

Maglev: The Load Balancer behind Google’s Infrastructure (Architectural Overview)— Part 1/3
An article by Forbes in 2013 showed that about 40% of internet traffic flows through Google’s network infrastructure. Not all the traffic may be destined for Google’s popular services such as GMail or Search but when it is, Google’s services get bombarded with millions requests per second from all across the globe. Whenever you try Google search for your favorite dragon photo, or use Maps to find out where Timbuktu is, your request travels through a variety of network infrastructure before getting to backend service you requested. The man in the middle intelligently shuffling all the traffic to the appropriate backend is Maglev, the name for Google’s Distributed Load Balancer (LB). If you’re not too familiar with Load Balancers and what they do check out my previous article where I give an overview of them.
In order to cover this beast that is Maglev, I have opted to break it down into 3 separate articles that build on each other. Article 1 (this article): looks to give an overview of Maglev and fundamental components of its architecture. Article 2: Will take a look inside Maglev in particular how the forwarder works. Article 3: The novel and intelligent implementations that have made Maglev so successful.
I have also linked the Maglev research paper “Maglev: A Fast and Reliable Software Network Load Balancer” at the end of each article.
To start us off, let’s begin by looking at the network path between user and backend service.
1. Request Flow
So your friend tells you something cool about a place called Timbuktu, you’ve heard of it, but never known where it is. So you flip open your laptop/phone and do quick Google Maps search to the following url
Once you begin, the following steps occur. For the sake of elaboration
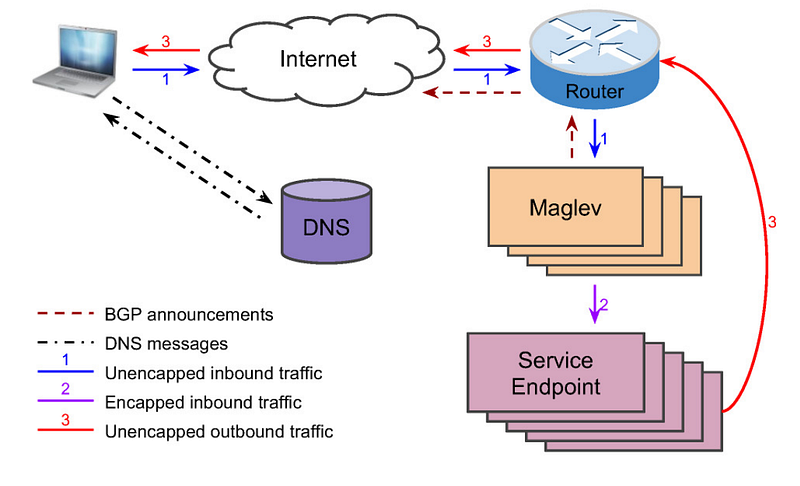
- Your device sends that request to your Internet Service Provider (ISP) e.g. Comcast, AT&T, Telkom, Zuku etc asking if it knows of a certain google.com. Your ISP has a special server known as a resolver, and its job is to find the the Virtual IP address (VIP) for the domain name “google.com.”.
- The resolver with the help of DNS (knowledge of DNS is not important for this article) will find an associated VIP address that can now be used to locate the google.com. service endpoint you requested. DNS will often find the most available VIP address closest to your location.
- The ISP hands the IP address back to your computer, and your browser automatically generates a new request with the VIP address given to you by your ISP.
- With the help of some internet magic and intelligent routing shown in Figure 1 above, you finally land on one of Google’s global routers, that serves as an entry point for any request looking for a Google service.
- With the help of more intelligent routing*, the router will find a Maglev LB that has access to the service you want and hand off the request to the LB that does some quick internal processing, caching and identification of the most suitable service.
- With the help of Direct Server Return, the service communicates back through to the router bypassing the MLB, through the internet and voila! You now know Timbuktu is an ancient town in the center of Mali.
A lot has happened behind the scenes to get you your result. But let’s focus on Load Balancing, and how and why Maglev was designed differently to your traditional LB.
2. Maglev vs Traditional Load Balancer
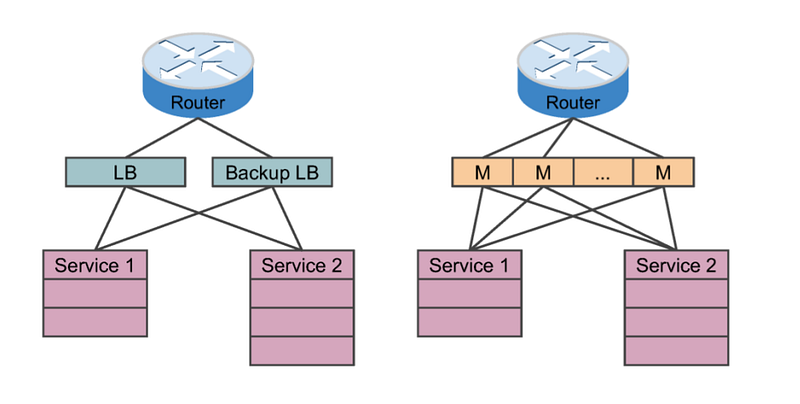
Figure 3, showcases a traditional LB (left) and a Maglev LB (right) that sit between a router and some arbitrary back end services.
2.1 Traditional LB
Incoming requests go through the router to the LB then routed to a backend service. For redundancy, often times a backup LB is provided that is plugged horizontally with the main/primary LB and can be used for redundancy and at times increased throughput. In most cases the use of a traditional LB is sufficient, but when working at Google’s scale, there are several limitations with this approach
Limitations of the Traditional LB
- The paper claimed that such a design falls short of Google’s “high” throughput requirements.
- Scaling is limited to a single machine’s throughput capacity
- Though often deployed in pairs i.e primary LB and a backup, redundancy is only 1 + 1. R.K Johnston writes an interesting blog post talking about how 1 + 1 redundancy is not good enough. In essence, 1+1 systems are designed to often be replicas of each other, if one goes down, the +1 replica has to handle the load. In systems with 99.99% reliability, there is a chance of one going down quite often (errors, maintenance etc). Over a period of time, the chances of both primary and +1 being out of service increases. R.K Johnston states that this happens more often than you would think.
- Hardware LBs in particular come with several drawbacks. Although they can be faster: a. The design is inflexible for modifications and rapid prototyping. b. Scaling these LBs typically requires purchase of new hardware that also needs to be deployed. c. Costly to purchase and upgrade.
Maglev on the other hand, finds ways to addresses these limitations.
3. Maglev
Maglev is the name of Google’s Distributed LB that has been in use since 2008. A typical Maglev instance is designed to processes about 813,000 1.5 kilobyte IP packets per second to over 9,060,000 100 byte IP packets per second, over a 10 Gbps line rate. Maglev unlike some traditional LBs is a software-based LB that runs on Linux commodity servers. This is a very important point to remember as most of the benefits of software-based LBs apply.
Benefits of Maglev
- Maglev can run on typical Linux servers (that Google already had in abundance), and could easily be built as a distributed LB running on these servers in multiple data centers worldwide increasing availability.
- With regards to availability and redundancy, Maglev offers N + 1 redundancy (see Figure 3), instead of 1 + 1 as per your traditional LB.
- Features can quickly be added and deployed to the existing software.
- According to the paper, services can easily be divided across multiple shards of the LB in order to achieve performance isolation.
Admittedly, the paper notes that the design of Maglev is inherently very complex despite its ability to overcome most of the limitations of traditional LBs.
3.1 Design Goals
In order to achieve maximum reliability and throughput, Maglev uses two key design principles
- Connection Persistence: Which means, once a connection from a user is made to a particular endpoint, that connection will continue to be served from that endpoint and not be swapped out to another similar endpoint to ensure quality of service. This is done through connection tracking and consistent packet hashing.
- Consistent Hashing: In order to process hundreds of thousands of packets of differing sizes and structure, a technique of 5-tuple hashing (source IP, source port, destination IP, destination port and IP protocol number), is used to encapsulate packets, consistently deliver them to the appropriate receiving queue where they can ultimately be matched with appropriate backends.
One area that is important to note, is how packets arrive at the Maglev. Section 1 gave an overview of what this looks like. However one key component in the cluster is the router. Through various techniques, Google’s routers are able to intelligently select appropriate Maglev’s to send incoming packets to. The following section shows how it is done.
4. Router & Maglev Interaction
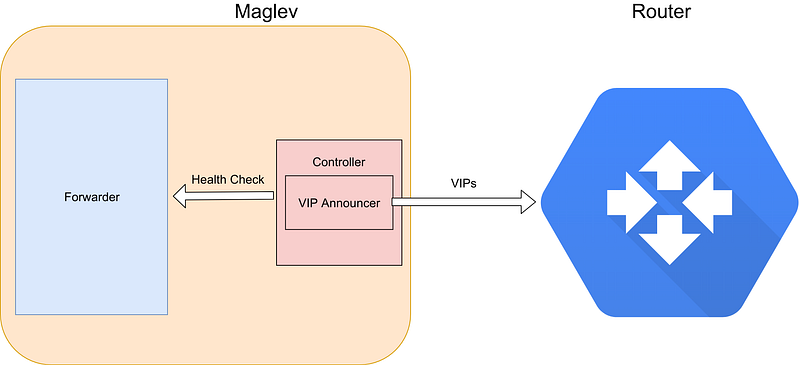
Within every Maglev, there is a controller and within the controller is a component called the VIP Announcer. The controller observes the health of the forwarder and based on the health, uses the VIP announcer to inform the router of the available VIP backends that can be accessed from this Maglev instance. The controller ultimately, makes the decision on whether to continue to announce the VIPs of the backends in the forwarder. To ensure quality of service, only healthy forwarders in a Maglev can be selected. If a forwarder is deemed unhealthy, the controller informs the router that traffic to cannot be served by that Maglev instance.
For instance, we have a Maglev instance called Maglev Alpha. Maglev Alpha has the following backend services, Google Drive, GMail and Maps (based on some configuration objects). The VIP announcer would then announce these services VIPs to the router. The router would then announce these VIPs to Google’s backbone and this information is then propagated to the internet making this information globally accessible i.e for DNS etc.
Once a request for GMail is received at the router, it would know that Maglev Alpha has these resources healthy and available and would direct the packets to it. If GMail on Maglev Alpha for instance went down for maintenance or other issues, Maglev Alpha’s VIP announcer would inform the router that this Maglev instance cannot handle requests for GMail and therefore the router would ignore it for those particular requests. This is highly simplistic example, however it helps elaborate the role of the VIP announcer and the controller.
5. Packet Forwarding
One element I have intentionally obscured in Figure 4 is the forwarder. The forwarder is responsible for the following:
- Handle incoming packets, quickly and reliably
- House a pool of backends that it constantly monitors
Each VIP is configured to either one or more backend pool. The implementation behind the forwarder is detailed and complex and we shall address it in the next article.
Conclusion
Maglev takes a different approach to load balancing that allows better redundancy and scalability through the use of software instead of hardware. We have seen where it lies with regards to Google’s infrastructure, and how it communicates with other Google networked devices such as routers to ensure, routers can efficiently direct packets to available Maglev instances. This article served to shown an overarching perspective. Part II goes deeper into the implementation of the forwarder and other components that make Maglev work.
I must end by stating, majority of the information was obtained from the Google Research paper “Maglev: A Fast and Reliable Software Network Load Balancer” that is linked below
As always, thanks for reading.
Twitter: @martinomburajr
Links
Google’s Research Paper
Maglev: A Fast and Reliable Software Network Load Balancer — https://research.google.com/pubs/pub44824.html





