
Let us Extract some Topics from Text Data — Part I: Latent Dirichlet Allocation (LDA)
Learn what topic modelling entails and its implementation using Python’s nltk, gensim, sklearn, and pyLDAvis packages

Introduction
Topic modeling is a type of Natural Language Processing (NLP) task that utilizes unsupervised learning methods to extract out the main topics of some text data we deal with. The word “Unsupervised” here means that there are no training data that have associated topic labels. Instead, the algorithms try to discover the underlying patterns, in this case, the topics, directly from the data itself.
There are various kinds of algorithms that are widely used for topic modelling. In the next series of articles, I plan to introduce them one by one. In this article, we look at what the Latent Dirichlet Allocation (LDA) algorithm is, how it works and how to implement it using multiple Python packages.
What is LDA?
LDA is a model for topic modeling that is frequently used owing to its relative simplicity and efficiency compared to, say, extremely convoluted neural networks that might perform the same task.
I will refer to the text data we deal with as the “corpus” and each of the text observation as the “document”. The basic assumption for LDA is that each of the document can be represented by the distribution of topics which in turn can be represented by some word distribution. Please make note of the word “distribution”. LDA assumes that each document is comprised of not just one topic but several topics. Hence, the LDA model will breakdown the percentage contribution of each topic towards that document. For example, if we set the number of topics to be 5, then document A can be denoted like the following:
document_A = 0.2 x Topic1 + 0.1 x Topic2 + 0.1 x Topic3 + 0.5 x Topic4 + 0.1 x Topic5 I will not go into depths of the math of this algorithm but for those are interested, please take a look at this paper from the original inventors of this algorithm.
One heads up I would give to the readers is a warning not to confuse Latent Dirichlet Allocation with the Linear discriminant analysis model which is a classification algorithm since both of them are often abbreviated into LDA.
Now, let us look at some actual code to see how LDA can be implemented.
Cleaning Text
We start by importing the nltk package and downloading a list of relevant corpus that will be used to things like removing stop words, stemming and lemmatization.
import nltkfrom nltk.stem import *nltk.download(‘punkt’) # For Stemmingnltk.download(‘wordnet’) # For Lemmatizationnltk.download(‘stopwords’) # For Stopword Removalnltk.download(‘omw-1.4’)We also store a list of English stop words to be used later in a variable named stopwords.
stopwords = set(nltk.corpus.stopwords.words('english'))It is time to load in some data. Here, we use the open source 20 News Groups dataset that is available to everyone in the sklearn package interface. It uses the Apache Version 2.0 License.
import pandas as pdimport numpy as npfrom sklearn.datasets import fetch_20newsgroupsfetch20newsgroups = fetch_20newsgroups(subset='train')# Store in a pandas dataframedf = pd.DataFrame(fetch20newsgroups.data, columns=['text'])Next, we do some cleaning of text such as removal of some extraneous words or expressions. We remove URLs, mentions and hash tags. To do this, we import the regular expression package and then use the sub function which removes parts of the string that match with the specified regular expression. Remember that “\S” matches a single character other than white space. If you look at the code below, we are matching with expressions including “https”, “@” and “#” which correspond to the strings that we want to remove from the text.
# Remove URLsimport re # Import regular expression packagedef remove_url(text):
return re.sub(r'https?:\S*','',text)df.text = df.text.apply(remove_url)# Remove mentions and hashtagsimport redef remove_mentions_and_tags(text):
text = re.sub(r'@\S*','',text)
return re.sub(r'#\S*','',text)df.text = df.text.apply(remove_mentions_and_tags)Now, we want to tokenize the documents we have and transform them into some dictionary form that can be used as an input for our gensim model.
Pre-Processing
We use the following custom function to pre-process the documents in the corpus.
def text_preprocessing(df): corpus=[]
lem = WordNetLemmatizer() # For Lemmatization for news in df['text']:
words=[w for w in nltk.tokenize.word_tokenize(news) if (w not in stopwords)] # word_tokenize function tokenizes text on each word by default words=[lem.lemmatize(w) for w in words if len(w)>2] corpus.append(words) return corpus# Apply this function on our data frame
corpus = text_preprocessing(df)As you can see from the code above, we are looping over each document and applying tokenization and lemmatization in sequential order. Tokenization means breaking down documents into small units of analysis called tokens which are often words. Lemmatization refers to the process of reverting the words into their original base form called the “lemma”. Changing multiple forms of the same verb depending on its tense into its base form would be an example of lemmatization.
We make use of the gensim package in Python to proceed with steps 3 and further.
Install the gensim package using the following command.
!pip install -U gensim==3.8.3The reason why I am installing a specific version of gensim (3.8.3) is because some of the different LDA implementations such as the LDA Mallet model have been removed in the later versions.
We first create a gensim dictionary object using the corpus that we already pre-processed and then create a variable called “bow_corpus” in which we store the Bag-of-Words (bow) transformed documents. This step is necessary because of the way the gensim package accepts inputs. Then, we save the bow_corpus and dictionary using the pickle package for later use.
import gensim# Transform to gensim dictionary
dic = gensim.corpora.Dictionary(corpus) bow_corpus = [dic.doc2bow(doc) for doc in corpus]import pickle # Useful for storing big datasetspickle.dump(bow_corpus, open('corpus.pkl', 'wb'))dic.save('dictionary.gensim')The Actual Model
Next, we use the LDAMulticore function from the gensim.models class to instantiate our LDA model. Some people may ask what the difference is between the LDAMulticore function and the basic LDAmodel function. They are basically the same but the former supports multi-processing which can save your running time and so why not use it over the basic one? Note that we can specify the number of processors that will participate in the multi-processing operation via the “workers” argument. We also specify the number of topics to be extracted from the corpus through the “num_topics” argument. Unfortunately, there is no way of finding out what number of topics would be the optimal value unless you have some domain knowledge about the corpus beforehand.
lda_model = gensim.models.LdaMulticore(bow_corpus,
num_topics = 4,
id2word = dic,
passes = 10,
workers = 2)lda_model.save('model4.gensim')Once we trained the LDA model, we look at the top ten words that are most important in each topic extracted from the corpus.
# We print words occuring in each of the topics as we iterate through themfor idx, topic in lda_model.print_topics(num_words=10):
print('Topic: {} \nWords: {}'.format(idx, topic))The output is as follows.
Topic: 0 Words: 0.008*"The" + 0.007*"would" + 0.006*"one" + 0.006*"From" + 0.006*"people" + 0.005*"writes" + 0.005*"Subject" + 0.005*"Lines" + 0.005*"Organization" + 0.005*"article"Topic: 1 Words: 0.008*"The" + 0.007*"Subject" + 0.007*"From" + 0.007*"Lines" + 0.007*"Organization" + 0.004*"use" + 0.004*"file" + 0.003*"one" + 0.003*"would" + 0.003*"get"Topic: 2 Words: 0.007*"From" + 0.007*"Organization" + 0.007*"Lines" + 0.006*"The" + 0.006*"Subject" + 0.005*"game" + 0.005*"University" + 0.005*"team" + 0.004*"year" + 0.003*"writes"Topic: 3 Words: 0.013*"MAXAXAXAXAXAXAXAXAXAXAXAXAXAXAX" + 0.009*"The" + 0.006*"From" + 0.006*"Subject" + 0.005*"Lines" + 0.005*"key" + 0.005*"Organization" + 0.004*"writes" + 0.004*"article" + 0.003*"Israel"Maybe topic 2 is somewhat related to the word “University”. Other than that, we do not see anything significant. What is happening here? Notice that there are words that occur very frequently across all the topics. They are words including subject, article, and organization. They are words that are the in the very beginning part of each news article that lists out the author, affiliation and title. This is why they are dominating every topic. In other words, they are uninformative noise that do not add much value to the LDA model we built. This speaks to the importance of text cleaning and pre-processing in tandem with the objective of your NLP project!
Evaluation
As I mentioned earlier, there is no surefire way to find out what number of topics would be optimal. One way is to simply eyeball some key words in each topic to see if they seem coherent with one another. But this is definitely not a objective or rigorous way for evaluation. A slightly more rigorous way is to use the coherence score.
This score measures the degree of semantic similarity between high scoring words in each topic. There exist several algorithms including C_v, C_p, C_uci, C_umass and so on. C_v and C_umass are two of the more widely used approaches.
The coherence score for C_v ranges from 0 to 1 where the higher the value, the better coherence it has. The C_umass method returns negative values. The tricky part here is that there is no clear consensus or interpretation of what value constitutes a “good coherence”. There has been some attempts from scholars such as John McLevey who argued any score above 0.5 for the C_v method is reasonably good. If you peek into some forums for data science, however, there are some varying opinions. This post from Stackoverflow suggests the following rubric.
- 0.3 is bad
- 0.4 is low
- 0.55 is okay
- 0.65 might be as good as it is going to get
- 0.7 is nice
- 0.8 is unlikely and
- 0.9 is probably wrong
For the u_mass method, it gets even more confusing. Take a look at the discussion that happened in this Reddit forum. It says the coherence score can be very volatile as we increase the number of topics to be extracted. The general idea most data science users are suggesting I think is that the C_v method is usually more reliable than the C_umass method although the final verdict is on the user.
Nevertheless, I think the key takeaways from all these information on coherence evaluation are:
- Coherence score is not an absolute metric for evaluating the quality of the topics modeled. Never rely on one method alone. Use the coherence score as a baseline and then make sure you eye ball through the documents in each topic and their key words to get your “own” sense of the degree of coherence in each topic.
- For the C_v method for calculating the coherence score, check if the score of your model is neither too high nor too low. Anywhere between 0.5 and 0.7 would a decent range.
- For the C_umass method for calculating the coherence score, check if the absolute value of the score is reasonably close to 0.
Let us evaluate our model using the C_v method. The gensim package’s models class contains the CoherenceModel which comes in handy for calculating coherence scores.
from gensim.models import CoherenceModel# instantiate topic coherence modelcm = CoherenceModel(model=lda_model, corpus=bow_corpus, texts=corpus, coherence='c_v')# get topic coherence scorecoherence_lda = cm.get_coherence()print(coherence_lda)
>> 0.497257063604814750.497 is not bad but not decent either. We want to know if the coherence score varies depending on the number of topics to be extracted from the corpus. We iterate from numbers 2 to 6 for the number of topics and store each coherence score in the variable called score which is initialized as an empty list. We then visualize this into a line graph using Python’s matplotlib package.
import matplotlib.pyplot as plttopics = []score = []for i in range(2,7,1):
lda = gensim.models.LdaMulticore(corpus=bow_corpus, id2word=dic, iterations=10, num_topics=i, workers = 3, passes=10, random_state=42) cm = CoherenceModel(model=lda, corpus=bow_corpus, texts=corpus, coherence='c_v') topics.append(i) # Append number of topics modeled score.append(cm.get_coherence()) # Append coherence scores to listplt.plot(topics, score)plt.xlabel('# of Topics')plt.ylabel('Coherence Score')plt.show()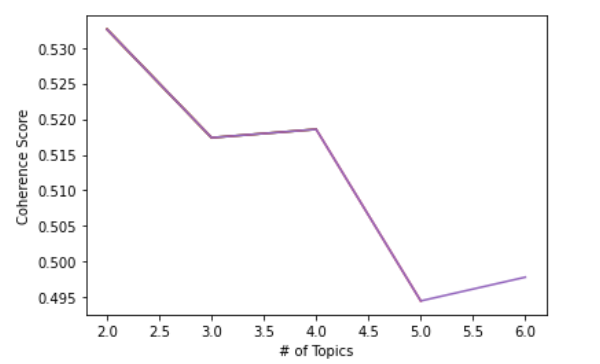
We see that the coherence score the highest when there are two topics to be extracted. It constantly decreases as the number of topics increases.
We build the new LDA model based on two topics now.
# LDA model with two topics
lda_model2 = gensim.models.LdaMulticore(bow_corpus,
num_topics = 2,
id2word = dic,
passes = 8,
workers = 3)lda_model2.save('model2.gensim')
# We print words occuring in each of the topics as we iterate through themfor idx, topic in lda_model2.print_topics(num_words=20):print('Topic: {} \nWords: {}'.format(idx, topic))Resulting Output:
Topic: 0 Words: 0.007*"The" + 0.005*"MAXAXAXAXAXAXAXAXAXAXAXAXAXAXAX" + 0.004*"From" + 0.004*"Subject" + 0.004*"Lines" + 0.004*"Organization" + 0.003*"one" + 0.002*"get" + 0.002*"year" + 0.002*"game" + 0.002*"like" + 0.002*"would" + 0.002*"time" + 0.002*"University" + 0.002*"writes" + 0.002*"team" + 0.002*"article" + 0.002*"dont" + 0.002*"This" + 0.002*"people" Topic: 1 Words: 0.009*"The" + 0.007*"From" + 0.007*"Subject" + 0.007*"Lines" + 0.007*"Organization" + 0.005*"would" + 0.005*"writes" + 0.005*"one" + 0.004*"article" + 0.003*"people" + 0.003*"know" + 0.003*"like" + 0.003*"University" + 0.003*"dont" + 0.003*"get" + 0.003*"think" + 0.002*"This" + 0.002*"use" + 0.002*"time" + 0.002*"say"The output above shows that topic 0 is somewhat related to games and teams while topic 1 is more associated with action verbs including know, like, use and say. Since we have not removed those frequently appearing pronouns or articles that only serve their grammatical purposes but do not add much meaning or value to the model, the noise is still pretty rampant in both topics. Nevertheless, even with eye balling, we can get a slightly better sense of what each of the topics is about which usually suggests better coherence.
Visualizing LDA Results
Using another package called pyLDAvis, we can visualize the LDA results.
!pip install pyldavisimport pyLDAvisimport pyLDAvis.gensim_modelsPlease note that there has been an update to the pyLDAvis package and so the pyLDAvis.gensim module people used to know has now become pyLDAvis.gensim_models instead.
# Loading the dictionary and corpus files we saved earlier
dictionary = gensim.corpora.Dictionary.load('dictionary.gensim')corpus = pickle.load(open('corpus.pkl', 'rb'))# Loading the num_of_topics = 2 model we saved earlier
lda = gensim.models.ldamodel.LdaModel.load('model2.gensim')pyLDAvis.enable_notebook()vis = pyLDAvis.gensim_models.prepare(lda, bow_corpus, dic, sort_topics=False)pyLDAvis.display(vis)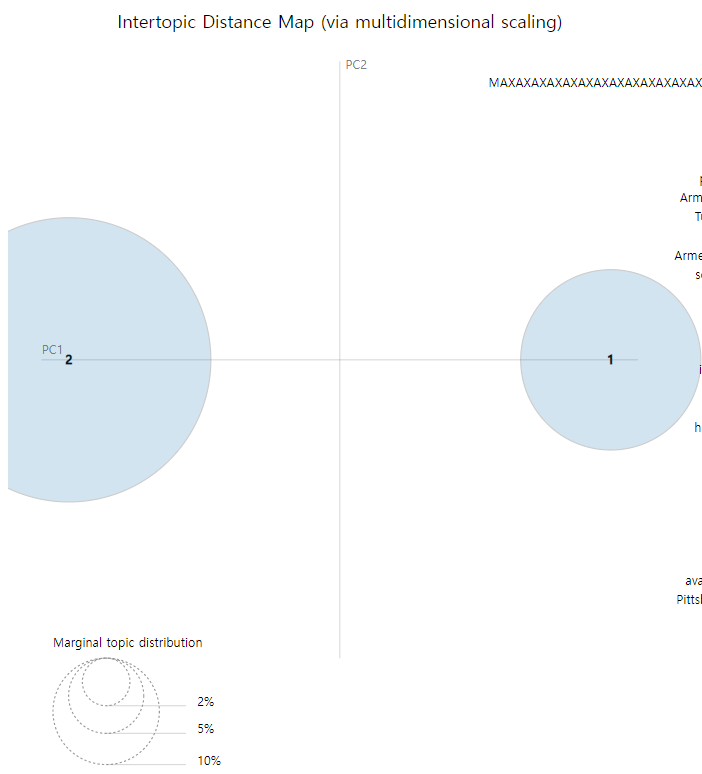
On the left side of the the pyLDAvis dashboard which I have screenshot above, the area of each circle represents the importance of the topic relative to the corpus. In addition, the distance between the center of the circles indicates the similarity between the topics.
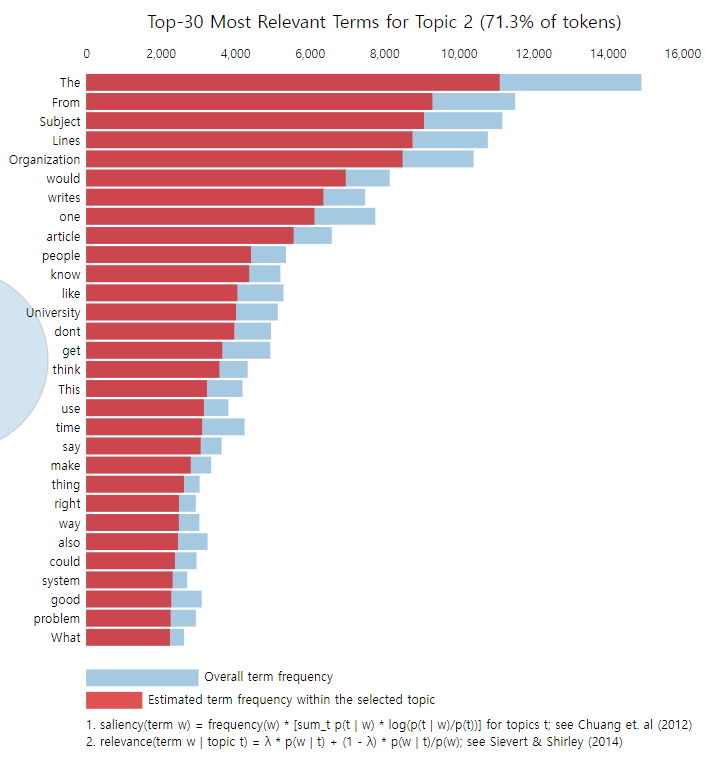
Now on the right side of the dashboard, as you see right above, the top 30 relevant words of each topic are displayed in a histogram with the red portion of the bar representing the estimated term frequency within the selected topic (saliency) and the light blue portion representing the overall term frequency.
Bonus
LDA has various versions. LDA Mallet, for instance, is another version of LDA that uses Gibbs Sampling which improves performance compared to the plain LDA model I showcased above. One downside of the LDA Mallet model is its computational inefficiency relative to its original counterpart and so for huge datasets, it may not be the most suitable.
Please take a look at the last part of this article to get to know more about the LDA Mallet model.
Conclusion
In this article, I introduced to you what topic modeling is and what the LDA model can do to perform topic modeling. I also walked you through step by step on how to clean and pre-process text data and then build the LDA model on top of it. Lastly, I elaborated on how to evaluate your LDA model and how to visualize the results.
One main point that the readers should bear in mind is that pre-processing is more important than you think to increase topic coherence. Some ways to ensure not too much noise is in the text data is to filter out extremely high or low frequency tokens and exclude specific Part-of-Speech (PoS) tagged words such as IN (e.g. upon, except) and MD (e.g. may, must). The latter, of course, must be preceded with the PoS tagging which is a separate NLP task in itself which I will introduce in another article.
If you found this post helpful, consider supporting me by signing up on medium via the following link : )
You will have access to so many useful and interesting articles and posts from not only me but also other authors!
About the Author
Data Scientist. 1st Year PhD student in Informatics at UC Irvine.
Former research area specialist at the Criminal Justice Administrative Records System (CJARS) economics lab at the University of Michigan, working on statistical report generation, automated data quality review, building data pipelines and data standardization & harmonization. Former Data Science Intern at Spotify. Inc. (NYC).
He loves sports, working-out, cooking good Asian food, watching kdramas and making / performing music and most importantly worshiping Jesus Christ, our Lord. Checkout his website!





