
Marlin: Nearly Ideal Inference Speed for 4-bit Large Language Models
Up to 4x faster than inference with fp16 parameters

Large language models (LLMs) are often too large to be directly used on consumer hardware. To reduce their size, various techniques have been proposed to quantize LLMs and lower their memory consumption. While recent algorithms for 4-bit quantization are often released along with their own optimized CUDA kernels, the inference throughput of quantized LLMs remains far from optimal.
Inference with 4-bit models, for instance using the INT4 data type, involves INT4xFP16 operations which are slow even with modern GPUs, hence the need for optimized CUDA kernels.
The Institute of Science and Technology Austria (ISTA) proposes Mixed Auto-Regressive Linear kernel (Marlin), an extremely optimized INT4xFP16 matmul kernel that can deliver close to ideal (4x) inference speed.
In this article, I explain how Marlin achieves this speedup. Then, we will see how to convert existing GPTQ models into the Marlin format. I use Mistral 7B for demonstration and check the inference speed with vLLM.
Marlin: Maximizing the GPU Usage for INT4 LLMs
As I’m writing this article, Marlin is not described in any paper yet. They have only published an extensive README.md in Marlin’s GitHub repository describing how it works:
- IST-DASLab/marlin (Apache 2.0 license)
GPUs have a balance between their ability to do operations and move data around, typically being able to handle 100–200 times more operations than data transfers. By using 4-bit (INT4) weights, we can theoretically make these operations up to four times faster than using half-precision (FP16) weights.
However, achieving this speedup is quite difficult. It requires making full use of the GPU’s capabilities, including its memory systems and numerous cores, all at the same time. Marlin addresses this challenge with several optimizations.
Among these optimizations, Marlin makes sure that data is efficiently fetched from the GPU’s L2 cache memory and reused as often as possible before being discarded, significantly reducing delays that can occur when data needs to be reloaded.
Another key optimization is the use of double buffering, a technique that allows data to be loaded while computations are simultaneously being performed. It makes sure that the GPU’s workflow remains efficient, with no unnecessary pauses. Moreover, Marlin plans the order in which data is dequantized and computations are executed during inference. This planning, along with a prearrangement of the data to process, guarantees that all parts of the GPU are kept busy.
Marlin also introduces several optimizations to fully exploit multi-GPU settings. It increases the amount of parallel processing without requiring more data to be loaded at once, effectively dividing the workload across GPUs.
All these optimizations result in a nearly optimal use of the GPU resources:
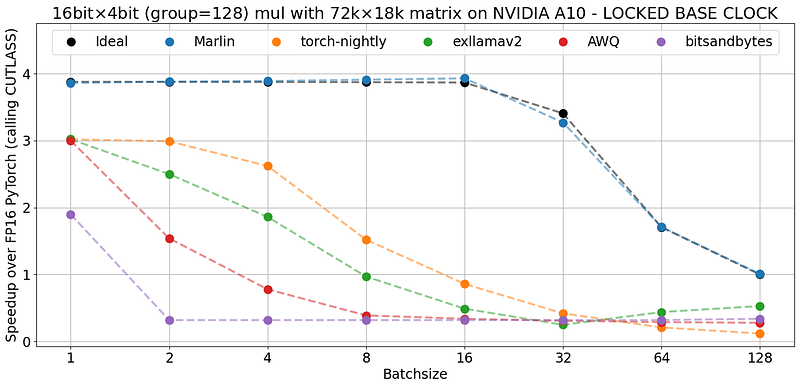
Even for a batch size of 1, Marlin is faster than all existing frameworks, including ExLlamaV2 and AWQ which both already use custom kernels for fast inference.
Even more remarkable, from a batch size of 8, these frameworks are slower than FP16 inference while Marlin remains almost 4x faster.
GPTQ with Marlin for Fast Inference with LLMs
Marlin is already supported by AutoGPTQ (MIT license), one of the most used libraries to quantize LLM with GPTQ. If you want to know how to quantize a model with GPTQ, I wrote about it here:
Note: I also made a notebook implementing all the code described in this section. You can get it here: Get the notebook (#56).
Using Marlin is easy and we don’t need to quantize the model again if it is already quantized. We just need to reformat the model with Marlin.
However, Marlin is only compatible with Ampere and more recent GPUs (RTX 30xx/40xx, A100, …). To test the compatibility of your GPU, run:
import torch
major_version, minor_version = torch.cuda.get_device_capability()
if major_version >= 8:
print("Your GPU supports Marlin!")
else:
print("Your GPU doesn't support Marlin... You need an Ampere GPU or more recent (RTX 30xx/40xx, A100, H100, ...)")Your GPU is compatible? Great, you can proceed with the next steps!
First, install the necessary libraries:
pip install --upgrade transformers auto-gptq accelerate optimum
For demonstration, I used my own GPTQ version of Mistral 7B:
To convert it to Marlin’s format, we load the model with AutoGPTQ while passing the arguments “use_marlin=True”:
from transformers import AutoTokenizer
from auto_gptq import AutoGPTQForCausalLM
GPTQ_MODEL = "kaitchup/Mistral-7B-v0.1-gptq-4bit"
marlin_model = AutoGPTQForCausalLM.from_quantized(
GPTQ_MODEL,
use_marlin=True,
device_map='auto')Note: This conversion slightly reduces the size of the model in most cases.
If it’s working, AutoGPTQ should log the progression of the conversion, as follows:

This conversion is fast, less than a minute on Google Colab with the A100 GPU. Expect a similar speed if you are using an RTX GPU.
We can also save the model in this format to avoid doing this conversion again:
save_dir = "Mistral-7B-v0.1-gptq-marlin-4bit"
marlin_model.save_pretrained(save_dir)
tokenizer.save_pretrained(save_dir)You can find mine on the Hugging Face hub:
1k+ tokens/sec with Mistral 7B Marlin using vLLM
I used vLLM (Apache 2.0 license) to test the inference speed with the Marlin model and compared it with the original GPTQ model (i.e., not converted). I have experimented with batch sizes 1, 2, 4, 8, 16, 32, 64, and 128. As reported by the authors of Marlin, the acceleration brought by Marlin should be significantly better with larger batches.
The code I used for this benchmarking:
import time
from vllm import LLM, SamplingParams
batch_sizes = [1, 2, 4, 8, 16, 32, 64, 128]
p = "You are a helpful, respectful and honest assistant. Always answer as helpfully as possible, while being safe. Your answers should not include any harmful, unethical, racist, sexist, toxic, dangerous, or illegal content. Please ensure that your responses are socially unbiased and positive in nature.\n\nIf a question does not make any sense, or is not factually coherent, explain why instead of answering something not correct. If you don't know the answer to a question, please don't share false information. \n\n Tell me about gravity."
sampling_params = SamplingParams(max_tokens=1000)
loading_start = time.time()
llm = LLM(model="kaitchup/Mistral-7B-v0.1-gptq-4bit")
print("--- Loading time: %s seconds ---" % (time.time() - loading_start))
for b in batch_sizes:
prompts = []
for i in range(b):
prompts.append(p)
generation_time = time.time()
outputs = llm.generate(prompts, sampling_params)
duration = time.time() - generation_time
total_tokens = 0
for output in outputs:
total_tokens += len(output.prompt_token_ids) + len(output.outputs[0].token_ids)
print('\nBatch size: '+str(b))
print("--- Speed: %s tokens/second ---" % (round(total_tokens/duration,2)))The results (log-scale):
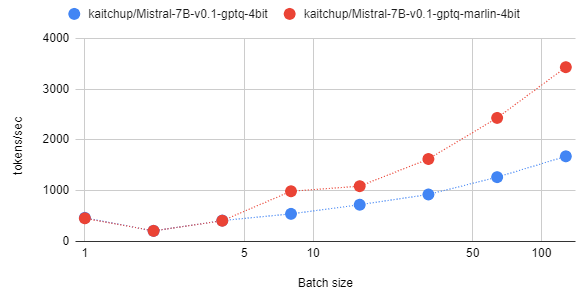
Note: The inference speed can vary a lot between runs. To obtain these numbers, I ran 5 times the decoding for each batch size and computed the average speed.
My main observations:
- It works: Marlin is indeed faster but vLLM only benefits from it for batch sizes larger than 8.
- The gap between Marlin and vanilla GPTQ increases with larger batch sizes.
- (not related to Marlin but interesting) vLLM is already extremely well-optimized for decoding without batching (batch size = 1). Decoding with a batch size of 2 is 2x slower than without batching.
- If you only need small batch sizes, then it might not be worth converting your models to Marlin, yet.
Conclusion
With Marlin, in theory, inference with 4-bit models should be almost 4x faster than inference with fp16 models.
Converting a GPTQ model to Marlin is fast and easy. For various reasons, it might be difficult to get the maximum acceleration claimed by Marlin’s authors. However, with a batch size of 8 or greater, the speedup is significant. I assume it could be even faster for smaller batch sizes with a framework and a GPTQ model better optimized for Marlin, e.g., quantized with different hyperparameters.
If you are using GPTQ models, I can’t see any reason for not using Marlin from now on. The Marlin format should be available soon for other quantization algorithms.
To support my work, consider subscribing to my newsletter for more articles/tutorials on recent advances in AI:





