Dimensionality Reduction | Towards AI
Machine Learning: Dimensionality Reduction via Principal Component Analysis
In machine learning, a dataset containing features (predictors) and discrete class labels (for a classification problem such as logistic regression); or features and continuous outcomes (for a linear regression problem), is used to build a predictive model that can make predictions on unseen data. The predictive power of a model depends greatly on the quality and size of the training dataset.
Generally, the larger the dataset the better, however, there is always going to be a tradeoff between the size of the dataset and computational time needed for training. It turns out that in some very large datasets, there might be lots of redundancy in the features or lots of unimportant features in the dataset, and hence dimensionality reduction techniques could be used for selecting only a limited number of relevant features needed for training.
Principal Component Analysis (PCA) is a statistical method that is used for feature extraction. PCA is used for high-dimensional and correlated data. The basic idea of PCA is to transform the original space of features into the space of principal components, as shown below:
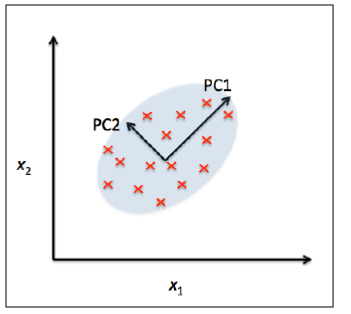
A PCA transformation achieves the following:
a) Reduce the number of features to be used in the final model by focusing only on the components accounting for the majority of the variance in the dataset.
b) Removes the correlation between features.
How does PCA work?
To illustrate how PCA works, we show an example by examining the iris dataset.
The code can be found on GitHub.
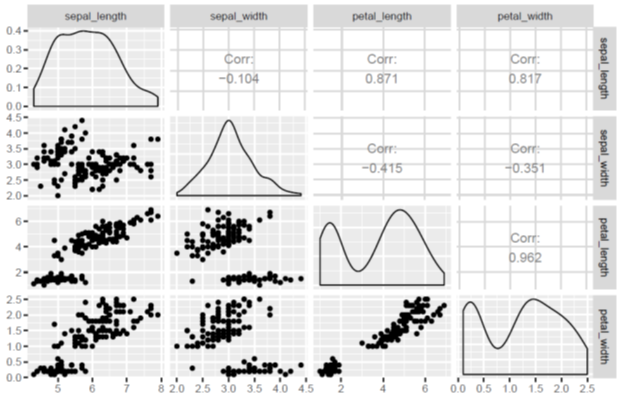
Let us look at the covariance matrix:

Let us now examine the transformed covariance matrix:
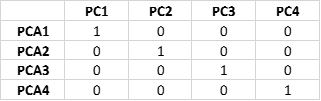
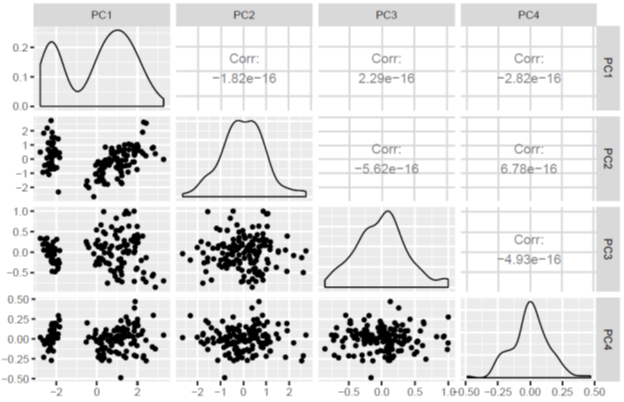
Here is a summary of helpful indicators from a PCA calculation:

Based on this summary, we see that 99.5 percent of the variance is contributed by the first three principal components. This means that in the final model, the fourth principal component PC4 could be dropped since its contribution to the variance is negligible.
In summary, we have shown how the PCA algorithm can be implemented in R using the iris dataset for illustrative purposes. You can download the code on GitHub.
Thanks for reading.