
Lessons Learned from Tic-Tac-Toe: Practical Reinforcement Learning Tips
A look-back at all the things I did wrong when developing my first Reinforcement Learning agent, so you can get it right

Just recently I posted an introduction post to Reinforcement Learning and Deep Q Networks. But as we all know, there’s a huge difference between understanding the theory and actually implementing it in the real world.
It took me a while to find what would be a worthy first challenge for DQN. Most tutorials I saw implemented a DQN + Convolutional nets, and attempted to design an agent that beats Atari or Doom games. This seemed like a distraction: I didn’t see any point of wasting time on designing image-processing networks to solve a Reinforcement problem. And this is why I picked Tic-Tac-Toe: it’s rather simple, so I can train it on my MacBook, no image processing is required as I can code the game, and yet it still requires strategy design in order to win.
Though I thought it will be straight-forward and simple, it didn’t took me long to realize I was wrong — and so, I’d like to describe some of the most important lessons I learned while solving this challenge. The code, by the way, can be found on my GitHub page.
1. Break it down to the simplest tasks possible
As obvious as it sounds, this is something we all tend to forget every once in a while. If you’ve read my introduction to DQN, you might remember I gave as a “Hello World” exercise a very-very simple game: an agent that needs to fill empty slots (and if you haven’t — no worries, we’ll come back to it very soon). I didn’t come up with this exercise out of thin air.
When I decided to implement Tic-Tac-Toe, I sat down and wrote pretty much all the code required at once: Game class, Player class, Experience Replay class, Q Network class, Double Deep Q Network implementation — and pushed play. Guess what? It didn’t learn a thing. Not even what are valid or invalid moves, which is the absolute basics of doing anything.
Now go figure what’s causing this — is it the way I represent the states? Is it a hyperparameters issue? Is there a bug in the code? If so, where? So many possibilities to make mistakes, and no idea where to start.
So I’ve decided to strip it down to the simplest issue I had: the agent can tell apart valid moves from invalid? Then let’s train an agent that only learns to tell apart vacant from non-vacant slots. Nothing else. This quickly proved itself, as I was able to isolate and fix several bugs in my network implementation. Yet still, the agent refused to learn. As now the network was implemented correctly, it took me a while to realize what I was missing:
2. Simple tasks are simple only to you
As mentioned, the simple task I gave the agent was to fill in all vacant spots of a 4 cells board. An empty cell is represented by “0” and a filled cell by “1”. How many games would you need to play till you understand the logic? Probably not too many. But you’re human, and the computer isn’t.

I thought that a few hundreds games should be enough, but it turned out that my implementation required around 2500 games to master this. It turned out that 100–200 games were so insufficient, that the cost barely changed. To make it even more confusing, the cost was really low — but as I figured out later, that was due to network cold-start and insufficient number of trainings (see my implementation). Basically, I didn’t give the network enough trainings to learn anything — because I underestimated how hard it will be for the agent to learn this.
Bottom line — what seems simple to us as humans might not be simple at all for computers (and vice versa — how much time will it take you to calculate 147x819?). Train the model longer.
3. How (not) to define the next state
At this point I was able to go back to the Tic-Tac-Toe challenge. The network was working, and the agent was learning. I could easily see it picked up on which moves are valid and which aren’t, and when I examined how it plays, it was obvious it learned how to win — its attempts to make 3-in-a-row were crystal clear, and I was happy — but not too much. Despite what it learned, it was also clear he paid no attention to what his opponent was doing, and made no efforts to try and block his opponent from having 3-in-a-row. No matter how long I trained it, how many layers I added to the net or how much I tuned the hyperparameters — nothing changed that.
It took me longer than I thought to realize what I was doing wrong. And it had a lot to do with the fact that pretty much all code examples of DQN I saw were of single-player games — I had no idea how to tackle the multiplayer case. It was only when I found this guy’s game implementation that I understood what I did wrong — and for this I’ll have to explain how I designed the game. Take a look at the game described below:

Transitions to odd states are performed by player X, and to even states by player O. This is exactly how I added records to the memory buffer of the model: if s=0 and player X chose the left-middle cell, then s’=1. Player O then received state s=1 and made a transition to s=2. These were two separate records I added to the model’s Experience Replay memory.
But that means a player can never lose when it’s his turn to play. Let’s look at s=3: player O chose the top-middle cell and transitioned to s=4. He didn’t lose yet. Now it’s player X’s turn, he makes the obvious choice and transitions to s=5, and wins. Only now does player O knows he lost — and so, in order to have better judgement next time, the negative reward player O receives at s=5 needs to propagate two states backwards, to the Q Values of s=3. Theoretically, this shouldn’t be a problem due to the recursivity of Bellman Equation and repeated training of the network. Theoretically.
In practice, that doesn’t work — and for two reasons, I believe. The first, and the more intuitive one, is that the model saw no risk in transitioning from s=3 to s=4, because it didn’t know it is not him who chooses how to transition from s=4. As far as the model knew, he can simply choose a different action when in s=4, preventing him from losing.
Once I realized this, fixing was easy — all I needed to do is define the next state as the next board representation the player will see — so for player O, if s=3 and the action is top-middle cell, then s’=5 and not 4 — and now the model can learn that this action will cause him to lose the game.
And what’s the second reason? well —
4. Remember the network is only an approximation
Several times during this debugging process, I examined the Q Values the network learned, trying to see if maybe this will assist in finding what I was doing wrong. It took me a while to realize this is pointless, and I’ll explain why.
This might be a good point to go back to my solution of the “fill the board” example I described above. If you go over the Q-Table and Q-Network algorithms I implemented there, you can see I plotted the predictions of all Q Values when testing them. The Q Values of the table make sense (despite being a little off sometimes due to “roads less taken” during training) — but that’s not the case with the Q-Network predicted values. These have absolutely nothing to do with the ones computed by the table algorithm.
And when you think about it, that’s actually not that surprising. Remember the network is only an approximation — and what you actually asking it to do is to predict the best action, which corresponds to the highest Q Value it predicted. Think about it for a second: you don’t really ask the network to learn the correct Q Value, but only that the best action will have the highest predicted value. And these are two completely different things. The network’s inability to predict correct Q Values makes even more sense when you remember that the cost function uses the network’s own predictions when minimizing — it has no ground truth to compare to. Here it is as a reminder:
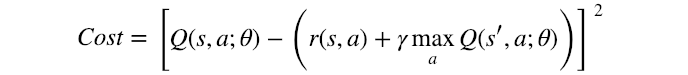
I guess the key message here is that while they’re called Deep Q-Network, the Q Values are not what they actually learn. Confusing, but that’s life.
Final words
Implementing theoretical knowledge is one of the greatest challenges when discovering new fields. Knowing how it works is not the same as making it work. I hope this post will assist you on you journey in Reinforcement Learning and Deep Q-Networks, and I’d be more than happy to hear about your lessons-learned when developing your own algorithms. Make it happen.
