e}")
return
#try splitting second set of features
try:
X_train, X_test, y_train, y_test = split_data(data, input_features2, output_variable)
except Exception as e:
print(f"An error occurred while splitting data for Model 2: {e}")
return
#try training second model
try:
model2 = train_model(X_train, y_train, categories2, iterations=100)
accuracy2 = evaluate_model(model2, X_test, y_test)
print("Model 2 Accuracy:", accuracy2)
except Exception as e:
print(f"An error occurred while training or evaluating Model 2: {e}")
return
if __name__ == "__main__":
main()The code used in this post is available on GitHub.
Conclusion
In this post we discussed some software design principles that can aid with code readability, maintainability, and collaboration when developing machine learning models. We discussed code clarity, maintainability and collaboration. Regarding clarity we discussed clear variable naming, KISS, DRY, and modularity. All of these help to make code more clear to engineers and data scientist. Under maintainability we discussed SRP, testability, and error handling which makes code much easier to maintain overtime. Finally we discussed collaboration with version control and documentation. By leveraging these principles, data scientists and engineers can collaborate more effectively together.
A free sample of the data used in this article is available here. The full data set can be found here.
Subscribe to DDIntel Here.
Visit our website here: https://www.datadriveninvestor.com
Join our network here: https://datadriveninvestor.com/collaborate