
Load Twitter data into Google Sheet and automate it — Start a simple data pipeline
How to ingest data from Twitter into a sheet automatically and scheduled.

Data sources are basis of machine learning, data analysis, data visualization. At the beginning of the data cycle, there are a multitude of data sources in raw format. Every day, we participate in the enrichment of all these data sources. As a data engineer, part of our job is to load and transform that data into insights.
In this tutorial I will show you how to build a first part of a simple data pipeline, we will see :
- Retrieve data from a source, here Twitter
- Enrich a database, here Google Sheet (we can load our data directly into Big Query, but in another tutorial I want to use Fivetran to load my data, so google sheet will be my operational database)
- Automate and schedule all of this
One can imagine that this goal could be real for a marketing company that analyzes tweets.
The goal will be to build two tables :
- Users Table : Which return data about target people
- Tweets Table : All tweets from a list of user (target people)
Some examples UC :
- Dashboard with alls metrics, KPIs and user filter
- Which topics a user tweet about ?
Tools :
- Python
- Google Drive
- Cloud Function
- Pub/sub
- Cloud Scheduler
Step One : Build the script
This script takes a list of ten Twitter users and retrieves those users’ data and their latest tweets from the last 7 days.
Requirements :
- Have a twitter dev account developer.twitter.com
Import :
Global Variable :
Add this function to pass credentials in query :
We need a function for query the API :
The function for build Users Table :
The function for Tweets Table :
These two tables will be part of my datalake, I will show you in another tutorial how I load this Google sheet data into Big Query with tools like Fivetran and how I model my data with dbt to build my data warehouse.
A write function, for load data into Google Sheet :
For this you need to do some steps :
- Create twitter_users and twitter_tweets google sheet
- Enable Google Drive API in your GCP project
- Generate json key
- Share the sheet to your service account
You can follow a detailed tutorial here : erikrood.com
The entry point function (main) :
Find here all the code : github.com/Orer0/twitter_pipeline_public
Step 2 : Create a Pub/Sub Topic
We want to trigger our cloud function and to do this we will use Pub/Sub (more info on this tool : cloud.google.com/pubsub)
Run the following command in a cloud shell for create the pub/sub topic
gcloud pubsub topics create twitter_dsStep 3 : Deploy this script in a Cloud function
Add all necessary files in a folder on the cloud shell (you can use git for doing this, or copy and paste in vi editor).
Don’t forget to include the drive_creds.json and the requirements (in a file) at the roots of the folder.
# add requirements.txt in the folder with :
requests==2.23.0
pandas==1.3.5
pygsheets==2.0.5You can deploy the Cloud shell with the following command :
gcloud functions deploy twitter_data_source --entry-point get_twitter_data_source --runtime python37 --trigger-topic twitter_dsWe now have a cloud function that is triggered by pub/sub.
For each message sent to the twitter_ds topic, the cloud_function will run
Step 3 : Setup cloud scheduler for run this script every week
The last step is to run this script on a schedule, given this script has no dependencies, we can just set up a cron with the cloud scheduler and not use Composer
You can easily do this with cloud console on this page console.cloud.google.com/cloudscheduler :
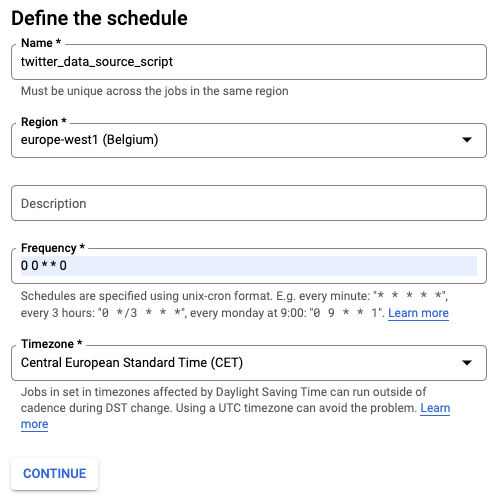
This website can help you for define your cron crontab.guru . In my case I choose an execution once a week. Thus, each week, the script retrieves tweets from the last seven days.

Click on Create for validate the job.
To summarize :
- We have see how to use the twitter API for retrieve data.
2. How to load data in Google Sheet.
3. Deploy this in a cloud function.
4. Automate script triggering with Pub/Sub and Cloud Scheduler.
It’s a good training and a good start to build a data engineering pipeline !

The next tutorials to come will be :
- Building my datalake into BigQuery using modern loader like Fivetran or Airbyte
- Using dbt for make transformation and build my data warehouse
- Using a BI tools for give value on my data and obtain my first insight
Hope this tutorial will be helpful for you.
More on my youtube channel : AurélienRoblin
Please feel free to comment if you have any questions. Or contact me directly on my different networks : arolab.xyz
Follow me for more content like this !