
LONGNET: Model Capable Of Processing Up To 1 Billion Tokens (Revolution in Transfomers)
Why LONGNET’s Innovative Approach Could Change How We View Language Models Forever. The Next Evolutionary Leap in Transformers

Introduction
What is Longnet?
LONGNET, a pioneering approach in the realm of Transformers, introduces a groundbreaking concept known as Dilated Attention. This transformative architecture addresses a significant challenge that plagued traditional Transformers — the exponential increase in processing demands as sequence lengths expanded.
Through LONGNET:
- The computational load dilemma of longer sequences is resolved, presenting a solution to the processing power surge faced by conventional Transformers.
- An all-encompassing capability emerges, ensuring superior handling of sequences, both short and extensive.
- The power of extended contexts is harnessed, elevating the language model’s performance to new heights.
Incorporating Dilated Attention, LONGNET stands as a beacon of innovation, transforming the landscape of sequence processing within the realm of Transformers.
3 main points I will Address in this article:
🚀 Addressing the Critical Challenge of Streamlining Processing for Lengthy Sequences
💡 Revolutionizing Efficiency with Dilated Attention: Simplifying Computational Load in Transformers
🔍 Dive into LONGNET: Pioneering the Implementation of Dilated Attention within the Transformer Framework
Advantages of Processing One Billion Tokens
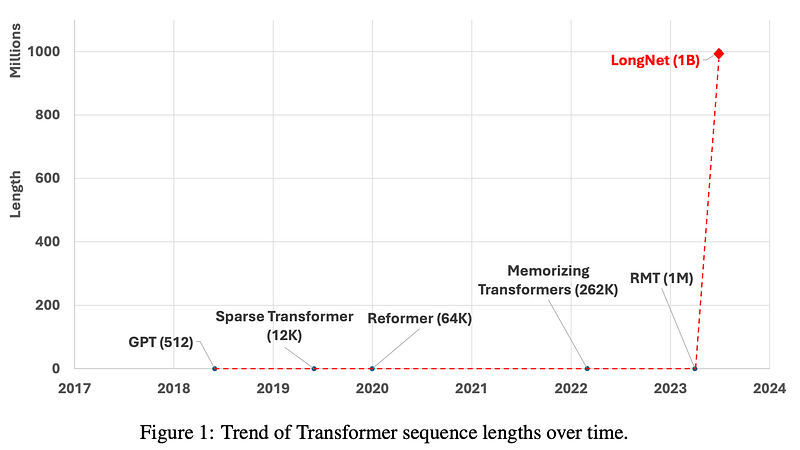
Approximately 250,000 times the number of tokens in GPT-4, a staggering one billion tokens poses a monumental challenge for any model to process. The vastness of this token count makes it a formidable task to encompass an entire book or even the entire expanse of the web within the model’s grasp.
In response to this colossal hurdle, the authors of the study propose a groundbreaking approach called LONGNET. This approach introduces the concept of scaling sequence length linearly, opening the door to extended context learning. Moreover, the authors tantalizingly hint at the potential to incorporate entire web datasets in the future, suggesting a paradigm shift in context learning that holds exciting prospects. With LONGNET, the boundaries of context learning are redrawn, paving the way for a plethora of real-world applications that can leverage its capacity for absorbing extensive context.
Background of LONGNET
LONGNET and Dilated Attention herald a transformative solution, addressing the dual challenges of expanding sequence length and mitigating the computational intricacies tied to the transformer architecture.
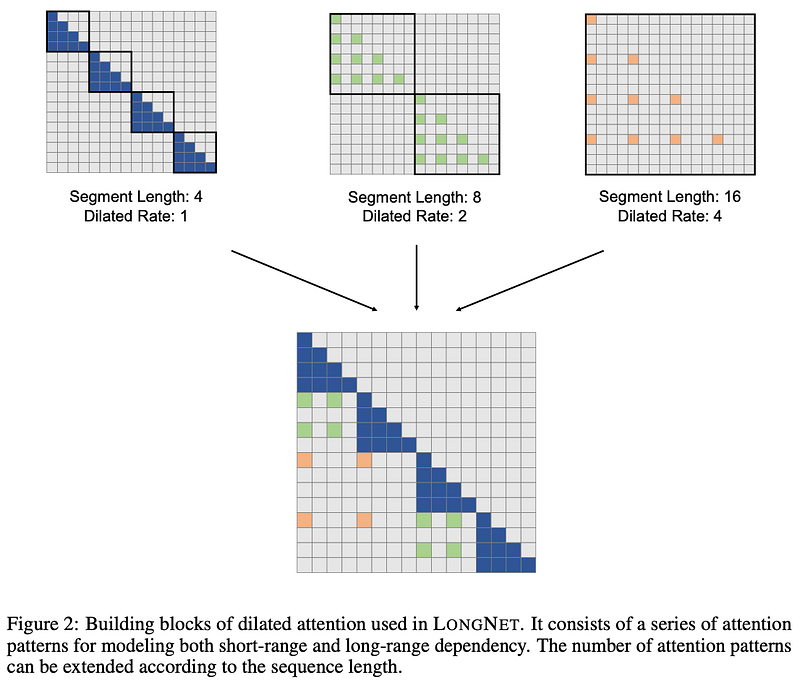
While the advantages of augmenting sequence length were well understood, the quandary emerged from the quadratic surge in computational complexity within the Transformer model. This predicament led to exponential demands on processing power, creating a formidable obstacle. In response, LONGNET introduces an ingenious antidote in the form of Dilated Attention, a novel component that serves as a beacon of computational efficiency.
By seamlessly amalgamating LONGNET and Dilated Attention, a harmonious synergy emerges, ushering in a new era of streamlined sequence expansion while elegantly circumventing the computational bottlenecks that previously hindered progress. This dynamic duo charts a course toward enhanced performance and practicality, poised to redefine the very landscape of transformer-based methodologies.
Benefits of increased sequence length
Sequence length stands as a foundational pillar within the realm of neural networks, evoking an innate desire for expansiveness that extends indefinitely. Moreover, the augmentation of sequence length presents a triad of compelling advantages that resonate profoundly:
- Enhanced Contextual Grasp: A sprawling sequence empowers the model to embrace a panoramic spectrum of context, enabling it to meticulously forecast the current token through the lens of distant information. This capability proves invaluable, particularly when deciphering spoken language fragments within sentences or navigating the labyrinthine corridors of lengthy documents.
- Nuanced Causal Relationships: With an extended canvas of sequence, the model gains the capacity to absorb intricate causal connections and intricate inference mechanisms imprinted within the training data. The paper’s discourse underscores that brevity in dependencies tends to yield suboptimal outcomes, underscoring the model’s appetite for depth in causality.
- Leveraging Extended Contexts: The elongated tapestry of sequence unfurls the opportunity to fathom more profound contexts, harnessing their inherent richness to propel the language model’s output to unprecedented heights. The model thrives on the extended canvas, leveraging its expanse to refine its output prowess.
These virtues collectively underscore the irreplaceable value of lengthened sequences within the paradigm of neural networks, igniting a symphony of advantages that reverberate throughout the landscape of language comprehension and generation.
Reduced Transformer computational complexity
A remarkable breakthrough unfolds in the realm of reduced Transformer computational complexity. As the sequence length expands, the computational demands of the traditional Transformer model grow exponentially — a challenge mitigated ingeniously through the introduction of Dilated Attention in this study.
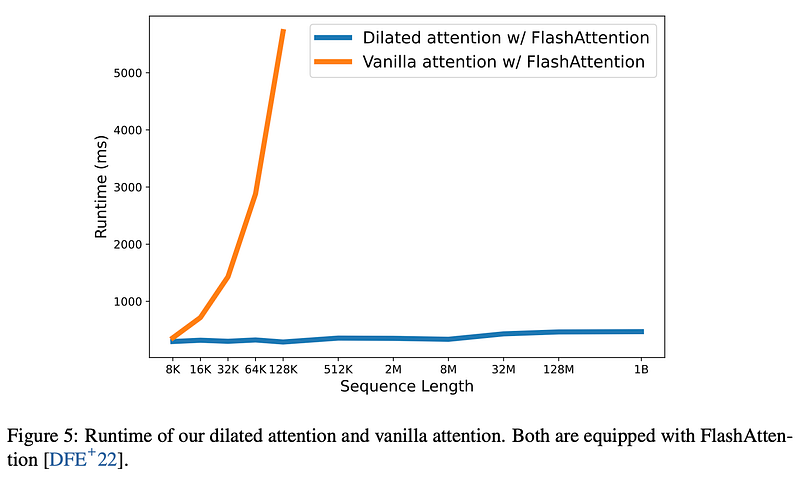
In stark contrast to the quadratic escalation witnessed in the vanilla Transformer, the Dilated Attention mechanism offers a linear progression of computational requirements with respect to sequence length. The elucidation of this transformative effect is vividly captured in Figure 5 of the paper, where a comparative analysis of vanilla and dilated attention performance comes to life. Sequences ranging from 8K to an astounding 1B tokens undergo incremental scaling, while average execution times across 10 forward propagations are meticulously recorded and juxtaposed.
Both models benefit from the FlashAttention Kernel, a dual-edged sword enhancing both memory efficiency and speed. The graph unequivocally showcases Dilated Attention’s ability to maintain almost constant latency as sequence length expands — a pivotal attribute that paves the way for scaling sequences up to a staggering one billion tokens.
In sharp contrast, the vanilla attention mechanism exhibits a quadratic surge in computational expenditure as sequence length burgeons, resulting in an expeditious ascent in latency. Notably, vanilla attention lacks a distributed algorithm to surmount the limitations imposed by sequence length.
This riveting revelation simultaneously underscores the Long Short-Term Memory Network’s (LONGNET) supremacy, embodied in its linear complexity and fortified by adept distributed algorithms. The very fabric of computational complexity is rewoven, charting a course toward enhanced efficiency and unlocking new vistas in the realm of sequence processing.
Improvements
- Enhanced Computational Efficiency: Have you observed the remarkable enhancement in computational efficiency mentioned earlier? Let’s delve into the extent of this improvement from a theoretical angle.
- Revolutionary Architecture — Dilated Attention: The stride towards improved computational efficiency led us to embrace a groundbreaking architecture known as Dilated Attention. This innovation aims to streamline the computational complexity of the Transformer.
- Quantifiable Improvements: Comparing the newly introduced Dilated Attention with traditional counterparts such as Conventional Attention and Sparse Attention yields insightful results. Our analysis unveils a significant reduction in computational complexity, as evidenced by the table below.

Dilated Attention: Unpacking Computational Complexity Upgrades?
Let’s look at why Dilated Attention reduces the computational complexity from the mathematical equation.
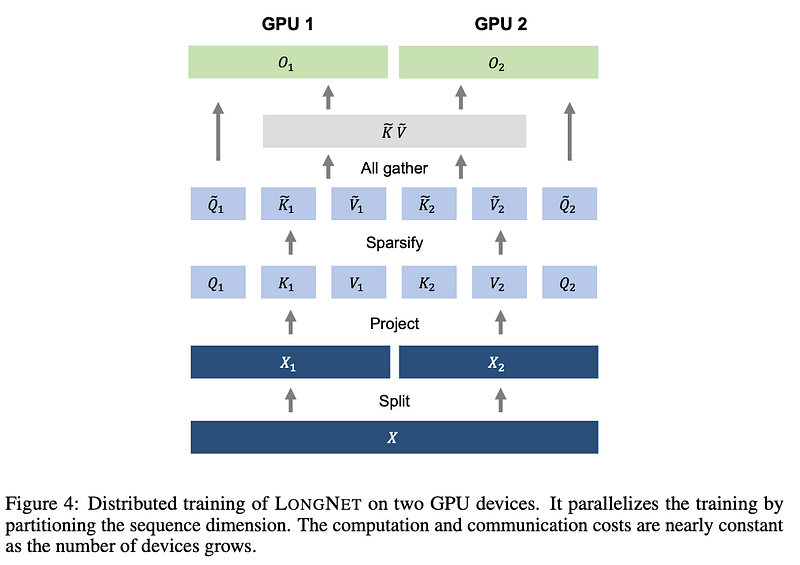
Distributed Training in LONGNET
- Dilated Attention’s computation order has been notably optimized.
- Yet, scaling sequence length to a million on one GPU faces limits due to resources and memory.
- To tackle this, distributed training methods are suggested for extensive model training, involving parallel and sequence processing, along with pipelining.
- However, these methods fall short for LONGNET, particularly with sizable sequence dimensions.
- Addressing this, LONGNET introduces a fresh distributed algorithm for multi-device extension without sacrificing generality.
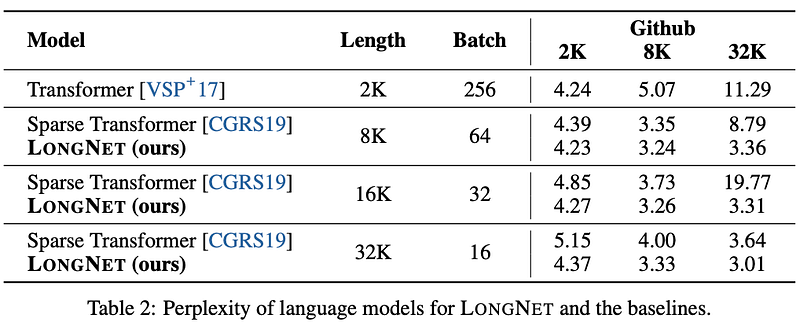
Experiments in language modeling
- This paper implements a language model using the MAGNETO [WMH+22] architecture, incorporating XPOS [SDP+22] relative position encoding.
- However, a notable change is the substitution of the standard Attention with Dilated Attention.
- LONGNET is then compared to both Vanilla Transformer and Sparse Transformer.
- When scaling sequence lengths from 2K to 32K, the batch size is adjusted to maintain a constant number of tokens per batch.
- The authors’ experimentation is limited to a maximum of 32K tokens due to computing constraints.
- Here are the perplexity results for each of the language models.
Summary
The creators have exciting plans to broaden LONGNET’s capabilities. They’re aiming to tackle tasks like large-scale language modeling, pre-training for BEiT, and even working with genomic data. This will make LONGNET even more versatile and high-performing. Additionally, the ability to handle longer prompts might lead to more advanced results without extra learning, like using lots of examples.
