
Mastering AdaBoost: An Easy Guide for Beginners
AdaBoost, short for Adaptive Boosting, is a powerful ensemble learning technique used in machine learning. It combines multiple “weak learners” to create a highly accurate prediction model.
This tutorial will break down AdaBoost’s process, using a patient classification example to illustrate its workings.
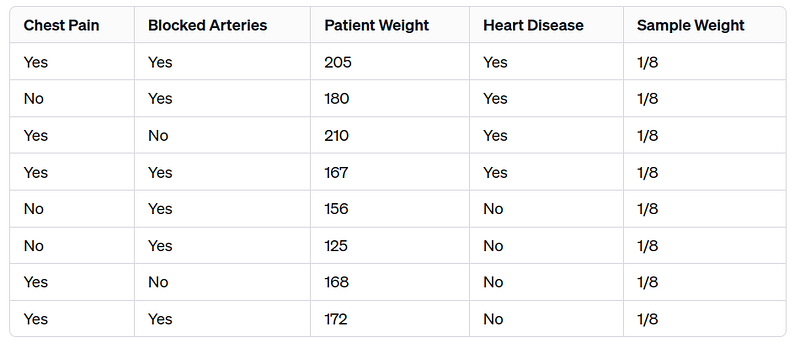
Step 1: Identifying the First Stump
AdaBoost begins by selecting the first “stump” (a decision tree with a single split) using criteria like the Gini index.
The Gini index is a metric used in decision trees and related algorithms to determine the purity of a node. In the context of classification, “purity” refers to how mixed the classes are in a particular node. A Gini index of 0 indicates perfect purity, meaning all cases in the node fall into a single category, while a Gini index of 1 (or 0.5 for a binary classification) indicates the worst case, where classes are evenly distributed.
The Gini index for a binary classification problem, like the heart disease classification depicted in the image, can be calculated with the following formula:
In our example, the most important feature for classification is identified as the “patient weight”.
Step 2: Calculating the Stump’s Influence
The total error (sum of the weights of incorrectly classified samples) helps determine a stump’s influence.
A stump with a small total error has a significant positive impact, while a stump with a high total error (or random performance) has little to no influence.
Step 3: Adjusting Sample Weights
After determining a stump’s impact, AdaBoost adjusts the weights of the samples. Incorrectly classified samples get their weight increased, while correctly classified ones have their weight decreased. This adjustment ensures that subsequent stumps focus more on the previously misclassified samples.
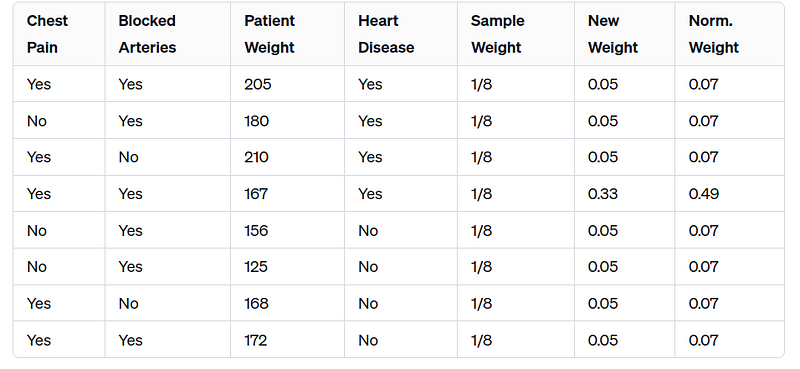
Step 4: Creating Subsequent Stumps
The modified sample weights influence the creation of the next stump in the sequence.
AdaBoost may use a weighted Gini index or create a new sample collection emphasizing the misclassified samples.
The process repeats, with each new stump attempting to correct the mistakes of its predecessors.
Step 5: Classification by the Forest of Stumps
AdaBoost combines the output of all stumps to make a final classification.
Each stump contributes its “say” in the classification, weighted according to its accuracy.
The final decision is made based on the cumulative “say” of all stumps.

Key Concepts of AdaBoost
- Combination of Weak Learners: AdaBoost improves classification accuracy by combining multiple simple decision trees.
- Learning from Mistakes: Each new stump is built considering the errors of previous ones, focusing more on samples that were previously misclassified.
- Adaptability: AdaBoost can utilize available functions like Gini, or adapt by creating new datasets emphasizing certain samples.
AdaBoost is a powerful and adaptive algorithm that can significantly improve classification accuracy in machine learning. By focusing on correcting its mistakes, it builds a robust model that combines the strengths of multiple weak learners.
Please feel free to leave comments specifying the aspects or topics you’d like to see covered in upcoming articles.





