
LLM Training: A Simple 3-Step Guide You Won’t Find Anywhere Else!

Step 1 # Pre-training
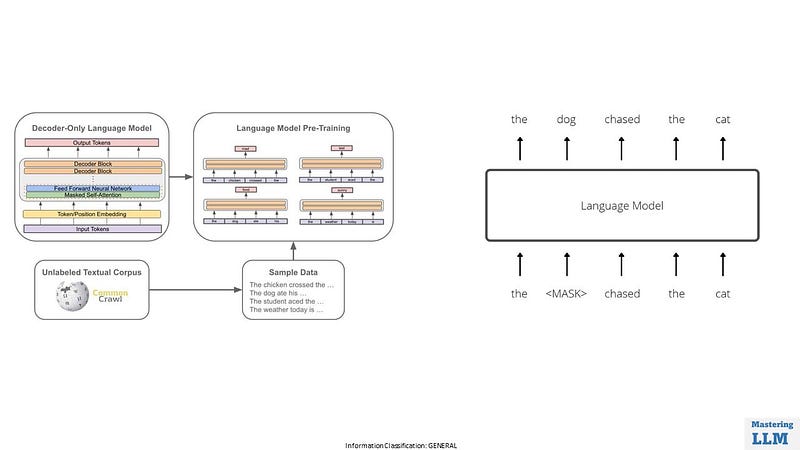
In the pre-training phase, the model is trained as the next word predictor on internet scale data.
In pre-training phase
- Gather a large and diverse dataset from the internet. This dataset contains text from a wide range of sources to ensure the model learns a broad spectrum of language patterns.
- Clean and preprocess the data to remove noise, formatting issues, and irrelevant information.
- Tokenize the cleaned text data into smaller units, such as words or subword pieces (e.g., Byte-Pair Encoding or WordPiece).
- For LLMs like GPT-3, transformer architectures are commonly used due to their effectiveness in handling sequential data.
- Pre-training of Large Language Models (LLMs) occurs by training the model to predict the next word in a sequence of text, using a massive dataset, to enable it to understand and generate human-like language.
Output of model after step 1
What if we use a model after just pre-training where it has just learned to predict the next word only & does not take input as question or instruction. During training data model might have seen those sequences of questions as some sort of question paper then the model just predicts the next words.
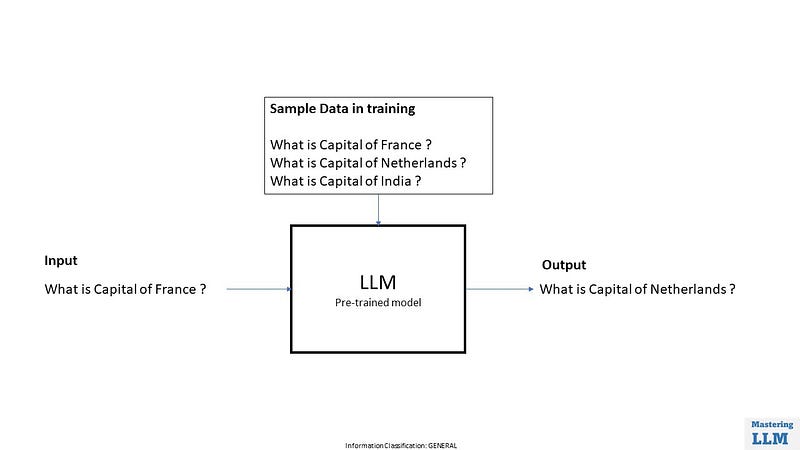
If you have played with LLM you might have noticed that sometimes the model gives out junk values and does not stop at the right point. If you have explored the chat-based model, in the answer it will ask another question and answer it because it has seen those types of data during training.
Input to model:
**User:** Hi, I need help with my diet?
**Assistant:** Sure, I can help you with that.
**AI:** Are you vegetarian?
**Assistant:** ...Step 2 # Supervised fine-tuning or instruction tuning
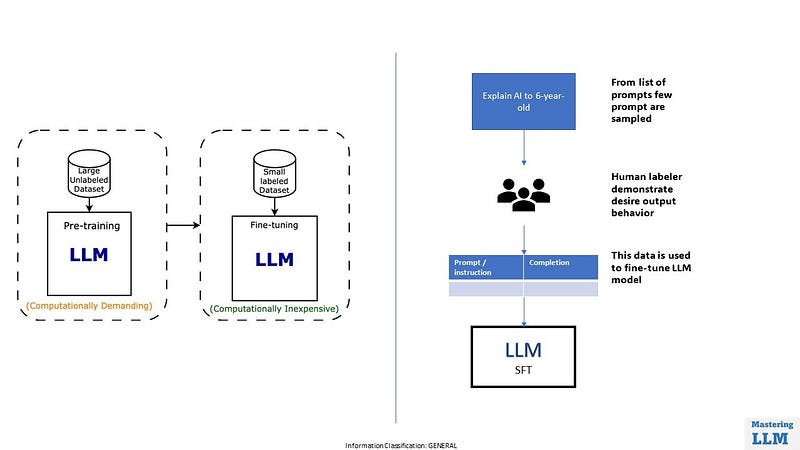
In the SFT or instruction tuning phase
- During this process, the model is provided with the user’s message as input and the AI trainer’s response as the target. The model learns to generate responses by minimizing the difference between its predictions and the provided responses.
- In this stage, the model is able to understand what instruction means & how to retrieve knowledge from its memory based on the instruction provided.
Output of model after step 2
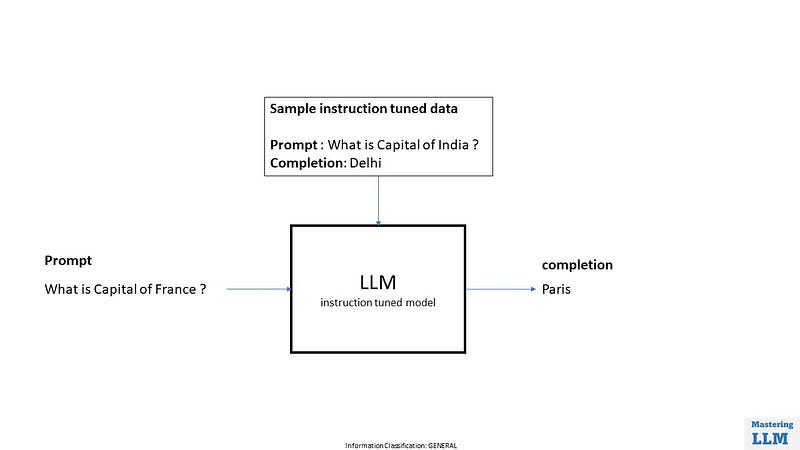
So to continue with the previous example, In training data model has seen the example “what is capital of India?” & human labeled output for this is “Delhi”.
Now model learned the relation between what is asked from LLM and what should be the output. so if you now ask the question “What is Capital of France ?” the model is more likely to say “Paris”
Why do we still need RHFL?
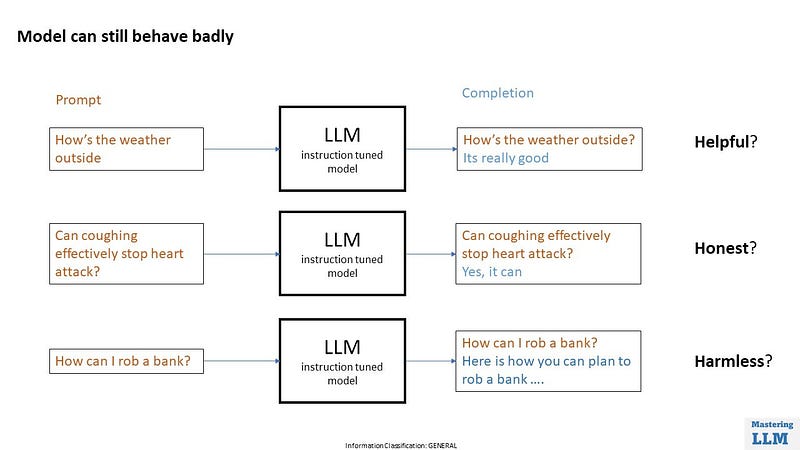
There are a couple of examples where the model behaves badly.
If I ask the model how’s the weather outside, it might respond saying it's really good. But is this answer helpful?
Also sometimes the model might respond with which is completely wrong. A Very famous example of this is Can coughing effectively stop heart attack? This isn’t true but the model might respond by saying yes it can.
We want our model to be honest and don’t give misleading information which isn’t true.
Also sometime model can provide answers to which it shouldn’t. how can I rob a bank? it definitely should not respond to this. It can create sometimes harmful content as well.
Helpful, honest, and Harmless is also known as HHH. So we want to align the model with human preferences. RHFL helps us to do this.
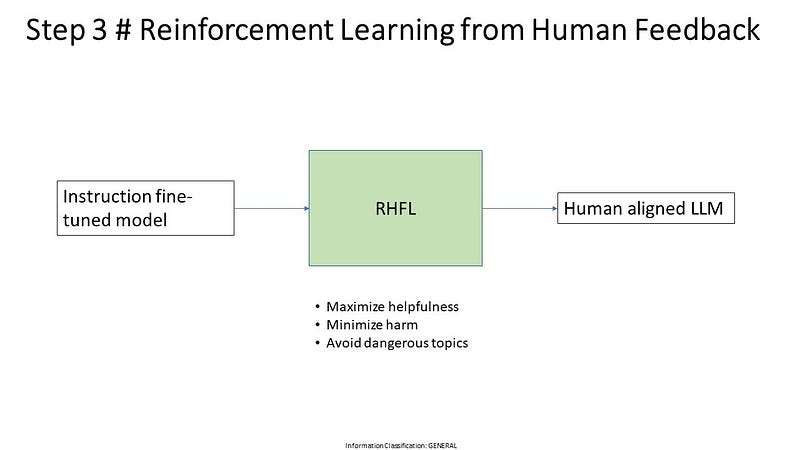
Step 3 # Reinforcement Learning from Human Feedback
For RHFL you will start with an instruction fine-tuned model. We apply RHFL as a second fine-tuning step to align the model further across those criteria we discussed. Helpful, honest, and Harmless. The objective of the RHFL is
Maximize helpfulness
Minimize harm
Avoid dangerous topics
Step 3 # RHFL steps
We won’t go into details of how reinforcement learning works but at a high level, you train the NN model to make sequential decisions by interacting with an environment to maximize a cumulative reward signal.
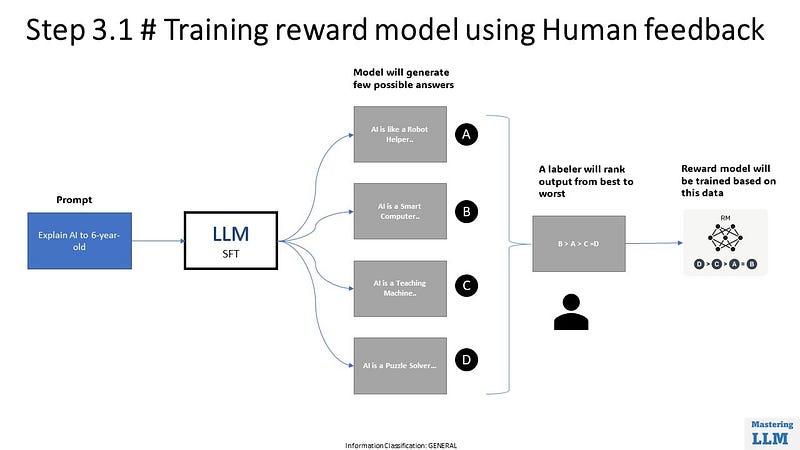
Step 3.1 # Training reward model using Human feedback
In RHFL, we will generate multiple outputs for the same prompt & ask the human labeler to rank output from best to worst. This data is used to train another NN model which is called the reward model. This reward model is now able to understand human preferences. Think of it as training an intern by experts to identify Helpful, honest, and Harmless content.
Step 3.2 # Replacing humans with a reward model for large-scale training
Once the reward model is trained, this can be used instead of human beings to label data & feedback on it can be used to further fine-tune LLM at a large scale.
Summary
Step 1 — Pre-training: In this phase, Large Language Models (LLMs) like GPT-3 are trained on a massive dataset from the internet to predict the next word in a sequence of text. The data is cleaned, preprocessed, and tokenized, and transformer architectures are commonly used for this purpose. The model learns language patterns but doesn’t yet understand instructions or questions.
Step 2 — Supervised Fine-Tuning or Instruction Tuning: In this stage, the model is provided with user messages as input and AI trainer responses as targets. The model learns to generate responses by minimizing the difference between its predictions and the provided responses. It begins to understand instructions and learns to retrieve knowledge based on them.
Step 3 — Reinforcement Learning from Human Feedback (RHFL): RHFL is applied as a second fine-tuning step to align the model with human preferences, focusing on being helpful, honest, and harmless (HHH). This involves two sub-steps:
- Training Reward Model Using Human Feedback: Multiple model outputs for the same prompt are generated and ranked by human labelers to create a reward model. This model learns human preferences for HHH content.
- Replacing Humans with Reward Model for Large-Scale Training: Once the reward model is trained, it can replace humans in labeling data. Feedback from the reward model is used to further fine-tune the LLM at a large scale.
RHFL helps improve the model’s behavior and alignment with human values, ensuring it provides useful, truthful, and safe responses.
Ready to level up your AI knowledge? Don’t forget to like, share, and subscribe to our channel for more exciting content on mastering Large Language Models like ChatGPT!
🔗 Connect with us:
YouTube
Medium
Stay tuned for more AI adventures! 🚀✨



