
Live Projections for Read Models with Event Sourcing and CQRS
Many writings about CQRS and Event Sourcing show the most heavyweight implementation of the query side (aka read models) without even mentioning a more lightweight alternative that even comes without the dreaded “problem” of eventual consistency.
Disclaimer: CQRS and Event Sourcing are orthogonal concepts. While typically an ES architecture needs CQRS for the query side, CQRS can be implemented without ES, even without Events, and even without separate data storage (e.g. DB tables or EventStores)!
How does the heavyweight “materialized view” implementation look like?
- There is a separate service with a separate database for the query side that hosts a read model (or many — I’ll use the singular form further on)
- The events that populate the read model are published from the event-sourced command side (write model) over a message broker like RabbitMQ or an event streaming platform like Kafka and consumed by the read model
- The event handlers of the read model then persist the changes described in the events into a persistent model — a materialized view — that is optimized for queries, i.e. it can serve queries very fast in a format that is optimized for the client, e.g. a JSON structure that is easy to consume
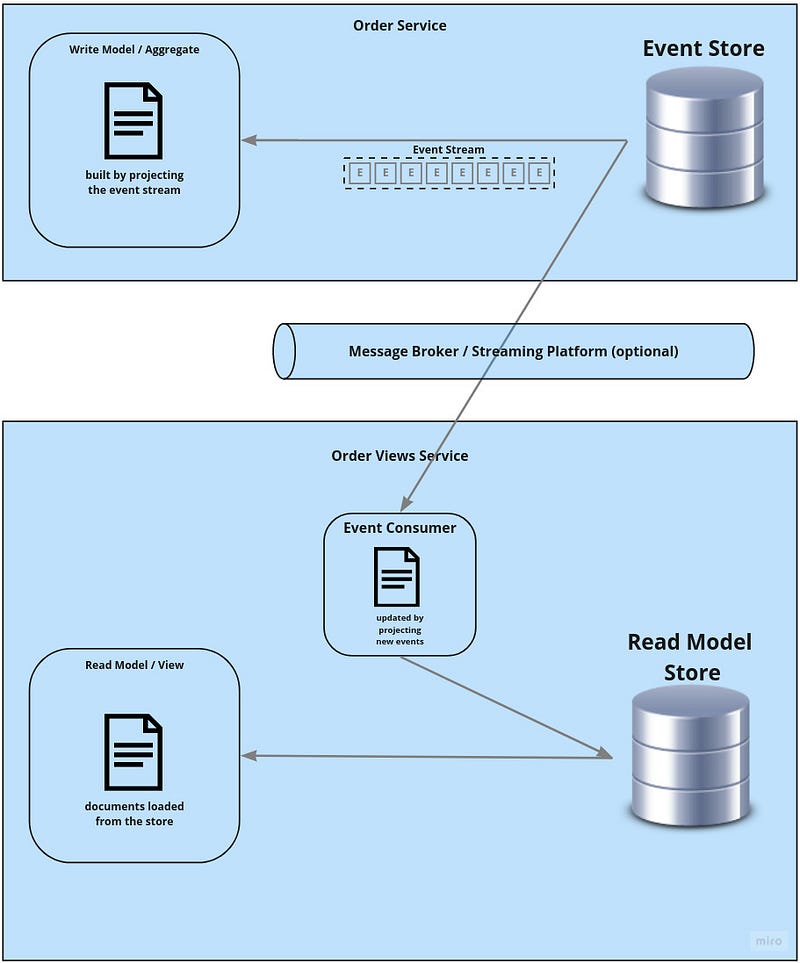
Now, this implementation undoubtedly has some selling points. Queries can be very fast and the write and read models are almost independent (only coupled by event contracts). But those advantages come with a price:
- There is another service to implement and maintain (cost of ownership)
- There might be another technology to maintain, e.g. if the Event Store of the events-sourced write model is done with PostgreSQL but the read model uses MongoDB
- The deployment of the read and write model needs to be coordinated — if changes on the write model also affect the read model
- The dreaded “eventual consistency”
In reality, this is rarely an issue at all, given the projection of published events into the read model is fairly fast. Still, the whole process from storing events to updating the read models might take a while, even in the range of many seconds or longer. Still, it is important that UI/UX is aware and is also designed with eventual consistency in mind.
- And finally, the process of replaying events to replace broken read models or to create additional read models
- This is typically done by republishing all existing events from one — or multiple — write models and consuming them in the new read model
- One problem to address is the fact that the write model is live and keeps on publishing events
If subscription-based event storage — like EventStoreDB — is used instead of a message queue or streaming platform this might be simple.
- If the amount of events is huge it might take many hours or even days until the new read model catches up with the live write model
I don’t want to dive too deep into all the broken implementations of CQRS/ES systems out there. But I want to mention that the usage of a message broker (or streaming platform) imposes a little dilemma. In such a case there is no single source of truth for events because the message broker could have different data than the Event Store (lost messages, messed up order, and whatnot). Such problems can be avoided by using a grown-up Event Store implementation like EventStoreDB with its subscription model. If no such system is used events must be stored in the Event Store first before they are published! Using the “outbox pattern” is a possibility to get that right (you’ll have to research that for yourself in case).
Let’s have a look at “live projections” as a lightweight alternative
In an event-sourced write model, the current state (the “decision state”) gets rehydrated each time a command comes in, by projecting the full event stream of past events into a state that is suitable to decide if the command can be handled and which new event(s) should be recorded as a result.
So why not do the same for the read model?
We just need to define a structure for the read model — a view — and rebuild it live from the event stream each time a query arrives.
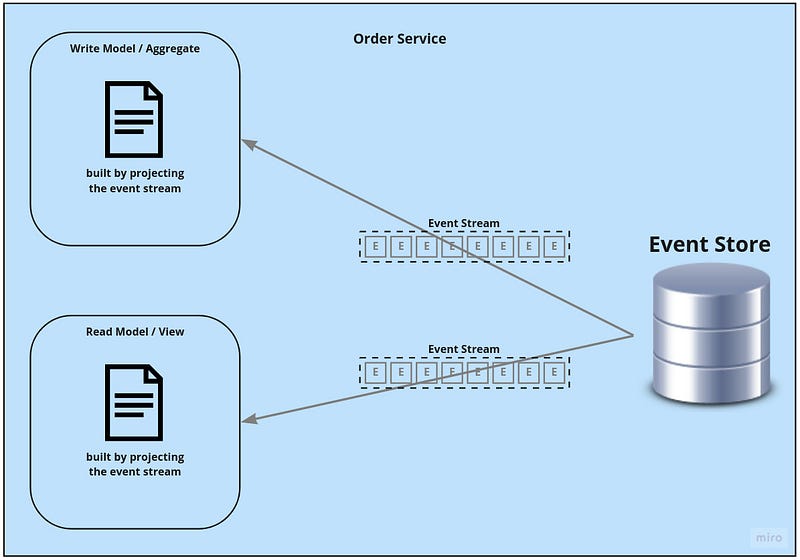
If you wonder why there is an isEmailAddressConfirmed flag in the read model but not in the write model — I’m using the power of the type system here. EmailAddress is just an interface and there are two implementations, ConfirmedEmailAddress and UnconfirmedEmailAddress (Go has no algebraic data types yet).
Advantages
- No extra service is necessary, just some code to implement the http endpoint, the view, and the projections
- The same applies if additional read models should be added
- The deployment of the write model and read model is always atomic
- No eventual consistency but immediate consistency — your product owner and the CTO will love it! ;-)
If that’s not already clear → At the very moment a new event was persisted it will also be contained in the event stream that is loaded to answer an incoming query.
Some words about eventual consistency are needed here. As it turns out, all data is stale at the moment it’s queried. Even the fastest queries will take a single-digit number of microseconds until the data reaches the consumer who issued them. If the consumers are humans they will need something even in the range of seconds to read and process the information, before they can make a decision based on the data. The true difference with live projections is that no stale data will be read, measured from the moment the latest event was stored in the Event Store because it is immediately consistent in the data storage, not more and not less.
Challenges
- Performance and memory consumption might be an issue if the event streams are big
- A workaround could be caching, e.g. by regularly storing snapshots of the read model so that only the events that were recorded after the snapshot have to be projected
This strategy has the same issue as when it is used for the write models — if the structure of the model changes the previous snapshots are worthless and have to be ignored/removed and the service needs a “cache warming” phase with degraded performance. Often this “cache invalidation” is done by versioning those snapshots, so that old versions get invalid. Generally, cache invalidation depends a lot on the implementation, e.g. for local in-memory caches, a restart of the server node after deployment would do the job.
- No independent scaling of write model and read model
Well, actually … why would that matter? If more nodes are needed to scale up queries it should not matter that those nodes also serve the write side. And even if that’s an issue → some routing that separates command and query requests could do the job.
Are live projections still possible if we need to aggregate events from multiple streams?
I will use the following example for the 3 different scenarios which I will show below:
An online shop like Amazon might have a couple of subdomains involved when we order something there: Order, Payment, Shipping, Invoicing
Aggregating some read models into one
With our example, we might want to offer a read model where customers can see all the information about a past or ongoing order.
Often in such a situation, the materialized view implementation is used to aggregate events from multiple write models into one read model and this is indeed a powerful strategy!
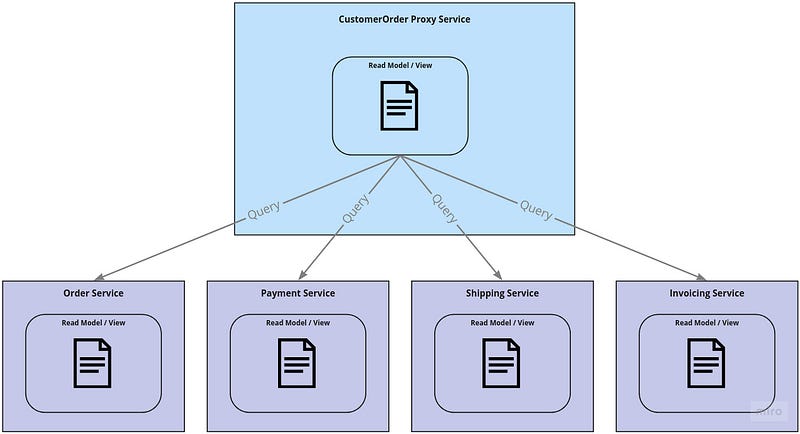
One idea to solve that with live projections is to aggregate the read models for Order, Payment, Shipping, Invoicing with a special query proxy service that queries those fine-grained read models into a CustomerOrder view. We have done that in a previous job with success. But for sure this comes with the extra complexity of another service that might even have shared ownership from multiple teams. Another fact to consider is the synchronous dependency to multiple read model services to serve one query.
Another possibility is to do the aggregation in the client(s) — e.g. website, mobile app, … but the disadvantage is that each client has to implement the same aggregation.
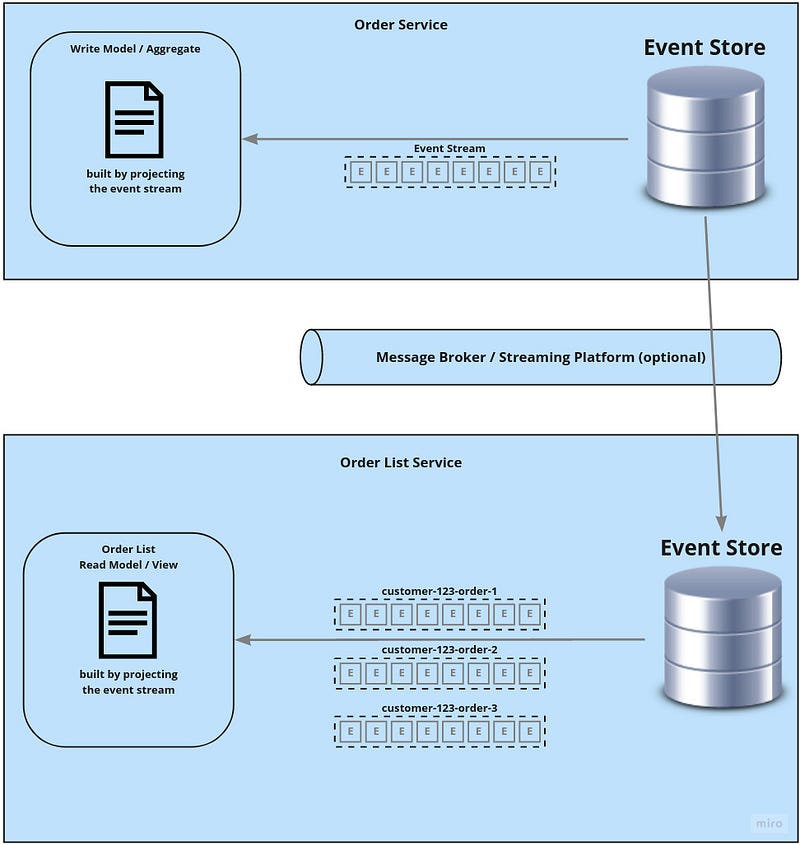
List views
For sure customers also want to see all their past and ongoing orders! So we need to project all their Order streams into one view. So we want to aggregate multiple streams of the same type that belong to one customer.
One possibility to keep most advantages of live projections could be the following:
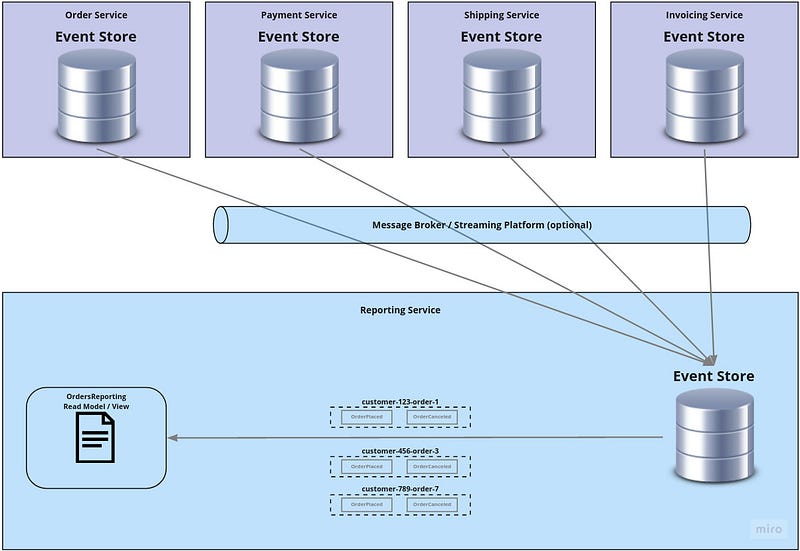
There IS an extra service to serve those reporting models, which consumes events from all involved write models. But instead of materializing the views it just stores those events and then does live projections if queries arrive.
But: This contains a similar challenge as mentioned above for the heavyweight read model implementation. When the reporting model service is deployed the first time — or when additional views need to consume events from write models that were not there from the beginning — then events from one or multiple write models need to be replayed …
We are talking about many events here, so very probably some sort of caching (described above) will be necessary to have decent performance.
Reporting models
“Reporting model” is not an “official” term — I just have no better name.
A read model for reporting could be one that the shop uses to build reports that show e.g.:
- The total monetary volume of orders per day/week/month/year or per country, etc.
- The amount of returned articles per day/week/month/year, …
For this purpose, we want to aggregate certain events types, from one or multiple stream types, related to any customer.
This can be solved with the same strategy described for list views, with the same challenges.
My suggestion — start with live projections, upgrade to materialized view if needed
I think it’s a good idea to start with the live projection strategy that I described and then — if necessary — switch to the full-blown implementation with a separate service for the read model.
The overhead for having the lightweight implementation first should be quite small and the challenge of properly replaying events and the work to invest to implement the heavyweight strategy does not change if you move it to later.
But by postponing it you might save some refinements of the big read model as well as some replay runs that might have been necessary.
Win — Win situation :-)
tl;dr
- Instead of maintaining standalone services for read models — just implement a view (or multiple) in the same service as the write model and live project the events into the view whenever a query comes in
- You’ll never have to explain why eventual consistency is not a problem because your read model is immediately consistent
- This does not work equally well for all types of read models — or rather with extra complexity and costs
- There might be performance issues when event streams are very big or when queries have to be handled extremely fast
Thank you for your time and attention! :-)
Questions and comments are very welcome and I would be very happy if you clap for this article (if you like it) or even follow me on Medium or Twitter! Please consider joining Medium to support my writing! If this article is really valuable for you, you can also tip me on Ko-fi!
Originally published at https://www.eventstore.com/blog/live-projections-for-read-models-with-event-sourcing-and-cqrs




