
Linear layers explained in a simple way
A part of series about different types of layers in neural networks

Many people perceive Neural Networks as black magic. We all have sometimes the tendency to think that there is no rationale or logic behind the Neural Network architecture. We would like to believe that all we can do is just to try a random selection of layers, put some computational power (GPUs/TPUs) to it, and just wait, lazily.
Although there is no strong formal theory on how to select the neural network layers and configuration, and although the only way to tune some hyper-parameters is just by trial and error (meta-learning for instance), there are still some heuristics, guidelines, and theories that can still help us reduce the search space of suitable architectures considerably. In a previous blog post, we introduced the inner mechanics of neural networks. In this series of blog posts we will talk about the basic layers, their rationale, their complexity, and their computation capabilities.
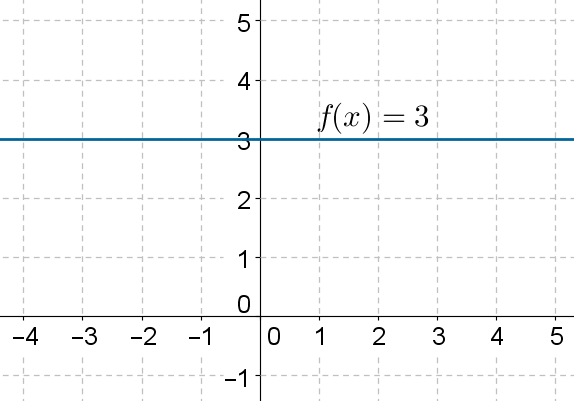
Bias layer
y = b //(Learn b)This layer is basically learning a constant. It’s capable of learning an offset, a bias, a threshold, or a mean. If we create a neural network only from this layer and train it over a dataset, the mean square error (MSE) loss will force this layer to converge to the mean or average of the outputs.
For instance, if we have the following dataset {2,2,3,3,4,4}, and we’re forcing the neural network to compress it to a unique value b, the most logical convergence will be around the value b=3 (which is the average of the dataset to reduce the losses to the maximum. We can see that learning a constant is kind of learning a DC value component of an electric circuit, or an offset, or a ground truth to compare to. Any value above this offset will be positive, any value below it will be negative. It’s like redefining where the offset 0 should start from.
Linear Layer
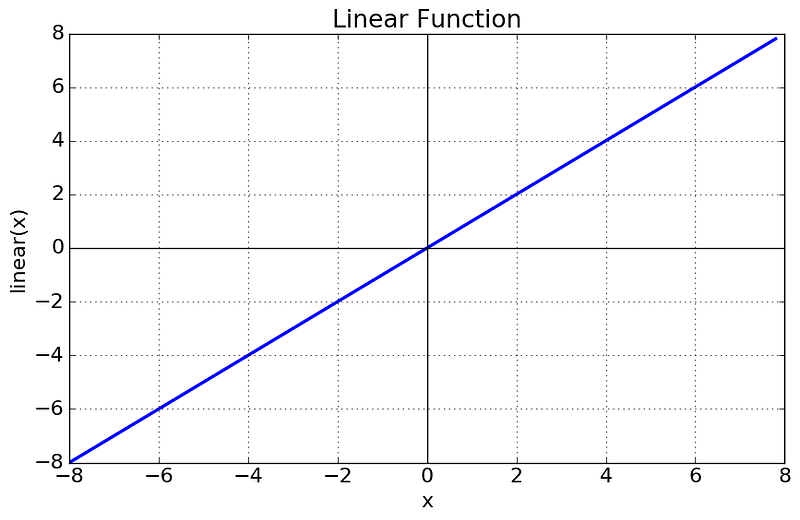
y = w*x //(Learn w)A linear layer without a bias is capable of learning an average rate of correlation between the output and the input, for instance if x and y are positively correlated => w will be positive, if x and y are negatively correlated => w will be negative. If x and y are totally independent => w will be around 0.
Another way of perceiving this layer: Consider a new variable A=y/x. and use the “bias layer” from the previous section, as we said before, it will learn the average or the mean of A. (which is the average of output/input thus the average of the rate to which the output is changing relatively to the input).
Linear Feed-forward layer
y = w*x + b //(Learn w, and b)A Feed-forward layer is a combination of a linear layer and a bias. It is capable of learning an offset and a rate of correlation. Mathematically speaking, it represents an equation of a line. In term of capabilities:
- This layer is able to replace both a linear layer and a bias layer.
- By learning that w=0 => we can reduce this layer to a pure bias layer.
- By learning that b=0 => we can reduce this layer to a pure linear layer.
- A linear layer with bias can represent PCA (for dimensionality reduction). Since PCA is actually just combining linearly the inputs together.
- A linear feed-forward layer can learn scaling automatically. Both a MinMaxScaler or a StandardScaler can be modeled through a linear layer.
By learning w=1/(max-min) and b=-min/(max-min) a linear feed-forward is capable of simulating a MinMaxScaler
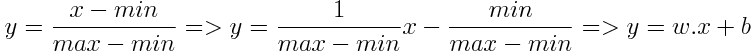
Similarly, by learning w=1/std and b=-avg/std, a linear feed-forward is capable of simulating a StandardScaler
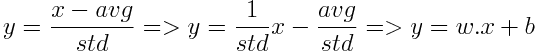
So next time, if you are not sure which scaling technique to use, consider using a feed-forward linear layer as a first layer in the architecture to scale the inputs and as a last layer to scale back the output.

Limitations of linear layers
- These three types of linear layer can only learn linear relations. They are totally incapable of learning any non-linearity (obviously).
- Stacking these layers immediately one after each other is totally pointless and a good waste of computational resources, here is why:
If we consider 2 consecutive linear feed-forward layers y₁ and y₂:
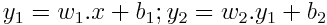
We can re-write y₂ in the following form:
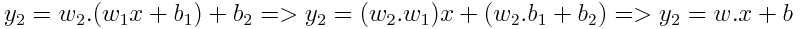
We can do similar reasoning for any number of consecutive linear layers. A single linear layer is capable of representing any consecutive number of linear layers. Basically, for example, scaling and PCA can be combined with one single linear feed-forward layer at the input.
Stacking Linear Layers is a waste of resources! It won’t add you any benefits to stack them.
If you enjoyed reading, follow us on: Facebook, Twitter, LinkedIn





