Marketing Mix Models 102 — the Good, the Bad, and the Ugly
An Introduction to Marketing Mix Models (MMM) (and other Popular Marketing Measurement Approaches) Part 2

Companies spend billions of dollars on advertising every year, which makes the measurement and optimization of marketing activities a crucial quest for marketers. Marketing Mix Modeling (MMM) helps answer this question by providing a top-down view of how marketing activities drive business KPIs. In my other story Marketing Mix Modeling 101, I have introduced what is MMM, MMM data, MMM mental model, and suitable model forms. In this article, I will focus on
- How does MMM compare with some other ways of measuring marketing efficiency?
- What are the challenges when building an MMM and what are the potential solutions?
MMM vs Other Ways of Marketing Measurement
The ultimate goal of marketing is to influence or change consumers’ behaviors. To measure the efficiency of marketing activities is to understand what is the incremental effects on KPIs because of marketing activities. In a perfect world, we would want to have a pair of counterfactuals: what happened for a user who was touched by an ad vs. what would have happened if the same user were not touched by the same ad while holding all else unchanged. However, we aren’t living in parallel universes (or maybe we are, but I am not aware of it.).
No man ever steps in the same river twice. For it’s not the same river and he’s not the same man. — Heraclitus
Although only randomized experimentation is believed to be able to answer causality, we can still rely on other modeling techniques to get close to the incrementality of marketing. A few methodologies help measure marketing incrementality/efficiency: experimentation, Marketing Mix Modeling (MMM), Multitouch Attribution Modeling (MTA), and hybrid approaches — a combination of all or two of the three.
Experimentation
Experimentation is the holy grail of understanding causality. With randomization, it is supposed to be the closest we can get to a real counterfactual. Experimentations and quasi-experimentations are widely used in marketing measurement to test the incrementality of campaigns and channels. The types include user-level tests, geo-level market tests, synthetic control tests, etc.
In a user-level test, users are randomly assigned to control and treatment groups. The treatment group would be exposed to ads, and the control group would not. After the test ends, the analyst can compare the key metrics (e.g. conversion rate) between the two groups, and do statistical testing to see whether the differences observed between treatment and control groups are significant. For instance (with a simplified example), if a company wants to test whether certain promotion works and how much discount is ideal, they can have multiple groups — a control group without promotion at all, treatment group 1 with 10 dollars off promotion, and treatment group 2 with 30 dollars off promotion.
In some cases, a user-level test is not doable, quasi-experimentation methods like market-level tests or synthetic control tests might work. For example, if there is a severe network effect, the treatment would impact both the treatment group and the control group. Like for Uber, if a promotion is only run for certain drivers, it could impact the supply situation on the platform and impact the drivers in the control group. Or if we want to test the efficiency of a billboard, we cannot cover certain people’s eyes and not let them see it. However, we can have the treatment in one city, and not in another city(ies) and use the cities in control to construct a modeled/predicted counterfactual to compare with the observed outcome from the treatment city.
The advantages of using experimentation/quasi-experimentation if done right include:
- it is the most scientific way to truly understand the incrementality of a campaign or a channel.
- it can be flexible in understanding campaign level, channel level, geo level, or overall level of marketing effectiveness and marginality (depending on creative experimentation designs)
- it can provide valuable validation and calibration for other attribution models
- it can bypass some of the problems that are hard to address with the models, such as self-selection bias for paid search channels (more info about this in the later section of this story).
- for channels and campaigns with a very short history but enough volume experimentation can work better than models.
There are also disadvantages:
- Experimentation may not be feasible for many channels. The reason could be the channel does not have enough volume or enough power to get statistically significant results, or the channel does not facilitate experimentation. Quasi-experimentation is also subjective to many external factors that could impact the relationship between the treatment group and its predictors, thus making the test inaccurate.
- Experimentation may only be representative of the market situation and marketing strategy during the test time and provide no forecasting ability for the future. It could also be subjective to seasonality and trend. It’s hard to build a holistic and all-inclusive measuring framework using experimentation results alone for future budget allocation optimization.
- One cannot run an unlimited number of tests in a given time frame, especially for smaller businesses, or when many different treatments need to be tested.
- It is subjective to user data privacy initiatives, such as Apple no IDFA. Without user-level tracking data, it’s hard to attribute conversions to campaigns deterministically, thus no reliable lift results.
MultiTouch Attribution Models (MTA)
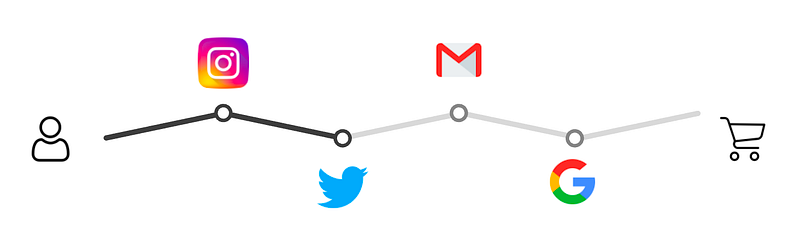
An MTA model aims to attribute a conversion to different channels that touched the user before the conversion. Before a user converts, he/she can be touched by ads on multiple channels. For example, a user might see an Instagram ad and also received an email ad before conversion. How do you attribute the conversion to different ads? How do you determine which ad is incremental in driving the user’s conversion, or neither? MTA models can be helpful.
There are many approaches to building MTA models. There are many popular ways: 1) simple-but-inaccurate rule-based methods, such as equal weight (giving equal credits to all channels), time decay (giving fewer credits to the touch points further away from the conversion at a fixed/dynamic rate), positional (giving more weight to the last and/or first touch channels assuming they bare more weight on a user’s decision, and dividing the rest of the credits to other channels in between)
2) Cooperative Game Theory and Shapley value. In Game Theory, Shapley value is a solution to fairly distribute credits to multiple players (marketing channels) in a coalition (driving conversions).
3) Machine learning models such as logistic regression, tree models, or neural networks.
4) a hybrid of the above
Advantages:
- MTA models are user-level and bottom-up. They can provide more granular and flexible insights by aggregating user-level up to desired granular level and performing cohort level analysis.
- MTA models are typically at the daily level and can enable a more speedy reaction to the market on a daily basis.
- Allows advertisers to drill down to the user journey and understand the nuances and synergy better for specific audience groups and granular strategies.
Disadvantages:
- MTA models can only cover digital media. You cannot attribute a billboard ad touch to a specific user. It wouldn’t work well for a company with large spending on offline media.
- Data used for MTA models can be hard to get. MTA data aims to model the entire user ad journey. However, in reality, the real-world data can be partial and only includes part of the touch points due to tracking difficulty.
- Most MTA methods utilize click data, not impressions, which tends to give more credit to more clicky channels, like search. This can also make the analysis biased.
- Like experimentation, MTA is also subjective to user data privacy initiatives, such as Apple no IDFA and Facebook no AMM. In the foreseeable future, Google will also join the force. Without user-level tracking data, MTA models cannot be built.
- It may not be answering the causality question, since correlation is not the same as causation.
MMM
As mentioned at the beginning of this story and in my MMM 101 story MMM also measures the impact of different marketing channels on KPIs.
Compared to the other two methods/models, MMM is an aggregated top-down model and has the following pros and cons:
Advantages:
- MMM provides a holistic framework to evaluate marketing channels controlling many other factors including seasonality, trend, the economy, etc.
- MMM can generate cost curves that help with budget optimization and allocation.
- MMM not only covers digital channels but also offline media, which provides more coverage than MTA and could be more reliable than a market level test.
- MMM is not subjective to the user data privacy initiatives because it does not require user-level data, which makes it future-proof.
Disadvantages:
- Correlation is not equal to causality. MMM is essentially a regression model. It does not have a counterfactual. Although we can simulate what-if scenarios, it is still not the same as randomized controlled experiments. MMM alone without calibration from experimentation results may be hard to say whether it is causal or not.
- MMM requires relatively large budgets and longer data history to have reliable reads. Sparse data and short data history could make the results biased and unstable.
- MMM tends to underestimate upper funnel channels and overestimate lower funnel channels.
- MMM is an aggregated level, which makes it less flexible and less likely to get more granular level insights, and will not show the nuances of the user journey.
Unified Measurement Framework
All the above have some pros and cons and no one is perfect. We can combine or calibrate one approach with another to harness the benefits from all and avoid problems as much as possible. For example, use experimentation results as priors for MMM and use MTA results to validate and calibrate MMM. A unified approach theoretically should work better than using only one approach but it will require a lot more effort, planning, talents, and budgets, which for many companies may not make sense concerning cost vs gain.
MMM Challenges and Pitfalls
After understanding at a high level where MMM stands in the marketing measurement world, in this section, I will dive deeper into the challenges when building an MMM model, and solutions to some of the challenges. Some of the challenges may not be specific to an MMM model but relevant to general regression.
- data challenges
The most challenging data limitations for MMM include three aspects: availability, sparsity/messiness, and limited range and amount. There is no cure for low-quality data, but there are things we can do to lower the impact on the model. (With that said, garbage in garbage out, the solutions proposed below are only good for data that passes the minimum requirements.)
- Availability: Desired data with good quality can be hard to obtain. For example, many MMM models use media spending as features, however, spending is not perfect because it does not consider media cost. The reach we can have at a cheaper media cost is much more than at a high price for the same level of spending. Impressions, clicks, and GRPs (for TV) could be better features than spending, but the data may not be available or reliable. It is possible to get action-based data from third-party data or try to build better internal data tracking system. Without action-based data, spend data is still sufficient, however, data scientists should pay attention to media cost and address it in the model form and when using model insights.
- Sparsity and messiness: Media data could also be sparse and messy (regardless of using spending as features or not), especially at more granular levels. This is kind of the nature of how marketing budgets work. For example, there can be a big spike in spending due to a new launch but no consistent spending afterward. For certain channels, the budget could be turned off for some time and back on due to market dynamics or business strategy changes. In some cases, we can pool together smaller locations that are believed to behave similarly to each other and estimate them using a hierarchical Bayesian model (the same logic can be applied to similar channels) or use trustworthy priors obtained from experiments or external sources to inform the model so that the data isn’t the only factor that determines the coefficients. Being aware of the issues in the data also helps a data scientist make more informed decisions with the model — the importance of EDA analysis (I will have a separate article about it).
- Limited range and amount: an MMM model typically requires at least 2 years of weekly data (longer is better) and a good volume of media spend. If we have 2 years of weekly data, there are only 104 data points (assuming one cross section), and we may have 10–20 media channels and external factors, and face a large p (number of features) and a small N (number of observations) problem. If longer history or more granular time dimension is out of the picture, one possible way is to reduce the number of features by combining smaller channels and prioritizing bigger channels if the business use case allows. This is one of the drawbacks of MMM models mentioned above, without enough range and volume of historical data, it’s better to not build an MMM model and seek other solutions for marketing measurement.
2. self-selection bias and endogeneity
In technical terms, endogeneity happens when a regressor in the model is highly correlated with the error term. This violates basic regression model assumptions and will lead to biased estimations.
For MMM, it happens when there is self-selection in a channel. The best example would be paid search, especially branded paid search. Sometimes a user already has the brand she wants to purchase in mind and searches the brand name online. Then she clicked the paid search ad and made a purchase. This would incur ad spend, however, the purchase would not be incremental because she would have purchased anyway. Similar cases happen a lot in affiliate marketing too. Take me, a sneaky and frugal customer, as an example. Before I buy something, I go to check whether there is any cashback offer in the affiliate app. I simply want to check if I can save some money but the cashback does not affect my purchase decision.
The self-selection bias problem leads to another problem of funnel effects. Upper funnel channels can get less credit than downstream channels. For example, when a user saw an ad on TV first and wanted to make a purchase online. He then searched for the product on Google and bought it from the paid search ad. The model could attribute more credit to the search if not treated well.
There are a few ways to address the endogenous problem and get a more accurate estimation: 1) use informative priors from reliable experimentation on channels with high selection bias to guide the model and prevent the model from overestimating endogenous channels.
2) use instrumental variables to better control for the bias. The basic idea of instrumental variables is to use other predictors that are not correlated with the error terms but are correlated with the endogenous variable to predict the endogenous variable and use the prediction to replace the endogenous variable. Wow, is that a convoluted sentence? LOL. A simple example is the two-stage least square approach. Instrumental variables may be hard to find or construct.
3) use the Selection Bias Correction approach developed by Google (paper here). Google team used causal diagrams of the search ad environment and derived a statistically principled method for bias correction based on the back-door criterion from the literature of causal inference (Pearl 2013). They found that relevant search volume satisfied the back-door criterion and used search queries as controls. After the correction, the coefficient for search is much less than that from the naive model and is aligned with the result from the experimentations.
4) use industry benchmark data to cut down the naive coefficients estimated directly from an uncorrected model. This is probably the least robust and least recommended way but could be a quick and dirty solution.
3. multi-collinearity
Marketers naturally allocate their ad spend across different channels in a correlated way. For example, two channels might be launched together to reinforce each other or to support a product launch.
Multi-collinearity happens when When building the models, highly correlated input variables can cause the model to have high variance and lead to unstable and inaccurate decomposition of channel contribution. I can think of are a few ways to detect multi-collinearity: 1) check the correlation with seasonality and trend controlled between explanatory variables, 2) check Variance Inflation Factors (VIFs), which is regressing each feature with all other features, and computing VIF to determine whether there is severe multi-collinearity, 3) change feature combinations from the model and check whether high variances are observed in the coefficients.
If the multi-collinearity problem is severe, we can
- consider reducing the number of features and removing the variables causing the problem by dropping irrelevant variables, combining similar variables, or using more advanced methods like PCA (principal component analysis).
- apply some transformation or standardization to the variables to see if that can help.
- apply regulations to the models such as Ridge or Lasso regression might also help in some cases.
4. Model selection
In my other story Marketing Mix Modeling 101, I have discussed what aspects need to be accounted for in a good mental model for MMM. I will just summarize it here
- Diminishing Return
- Adstock
- Seasonality, trend, Holidays, and external factors like economy and competition
- Synergistic Effect between different media
- Incorporating empirical and experimentation insights for model calibration and improving the ability to explain causality
The selected model form should at least address the above requirements before we start to fit any data with the model or start to address the data issue or endogeneity or multicollinearity issue.
Thank you and Follow Me for More!
Thank you for reading so far and congrats that you have finished the second story about Marketing Mix Models and other methods of marketing measurement. (Read the first one here.) I plan to write a tutorial on using the Orbit package (you can find an introductory and basic tutorial of Orbit here) and simulated data to build an MMM model as the third story of my MMM series. Follow for more if you are interested!
Stay tuned, follow me, and subscribe to email for more stories about data science and other fun topics!
References
[1] A Hierarchical Bayesian Approach to Improve Media Mix Models Using Category Data by Google team, 2017 [2] Challenges And Opportunities In Media Mix Modeling by Google team [3] Bias correction for paid search in media mix modeling by Google team, 2017 [4] Market Response Models — Econometric and Time Series Analysis, Dominique M. Hanssens, Leonard J. Parsons, Randall L. Schultz,




