
PYTHON PROGRAMMING
Make Python Faster by Caching Functions: Memoization
The article discusses memoization using the Python standard library. The functools.lru_cache decorator makes this so simple!

We all know Python can be slow:
What usually takes most time in Python is calling functions and class methods that run expensive processes. Imagine for a second that you need to run such a function twice for the same arguments; it will need two times as much time even though you both calls lead to the very same output. Is it possible to just remember this output and use it once more whenever it’s needed?
Yes, you can! It’s called memoization, and it’s a common term in programming. You could implement your own memoization techniques, but the truth is, you don’t have to. Python offers you a powerful memoization tool, and it does so in the standard library: the functools.lru_cache decorator.
Although often very efficient, memoization if often omitted in Python textbooks, even those that describe profiling and memory savings during coding. The books that do mention memoization in Python include Serious Python by Julien Danjou, Fluent Python, 2nd ed. by Luciano Ramalho, Functional Python Programming, 3rd ed. by Steven F. Lott.
This article shows two things: how simple it is to use memoization in the Python standard library (so, using functools.lru_cache), and how powerful this technique can be. It’s not only milk and honey, however. That’s why we’ll also discuss issues you can encounter when using the functools.lru_cache caching tool.
Caching using the functools module
functools.lru_cache
Python offers various memoization tools, but today, we’re talking about the one that is part of the Python standard library: functools.lru_cache.
The LRU caching strategy stands for Least Recently Used. In this strategy, the least recently used item is removed from the cache when the size of the cache has been exceeded.
To use it for a function, decorate it with @functools.lru_cache:
from functools import lru_cache
@lru_cache
def foo():
print("I am running the foo() function")
return 10Note that foo() does not take any arguments, which basically means it will be run only once during a session:
>>> x = foo()
I am running the foo() function
>>> x
10
>>> y = foo()
>>> y
10
>>> z = foo()
>>> z
10Indeed, after having been called three times, the function was run only once — but we got the same output (10) three times.
Of course, the real power of function memoization comes with functions that take arguments. Such a function is run for each new set of arguments, but whenever the same arguments have been used before, the function is not run but the remembered output is taken as the function output. Consider the following function:
from collections.abc import Sequence
@lru_cache
def sum_of_powers(x: Sequence[float], pow: float) -> float:
output = sum(xi**pow for xi in x)
print(f"Call: sum_of_powers({x=}, {pow=})")
return outputNote the type of sum_of_powers:
>>> sum_of_powers
<functools._lru_cache_wrapper object at 0x7f...>So its type is not function but lru_cache_wrapper. Let’s see the function in action:
>>> x = (1, 1, 2)
>>> sum_of_powers(x, 2)
Call: sum_of_powers(x=(1, 1, 2), pow=2)
6
>>> sum_of_powers(x, 3)
Call: sum_of_powers(x=(1, 1, 2), pow=3)
10
>>> sum_of_powers(x, 2)
6
>>> sum_of_powers(x, 3)
10So, the last two calls of the function did not actually run it — but thanks to memoization, the function returned the output anyway.
You can use the maxsize argument to lru_cache to indicate how many items are being kept in the cache. The default value is 128. As Luciano Ramalho explains in his Fluent Python. 2nd ed. book, for optimum performance you should use maxsize values that are the power of 2. When maxsize is None, the the cache can keep any number of objects more precisely, as many as memory allows. Be cautious, as this may cause the memory run out.
You can use one more argument, that is, typed, which is a Boolean object with the default value of False. When it’s True, the same value of different types would be kept separately. So, an integer value 1 and a float value of 1.0 would be kept as separate items. When typed=False (the default), they would be kept as one item.
There’s a way to learn how caching worked for a function decorated with functools.lru_cache, thanks to a cache_info attribute added to the function. More precisely, it’s a method:
>>> sum_of_powers.cache_info
<built-in method cache_info of functools._lru_cache_wrapper object at 0x7f...>And this is how the cache_info() works:
>>> sum_of_powers.cache_info()
CacheInfo(hits=2, misses=2, maxsize=128, currsize=2)This means the following:
hits=2→ the cache has been used twice; indeed, we used the function twice forx=(1, 1, 2)andpow=2and twice forx=(1, 1, 2)andpow=3, but the cache was used once per each value ofx.misses=2→ this output represents the two calls to the function with new argument values, so when cache was not used. The more misses-to-hits ratio, the less useful caching is because the function is often used with new values of arguments and seldom with the argument values that have been already used.maxsize=128→ the size of the cache; we’ll discuss in below.currsize=2→ the number of elements already being kept in the cache.
In a real life project in which you want to use caching, it’s good to experiment with it, and the cache_info() method can be very helpful with that. Remember that caching shouldn’t be used automatically for any function; it may lead to time losses rather than gains, as caching itself needs some time.
functools.cache
As of Python 3.9, the functools module offers also the cache decorator. It’s just a wrapper around functools.lru_cache in which maxsize=None. So, decorating with functools.cache is equivalent to decorating with functools.lru_cache(maxsize=None). To be honest, I don’t think it’s a necessary amendment — the standard library doesn’t need, in my opinion, such overly simplified wrappers. What’s wrong with using functools.lru_cache(maxsize=None)?
Comments
Use for class methods
Function caching is considered to be a functional-programming tool, but it can just as well be used for class methods. Unlike Python functions, a Python class can have state, which is why it’s simple to implement individual caching within a class:
>>> class JustOneLetterCachedInside:
... def __init__(self, letter):
... self.letter = letter
... self.cache = {}
... def make_dict(self, n):
... if n not in self.cache:
... print(f"The output for n of {n} is being cached.")
... self.cache[n] = [self.letter] * n
... return self.cache[n]
>>> instance = JustOneLetterCachedInside("a")
>>> _ = instance.make_dict(10)
The output for n of 10 is being cached.
>>> _ = instance.make_dict(10)
>>> _ = instance.make_dict(10)
>>> _ = instance.make_dict(20)
The output for n of 20 is being cached.
>>> _ = instance.make_dict(20)
>>> instance.cache.keys()
dict_keys([10, 20])This is a very simplified caching approach, and one that would not work after changing the self.letter attribute in the class’s instance. It’s easy to solve this issue, however, for instance by making self.cache a dictionary of dictionaries being assigned to keys being letters. I’ll leave you the implementation as an exercise.
This was an example how to do it manually, but we can use the functools.lru_cache decorator as well. Doing so as simple as for a function: enough to decorate the method inside the class definition:
>>> class JustOneLetter:
... def __init__(self, letter):
... self.letter = letter
... @lru_cache
... def make_dict(self, n):
... return [self.letter] * n
>>> instance = JustOneLetter("a")
>>> _ = instance.make_dict(10)
>>> _ = instance.make_dict(10)
>>> _ = instance.make_dict(10)
>>> _ = instance.make_dict(20)
>>> _ = instance.make_dict(20)
>>> instance.make_dict.cache_info()
CacheInfo(hits=3, misses=2, maxsize=128, currsize=2)As you can see, this works just like with functions, so don’t hesitate to use the functools.lru_cache decorator also for class methods when you see such a need.
Only hashable arguments
Standard caching employs mapping using a hash table. This means that it wouldn’t work for functions with unhashable arguments. Thus, for example, you cannot use caching for objects of the following types: lists, sets and dictionaries.
Let’s analyze the above function, sum_of_powers(). Its x argument has a general type of Sequence[float]. collections.Sequence does not say anything being hashable or not; and indeed, some types that follow this protocol are hashable, such as tuple, but others aren’t, such as list. Note:
>>> sum_of_powers((1, 2, 3), 2)
Call: sum_of_powers(x=(1, 2, 3), pow=2)
14
>>> sum_of_powers([1, 1, 2], 2)
Traceback (most recent call last):
...
TypeError: unhashable type: 'list'
>>> from typing import Dict
>>> class Dicti(Dict[str, int]): ...
>>> @ lru_cache
... def foo(x: Dicti) -> int: return len(x)
>>> foo(Dict({"a": 1}))
Traceback (most recent call last):
...
TypeError: Type Dict cannot be instantiated; use dict() insteadJust so you know, static type checkers can point you out a call of a caching-decorated function that uses an unhashable argument. This call is fine:

but this one isn’t:
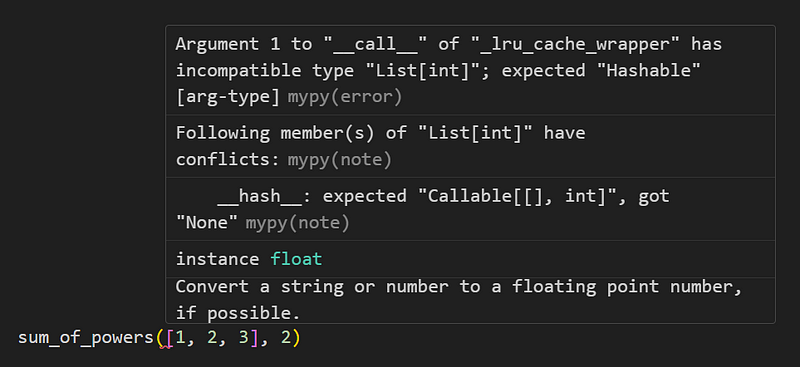
Pure and non-pure functions
You may have heard that memoization should be used solely for so-called pure functions, that is, functions without side effects. A side effect is something that’s done in the background; for example, a global variable is being changed, data are being read from a database, information is being logged.
Usually, non-pure functions should not be cached indeed, but there are a few exceptions. For example, imagine a function that generates a report and saves it to a file, based on the provided values of the function’s arguments. Caching the function will mean generating the report for these argument values only once instead of every time the function is called with these values. In general, costs of I/O operations can be saved thanks to caching. In this case, however, we must be sure that the side effect of such a function doesn’t differ for its subsequent calls. This could happen, for example, when a function would overwrite the file with a new file with the very same contents — but the time of this operations matters.
In fact, we have observed caching of functions with side effects. We did so above, when we cached functions that printed a message to the console. As you can recall, the functions printed messages only during the first call but not when the cache was used. This is exactly what we’re talking about: When the side effect doesn’t matter, you can use caching; when it does, you shouldn’t as you risk that the side effect will be observed only during the first call of the function but not during the subsequent ones.
Performance
I will not present you the example typically presented for caching, that is, a function calculating factorials. Instead, I will use a very simple function that creates a simple dictionary using a dict comprehension.
I will use the following code:
import perftester
from functools import lru_cache
from rounder import signif
def make_dict(n):
return {str(i): i**2 for i in range(n)}
@lru_cache
def make_dict_cached(n):
return {str(i): i**2 for i in range(n)}
n = 100
perftester.config.set_defaults(
which="time",
Repeat=1,
Number=int(1_000_000 / n)
)
t1 = perftester.time_benchmark(make_dict, n=n)
t2 = perftester.time_benchmark(make_dict_cached, n=n)
print(
"Benchmark for {n}",
f"Regular: {signif(t1['min'], 4)}",
f"Cached: {signif(t2['min'], 4)}",
f"Ratio: {signif(t1['min'] / t2['min'], 4)}"
)You can run this script for various n values, which is used as an argument of the two benchmarked functions. It’s easy to guess the hypothesis behind the experiment: the bigger the value of n, that is, the larger the dictionary created by the two functions, the bigger the caching effect should be.
We’ll see if this is the case soon. We will run the script for the following n values: 1, 10, 100, 1000, 10_000 and 100_000. The number of runs needs to be adjusted so that the tests don’t take too much time — but you can run the experiments yourself with more runs; to do so, change this fragment: Number=int(1_000_000 / n).
You may be wondering why I did not create a loop to run all the benchmarks in one run of the script. This is because each experiment should be independent; otherwise, we could risk that the results of the subsequent experiments would be biased. It’s always best to run benchmarks individually, without combining them in the same run of a script.
The script prints the best results for each function and one more metrics: how many times the cached function was faster than the non-cached one. Below, I will show only this ratio:
1: 4.6
10: 26.6
100: 222.7
1000: 551.7
10000: 100.0
100000: 9.2As you can see, the performance of caching is amazing, but at some point (here, for n of 10_000) its performance drops significantly; for even bigger n, it drops dramatically. Can we fix that?
Unfortunately, we can’t. The only change we can make in this function is choosing maxsize, which would be of no use here as the cache keeps only one element: the dictionary for the given value of n.
Therefore, I am afraid we cannot improve the performance of functools.lru_cache in the case of so large items being kept in cache. As you’ll see below, this is not an issue of the caching technique, but of caching itself.
Our performance experiment taught us two significant things:
- Caching using
functools.lru_cachecan help increase performance, even a lot. - Caching very large objects can decrease performance as compared to caching smaller objects.
Let’s implement our own simple caching and check out if the same situation happens for it. This will be an overly simplified caching tool, something I wouldn’t decide to use in a real life project.
This is the code:
import perftester
from rounder import signif
MEMORY: dict = {}
def make_dict(n):
return {str(i): i**2 for i in range(n)}
def make_dict_cached(n):
if n not in MEMORY:
MEMORY[n] = {str(i): i**2 for i in range(n)}
return MEMORY[n]
n = 1000000
perftester.config.set_defaults(
which="time",
Repeat=1,
Number=int(1_000_000 / n)
)
t1 = perftester.time_benchmark(make_dict, n=n)
t2 = perftester.time_benchmark(make_dict_cached, n=n)
print(
f"Benchmark for {n}",
f"Regular: {signif(t1['min'], 4)}",
f"Cached: {signif(t2['min'], 4)}",
f"Ratio: {signif(t1['min'] / t2['min'], 4)}"
)and here are the results:
1: 3.4
10: 18.3
100: 184.2
1000: 726.0
10000: 82.4
100000: 6.7They differ a little bit from the previous ones, but the trend is the same. This shows it’s not the strategy that functools.lru_cache uses that was the reason behind this significant drop in performance. Most likely, it’s the size of the output (here, the dictionary).
Conclusion
Caching is a fantastic tool, one that can help improve performance, even a lot. A great thing is, it doesn’t take much time to learn how to use it, and using it is simple, too.
The Python standard library offers caching via the functools.lru_cache decorator. Oftentimes, it’ll be exactly what you need, but sometimes its limitations can make it impossible to use it. The most significant one seems to be inability to use unhashable arguments. The other one is that caching should be used only for pure functions; nonetheless, it’s not always the case, as we discussed above.
We’re not done with caching. In this article, we discussed the Python standard library tool, but in a future article, we’ll discuss PyPi caching tools, such as cache3 and cachetools. We’ll compare their performance with that of functools.lru_cache, and we will consider their pros and cons.
Thanks for reading. If you enjoyed this article, you may also enjoy other articles I wrote; you will see them here. And if you want to join Medium, please use my referral link below:





