
Let’s fix MichaelGPT: can you help me?
When you want to build your own AI but it drives you crazy: let’s explore the results and the problems in building your Open Source LLM application.
💡 Disclaimer: this is an experimental article! Sharing the process and the technical issues I faced (but I think any of you may face too…) I would like to get suggestions and help from you too. It can be a Medium community enthusiasts effort to solve a common problem: can we perform as good as OpenAI with Open Source only LLMs?
Introduction
It all started by chance. “Hey Fabio, can you help me out with a LLM project?” Michael C. Carroll dropped me an innocent email, after reading one of my articles and joining the Medium community.
I thought is was going to be an easy feat: I mean, let’s set up an easy chatbot with Streamlit and a RAG strategy (Retrieval Augmented Generation).
After I run some tests I can confidently say that the answer is… actually I don’t know!
- How can I deal with many documents?
- How can I be certain that the answers are correct?
- What if the questions refer to more than one document at the time?
- How long it takes to create the vector index?
And so on… with these kind of questions that I cannot ask any AI… where do I have to start?
My plans where to keep documents and RAG strategy on Michael computer, and move the AI inference somewhere else with an API call (it can even be a Serverless GPU like Beam.cloud)
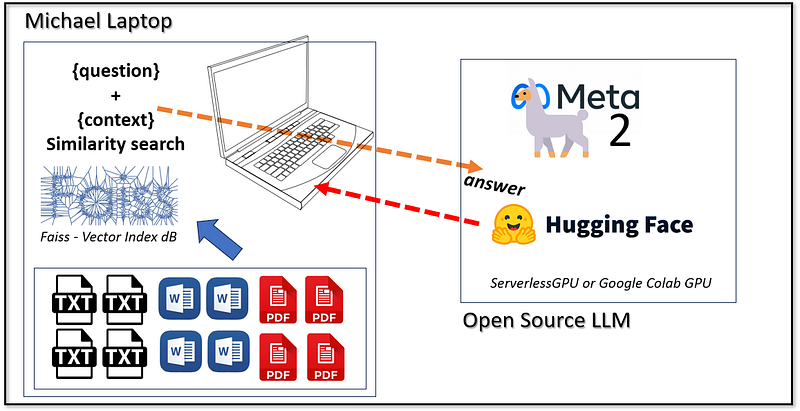
Project goals
Mike is an AI enthusiast. Following many of our Medium articles decided that he wanted to build his own AI.
His project is quite ambitious: “Fabio I have 200 Gb of documents and I would like to be able to ask questions to all of them!”
Before even considering the hardware requirements, the database performances and so on I suggested we proceed step by step: “Sure Mike, let’s start with few documents. Send them to me and give me few questions as an example…”
I mean if I cannot get it right with 5 documents… how can we deal with 100k?
Mike sent me the documents… and the questions

Example of Question: Compare and contrast the Events of Default in the “Third Amendment to Amended and Restated Credit Agreement” with the “Multicurrency Revolving Credit Facility” and then create a table showing the differences in each.
The results below may look amazing, I know…

In summary, the key differences between the Events of Default in the “Third Amendment to Amended and Restated Credit Agreement” and the Multicurrency Revolving Credit Facility are:
- The Schedules and Exhibits to the Credit Agreement shall not be amended, modified, supplemented or otherwise affected in the “Third Amendment to Amended and Restated Credit Agreement.” In contrast, the Multicurrency Revolving Credit Facility may be increased from time to time by the Lender upon written notice to the Borrower, subject to certain conditions.
- The Borrower has the right to request an increase in the Multicurrency Revolving Credit Facility from time to time in the Multicurrency Revolving Credit Facility, while the Lender may elect to increase the Multicurrency Revolving Credit Facility from time to time subject to the Borrower’s consent and satisfaction of certain conditions.
- The Loan Documents may be amended, modified, or supplemented from time to time in the Multicurrency Revolving Credit Facility, while the Schedules and Exhibits to the Credit Agreement shall not be amended, modified, supplemented or otherwise affected in the “Third Amendment to Amended and Restated Credit Agreement.

Prototype setup on Google Colab
As you can imagine I don’t have any special or advanced tools: so I decided to go for Google Colab for prototyping. I mean, even my free tier allows me to have one GPU instance, and it is gold!
The first decision: what embedding?
I did some researches on the Hugging Face Embeddings Leaderboard and from some really cool Medium articles: I decided to use intfloat/e5-base-v2, that has amazing scores with QnA, fast inference and it is not heavy (438 Mb).
🤔 Maybe there is a better or faster embedding… and what about the chunks size?
The chunks size were another turning point: wrongly (I suppose now) I picked up 1000 and overlap 50 for the CharacterTextSplitter. I wanted to preserve the context, but maybe RecursiveCharacterTextSplitter was better and enough at least to preserve the Sentence meaning.
Load and split generated in 0:00:33.426102Second one: what vector store database?
I followed the tutorials on LangChain: Chroma was promising and it can be persistent (saved in the hard disk) and you can add more documents, little by little.
So chunks 1000/50 with Chroma and e5-base-v2 for 5 pdf documents, on Google Colab with only CPU:
Vector db generated in 0:04:01.836045🤔 Do you think a different VectorDB can be better?

The third decision: what LLM?
To run light and with a normal computer in my hands I decided to go with quantized models, so at least I can leverage a 3b, a 7b or even 13 Billion parameter model.
To have flexibility with Langchain I decided to use LlamaCpp with Orca-mini-3b in the q4.0 format, and Llama2–7b-Chat in the q4.1 format.
from langchain.llms import LlamaCpp
from langchain import PromptTemplate, LLMChain
llm = LlamaCpp(
model_path="/content/orca-mini-3b.ggmlv3.q4_0.bin",
n_ctx=2048,
temperature=0.7,
top_k=50,
top_p=1,
)I found Llama2 answers quite coherent and the output was sticking to the requests (for example the markdown format for the tables…)
🤔 Is there any better option?
Last decision: Context window and Prompt
You may have guessed from the code above that I set the context window to 2048. This is the number of tokens that includes the ones in the prompt and the answer. I tried also 4096 with Llama2 but the generation time was almost killing me.
At this point the prompt is also relevant: we must always think about the room available for the reply, particularly if it is a structured reply (like asking for a comparison table in markdown format…)
I used two different templates: one for Orca and one for Llama2 because they come with their own basic Template structure. I tweaked it a bit to include the question and the context:
templateOrca = """
### System:
You are an AI assistant that follows instruction extremely well. Help as much as you can.
### User:
{question}
### Input:
{context}
### Response:
"""
templateLlama2 = """[INST] <<SYS>>
You are a helpful, respectful and honest assistant. Answer exactly in few words from the context
<</SYS>>
Answer the question below from context below :
{context}
{question} [/INST]
"""🤔 Maybe here there is a big room of improvements? What do you think would be a better prompt?

Final remarks… until you help me out
I am a practical guy. So I looked for a way to benchmark the results. I mean, I don’t know anything about the domain knowledge of these documents, but I could use as a KPI the generation time and the instruction following.
- Llama2–7b is more accurate in following the instructions and providing a specific output format
- Llama2–7b generation time is 3 times longer than Orca3b.
- If we increase the context window to 4096 the same question above takes 56 minutes to be replied!
- using chunks of 1000 characters means that we cannot feed more than 3 results coming from the similarity search
- Similarity is not always congruent to Relevance to the topic
Sad reality: MichaelGPT is not really working that good… 😕
Help me to figure out how we can do great things with Open Source LLMs. The literature is not really helping us: it is focused mainly on ChatGPT.
If this story provided value and you wish to show a little support, you could:
- Write a comment with your suggestions to how to fix MichaelGPT
- Sign up for a Medium membership using my link — ($5/month to read unlimited Medium stories)
- Follow me on Medium
- Read my latest articles https://medium.com/@fabio.matricardi
Meantime you can check:
(all images, unless otherwise noted, are by the author)




