
Mastering Association Rule Learning: Pros and Cons of Apriori, Eclat, and FP-growth
Association rule learning is an essential task in data mining and machine learning, and it aims to discover interesting relationships between different items in a dataset. The three popular algorithms for association rule learning are Apriori, Eclat, and FP-growth. In this post, we will explore the pros and cons of each of these algorithms to help you understand which one is suitable for your specific use case.
Apriori Algorithm for Association Rule Learning
The Apriori algorithm is used to find frequent itemsets in a given dataset. The algorithm uses the concept of support and confidence to determine the frequent itemsets. The support is the number of times an itemset appears in a dataset, and the confidence is the conditional probability of having the consequent given the antecedent.
The algorithm generates a set of frequent itemsets from the dataset and then uses them to generate association rules. These association rules can be used to identify patterns in the data. The algorithm consists of two main steps:
- Generating frequent itemsets: In this step, the algorithm scans the dataset to find the frequent itemsets that satisfy the minimum support threshold. The support threshold is set by the user and is used to determine the minimum number of occurrences required for an itemset to be considered frequent.
- Generating association rules: In this step, the frequent itemsets generated in the previous step are used to generate association rules. The algorithm calculates the confidence for each rule and selects only the rules that satisfy the minimum confidence threshold set by the user.
Here is an example implementation of the Apriori algorithm in Python using the mlxtend library:
from mlxtend.preprocessing import TransactionEncoder
from mlxtend.frequent_patterns import apriori
import pandas as pd
# Create a list of transactions
transactions = [['milk', 'bread', 'butter'],
['beer', 'chips'],
['milk', 'bread', 'beer', 'chips'],
['milk', 'bread', 'butter', 'beer', 'chips'],
['milk', 'bread', 'butter', 'chips']]
te = TransactionEncoder()
te_ary = te.fit(transactions).transform(transactions)
# Create a DataFrame from the encoded data and find frequent itemsets
df = pd.DataFrame(te_ary, columns=te.columns_)
frequent_itemsets = apriori(df, min_support=0.4, use_colnames=True)
print(frequent_itemsets)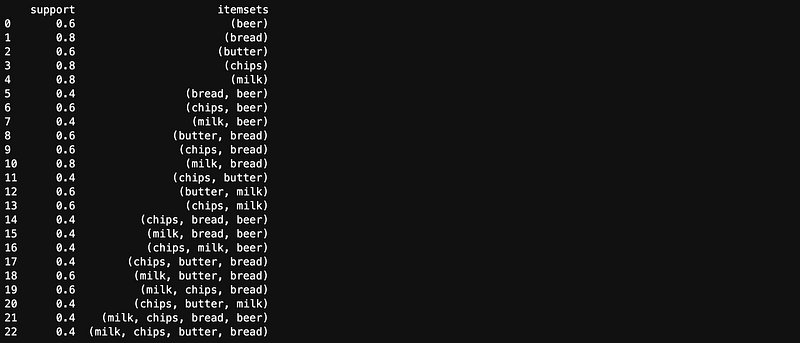
In this example, we create a list of transactions and use the Apriori algorithm to find frequent itemsets with a minimum support threshold of 0.4. The algorithm returns a DataFrame containing the frequent itemsets and their support values.
Eclat Algorithm for Association Rule Learning
Eclat (Equivalence Class Clustering and Bottom-up Lattice Traversal) is a popular association rule learning algorithm that generates itemsets from a transaction database. It works on the vertical format of the transaction data where each row represents a transaction and each column represents an item. The algorithm identifies frequent itemsets using a depth-first search and bit-wise operations.
The Eclat algorithm is based on two main data structures: the tidset and the vertical bitmap. The tidset contains the transaction IDs where an item appears, and the vertical bitmap contains the bit representation of which items are present in each transaction.
The algorithm generates frequent itemsets by recursively exploring the vertical bitmap and the tidsets.
Here is an example code snippet in Python that shows how to implement the Eclat algorithm using the apyori library:
from apyori import apriori
# Sample transaction dataset
dataset = [['Milk', 'Bread', 'Butter'],
['Bread', 'Butter'],
['Milk', 'Bread', 'Jam'],
['Milk', 'Eggs'],
['Bread', 'Eggs']]
# Apriori algorithm
results = list(apriori(dataset, min_support=0.5, max_length=2))
for itemset in results:
print(list(itemset.items), "support:", itemset.support)
The apriori function generates association rules based on the input data with a specified minimum support value.
The resulting results variable is a list of namedtuples that contain information about each frequent itemset, including the support and items that make up the itemset.
FP-growth Algorithm for Association Rule Learning
FP-growth algorithm is a popular algorithm used for mining frequent itemsets in association rule learning. It is an efficient algorithm that works by constructing a tree structure called the FP-tree. The FP-tree represents the frequency of itemsets and their corresponding transactions. The algorithm then scans the tree to find frequent itemsets, which are used to generate association rules.
The FP-growth algorithm has several advantages over the Apriori and Eclat algorithms. It requires less memory and has a faster execution time since it only needs to scan the dataset twice. Also, it can handle datasets with high dimensionality and sparsity, making it suitable for large-scale datasets.
Here is an example code snippet for implementing FP-growth algorithm in Python using the PyFPGrowth library:
from pyfpgrowth import find_frequent_patterns, generate_association_rules
dataset = [['apple', 'banana', 'orange'], ['banana', 'pear'], ['apple', 'banana', 'pear'], ['banana', 'orange']]
patterns = find_frequent_patterns(dataset, 2)
# Generate association rules
rules = generate_association_rules(patterns, 0.5)
print('Frequent Itemsets:', patterns)
print('Association Rules:', rules)
In this example, we define a dataset containing transactions of fruits. We then use the find_frequent_patterns() function to find itemsets that occur at least 2 times in the dataset. We then generate association rules using the generate_association_rules() function with a minimum confidence threshold of 0.5. The results are printed to the console, which includes the frequent itemsets and association rules.
Note: while FP-growth algorithm has many advantages, it may not be suitable for all datasets. The algorithm is sensitive to data distribution and may not perform well with datasets that have low support values or highly skewed data. Additionally, the performance of the algorithm may degrade with larger datasets, so it may not be the best option for very large datasets.
Advantages & Disadvantages
Apriori Algorithm
Pros:
Simple and easy to understand Can handle large datasets effectively Results in a set of frequent itemsets that can be further used for association rule generation
Cons:
Computationally expensive for large datasets due to the generation of candidate itemsets Generates many candidate itemsets, most of which may not be frequent, leading to inefficient performance May not be efficient for datasets with low minimum support threshold
Eclat Algorithm
Pros:
More efficient than Apriori Algorithm due to its vertical approach Handles sparse datasets more effectively than Apriori Generates fewer candidate itemsets, leading to improved performance
Cons:
Limited to binary datasets, i.e., datasets with only 0’s and 1’s May not perform well on datasets with low minimum support threshold Does not generate all frequent itemsets, only the ones that contain a specific item
FP-growth Algorithm
Pros:
Efficient and scalable, particularly for large datasets Generates a compact data structure (FP-tree) that can be used for efficient frequent itemset mining Handles datasets with low minimum support threshold well
Cons:
Can be memory-intensive for large datasets Requires multiple scans of the dataset to generate the FP-tree, which can be time-consuming Not suitable for datasets with a large number of unique items





