
Mastering Chess with Deep Learning: A Monte Carlo Tree Search and PPO Loss Approach
I. Introduction
A. Brief overview of the project
In this article, I present an innovative Deep Learning network designed to play chess with exceptional skill. By leveraging the power of advanced artificial intelligence techniques, this project aims to push the boundaries of what is possible in the realm of chess engines. At the heart of this network lies a unique combination of Monte Carlo Tree Search and Proximal Policy Optimization (PPO) loss, which allows the system to learn and adapt its strategies to achieve superior performance.
B. Connection to chess as a classic testbed for AI
Chess has long been regarded as the ultimate intellectual battleground and an ideal testbed for artificial intelligence. Since the dawn of the computer age, researchers have been fascinated with the idea of creating a machine capable of defeating human chess masters. Over the years, chess engines have evolved from simple rule-based systems to sophisticated algorithms that can challenge even the world’s best players.
C. The role of deep learning in modern chess engines
With the recent advancements in deep learning and artificial intelligence, modern chess engines have undergone a significant transformation. Deep learning has enabled these engines to not only analyze millions of potential moves but also to recognize and learn from patterns in the data. This has led to the development of AI-powered chess systems that can understand and adapt their strategies to a wide variety of game situations, allowing them to compete at the highest levels of the sport.
D. Introducing the unique combination of Monte Carlo Tree Search and PPO loss
In this project, I explore a novel approach to creating a powerful chess engine by combining two cutting-edge AI techniques: Monte Carlo Tree Search (MCTS) and Proximal Policy Optimization (PPO) loss. MCTS is a powerful search algorithm that excels at exploring possible game states, while PPO loss is a key tool in reinforcement learning that helps improve decision-making by optimizing the AI’s actions. By harnessing the strengths of these two techniques, our Deep Learning network is able to process and evaluate a vast array of chess moves, effectively adapting its strategy in real-time to outmaneuver opponents and secure victory.
II. Background
A. A brief history of chess engines and AI
Chess engines have come a long way since their inception in the mid-20th century. Early engines relied on brute force search algorithms and hand-crafted evaluation functions to select moves. The advent of more powerful hardware and better algorithms in the late 20th century led to increasingly sophisticated chess engines, such as Deep Blue, which famously defeated World Chess Champion Garry Kasparov in 1997.
B. The rise of deep learning in gaming
In recent years, deep learning has revolutionized the field of artificial intelligence, particularly in the domain of gaming. The success of deep learning models, such as DeepMind’s AlphaGo, demonstrated that AI could not only excel at board games like Go but also surpass human experts. This breakthrough has paved the way for the adoption of deep learning techniques in various gaming applications, including chess engines.
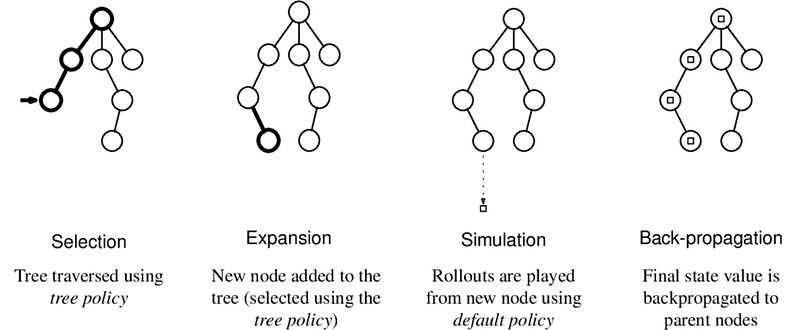
C. Monte Carlo Tree Search: a popular technique for game AI
Monte Carlo Tree Search (MCTS) is a popular search algorithm used in game AI, known for its ability to balance exploration and exploitation effectively. By simulating thousands of random game trajectories, MCTS constructs a search tree that helps guide the AI towards promising moves. The algorithm has been successfully applied to various games, such as Go and poker, and has become a vital component of modern game-playing AI systems.
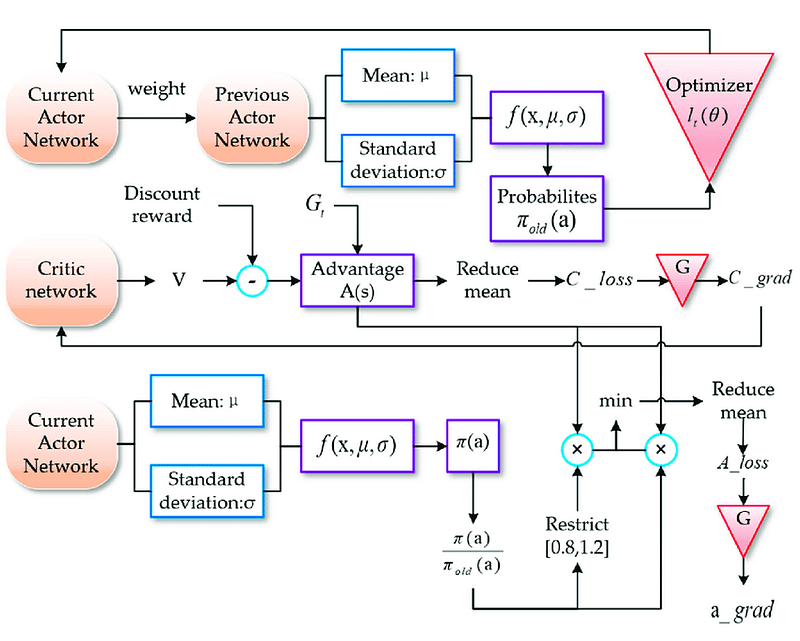
D. Proximal Policy Optimization (PPO) loss: an essential tool for reinforcement learning
Proximal Policy Optimization (PPO) is a popular reinforcement learning algorithm that improves decision-making in AI systems by iteratively updating the agent’s policy. PPO loss is the objective function used to optimize the policy, ensuring that it does not deviate too far from the previous iteration, which aids in stability and faster convergence. PPO has been widely adopted in various AI applications, including robotics and game-playing agents, due to its ability to efficiently learn complex strategies.
IV. Training and Optimization
A. Data sources and training methodology
In order to train our deep learning chess engine, I have utilized a self-play approach, where the model competes against itself to generate training data. This method allows the AI to learn from its own mistakes and successes, creating a feedback loop that drives continuous improvement. Starting from random play, the model gradually refines its understanding of chess strategies and tactics, eventually reaching a high level of performance.
B. Hyperparameter tuning and optimization
Hyperparameter tuning plays a crucial role in training our chess engine, as it influences the model’s ability to learn and generalize effectively. I have employed a combination of manual tuning and automated optimization techniques, such as grid search and Bayesian optimization, to find the optimal set of hyperparameters for our deep learning model, MCTS, and PPO loss components.
C. Balancing exploration and exploitation
One of the key challenges in training a game-playing AI is balancing exploration (trying new moves) and exploitation (playing moves it already knows to be strong). MCTS inherently manages this balance by exploring promising branches in the search tree while exploiting the accumulated knowledge. However, during the training process, I have also introduced additional mechanisms, such as temperature scaling, to encourage the model to explore a diverse set of strategies, avoiding overfitting to a narrow range of tactics.
V. Next Steps
A. Ensuring robustness against a variety of opponents
As our chess engine is trained through self-play, it is crucial to ensure that the model can generalize well and adapt to different play styles. To achieve this, I will periodically evaluate the model against various traditional chess engines and human-like opponents, adjusting the training process as needed to address any discovered weaknesses. This iterative evaluation and refinement process will lead to a more robust AI player that can successfully compete against a wide range of adversaries.
B. Integrating a model trained on historic GM games
While the idea of a model trained purely on self play remains my platonic ideal, it is unfortunately beyond the reasonable capability of my access to GPUs. To further enhance the model’s understanding of chess strategies, I could integrate a supplementary model trained on a dataset of historic grandmaster games. This would expose the AI to the wealth of human chess knowledge, allowing it to learn from the masters and potentially uncover new insights.
C. Continue tuning the reward network
Improving the reward network’s ability to accurately evaluate positions and guide the model’s learning process is essential for ongoing performance improvements. By refining the reward function, we can further enhance the model’s decision-making capabilities and its ability to adapt to novel game situations.
VI. Conclusion
A. Recap of the project’s scope and aim
In this article, I have presented a deep learning chess engine that combines the power of Monte Carlo Tree Search and Proximal Policy Optimization loss. Our aim was to create a robust and adaptive AI player, capable of discovering and experimenting with novel strategies while learning from its own self-play. Through this project, we have demonstrated the potential of advanced AI techniques in the domain of chess and game-playing AI in general.
B. Leela, Maia, and other similar examples of more developed chess AI’s
Our work builds upon the foundations laid by other notable deep learning-based chess engines, such as Leela Chess Zero (LCZero) and Maia. These AI players have shown remarkable capabilities, significantly contributing to the advancement of chess AI. By exploring novel combinations of AI techniques, I hope to contribute to this growing body of knowledge and inspire further innovations in the field while playing catch up with the giants who’s shoulders I stand on.
VII. Call to Action
A. Encouragement for feedback and collaboration
I encourage the chess and AI community to explore our project, provide feedback, and engage in collaborative efforts. Your insights and contributions will be invaluable in refining and expanding our deep learning chess engine, enabling us to push the boundaries of AI-powered game-play even further.
B. Invitation to connect and discuss further applications and ideas
I invite you to connect with us on LinkedIn or through email to discuss the project, share ideas, and explore potential applications and extensions of our work. I am excited to engage with like-minded individuals and groups who are passionate about advancing the fields of chess and artificial intelligence.