
Learning to Rank: RankNet, LambdaRank, and LambdaMART
In this note, we are revisiting “Learning to Rank” problem. In particular, we review the fundamental elements of famous ranking algorithms, namely RankNet, LambdaRank, and LambdaMART. Most of the content of this story is adapted from Microsoft Research Technical Report MSR-TR-2010–82 by Christopher J.C. Burges [1]. Here, I am trying to focus more on the mathematical side of the ranking algorithms (see [3] for an intuitive introduction to “Learning to Rank” class of problems).

Motivation
Learning to Rank (LTR) aims at studying methods that can provide an optimal ordering (ranking) of pages for a given query. LTR is commonly used in search engine ranking to produce a ranked list of pages. Examples are everywhere from Google suite search engine to travel booking websites like Booking.com, Priceline, and Kayak.
RankNet
Let us consider the training data partitioned for a given query Q. Consider a pair of URLs U_i and U_j with differing labels feature vectors x_i and x_j, respectively [1]. The model outputs the scores s_i = f(x_i) and s_j = f(x_j). Without loss of generality, let us say that for the query Q, U_i should be ranked higher than U_j, because of their relative labels. This event is shown by U_i ▷ U_j, i.e., U_i should be ranked higher than U_j. Using a sigmoid function, the models scores are mapped to a learned probability that U_i ▷ U_j [1]:
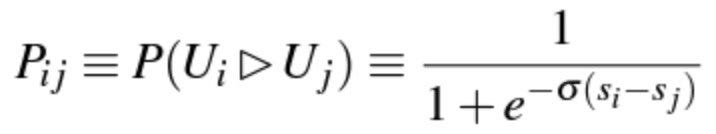
Applying the cross entropy cost function, one obtains [1]
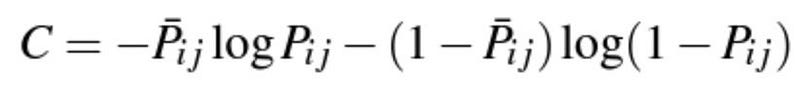
where \bar{P}_{ij} is the known probability for the event U_i ▷ U_j . Let us assume that \bar{P}_{ij} is expressed in terms of S_{ij} = {0,+1,-1}, for the three events that U_i ▷ U_j (S_{ij} = +1), U_j ▷ U_i (S_{ij} = -1), and U_i = U_j (S_{ij} = 0), and thus, \bar{P}_{ij} = 1/2 (1 + S_{ij}). Therefore [1],
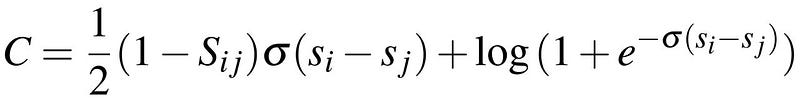
Thus
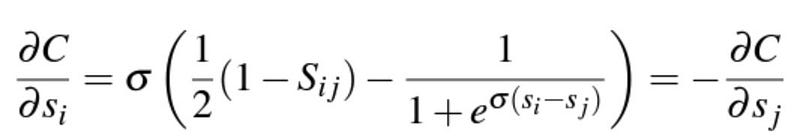
Factoring RankNet: Speeding Up RankNet Training
One can write the partial derivative of the cost function in terms of a model weight as follows [1]
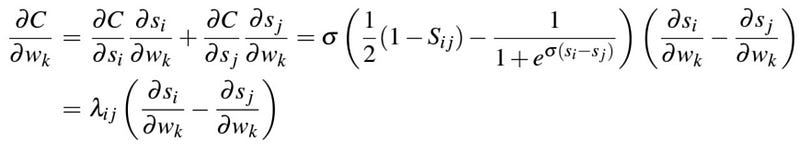
where \lambda_{ij} is defined as
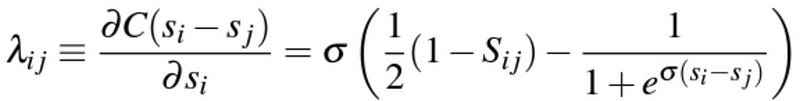
Note that the above formulation is also fundamental to LambdaRank [1, 4] and is going to show up there again. SGD update gives
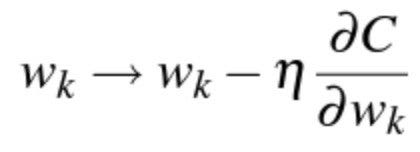
Loss for a set of pairs
We are now putting it together and find the update rule for a set of pairs I, where we adopt the convention that it contains pairs of indices {i, j}, where U_i ▷ U_j . Hence, one can simply show that [1]
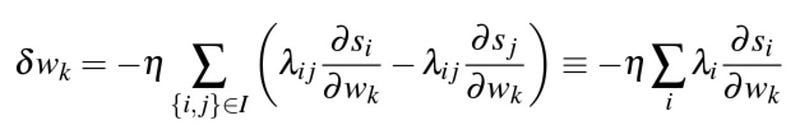
Such that
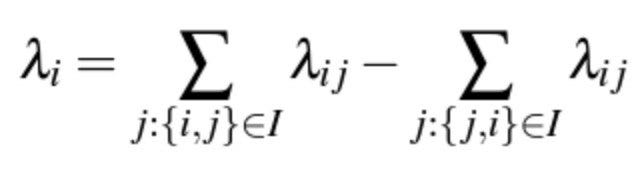
Information Retrieval Measures
The next question that we need to answer is about scoring the output of LTR models. Let us say we are given two different list of ranked pages for a given query, how do we figure out which one is better? Or, how do we attribute a score to each output? There are many metrics to explore, namely Mean Reciprocal Rank (MRR), Mean Average Precision (MAP), Expected Reciprocal Rank (ERR), and Normalized Discounted Cumulative Gain(NDCG) [1]. The Discounted Cumulative Gain (DCG) is defined as
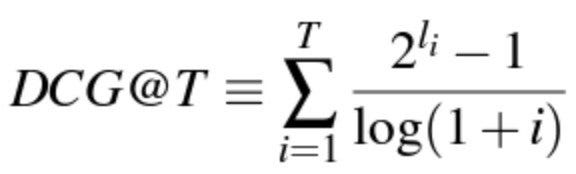
where T is the truncation level and l_i is the label of the ith page/url. With its normalized version, i.e., (NDCG) given by
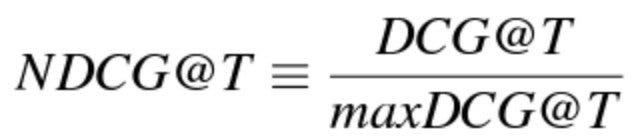
There exist also another method known as ERR, which is more useful under the scenario that a user would check and read down the list of pages until he or she finds the desired one.
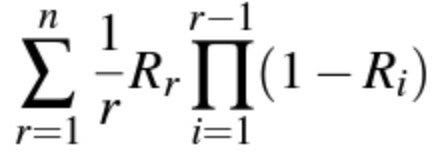
where
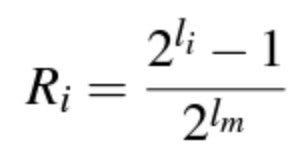
LambdaRank
LambdaRank method takes into consideration the key observation that for the purpose of model training, one only needs the gradients of the cost function and not necessarily costs themselves [1]. It turns out that one can get pretty good results by modifying Equation (***) that was derived in the previous section. By an abuse of notation, we switch from cost “C” to a utility function “C” that we want to maximize as a measure of goodness instead of minimize as a measure of error, and thus,
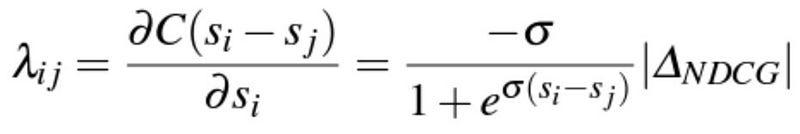
Notice that the definition of \lambda_{ij} in Equation (***) was multiplied by ∆_{NDCG}. Accordingly, the weight update rule becomes
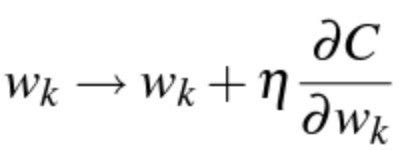
LambdaMART
The idea of LambdaMART is to combine LambdaRank and MART (Multiple Additive Regression Trees) (see [1, 3, 5]). In LambdaMART each tree learns \lambda_i for the whole dataset instead of a single query. Similar to Equation (★), we can express \lambda_{ij} as [1]
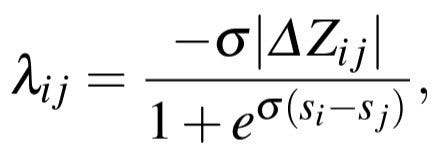
Here Z_{ij} is the utility function for swapping U_i and U_j similar to ∆_{NDCG} in LambdaRank. Again, by an abuse of notation, we may obtain a utility function “C” as
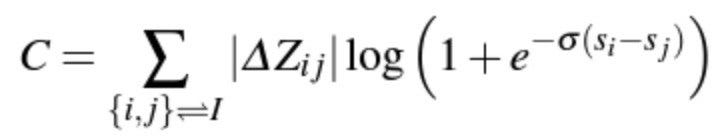
After some algebraic manipulations, [1] finds the Newton step size for a given leaf of a given tree. The algorithm is summarized below:

Conclusions
Finally, it turns out that there are many limitations associated with the methods described in this note, namely RankNet, LambdaRank, and LambdaMART. For one, the implicit user feedback is heavily biased. For instance, one type of bias is position bias that arises due to the fact that users tend to pay more attention to higher ranked documents which heavily affects the collected data and experiments [6].
Therefore, in the next LTR stories, we focus on Unbiased Learning to Rank approaches [6]. In particular, we carefully study Counterfactual LTR and Online LTR methods. Finally, we put everything together by studying the LambdaLoss paper [7] and its treatment of loss function to be optimized over entire training set.
References
[1] Burges CJ. From RankNet to LambdaRank to LambdaMART: An overview. Learning. 2010 Jun 23;11(23–581):81.
[2] Cao, Zhe, et al. “Learning to rank: from pairwise approach to listwise approach.” Proceedings of the 24th international conference on Machine learning. 2007.
[3] Intuitive explanation of Learning to Rank (and RankNet, LambdaRank and LambdaMART), (Link).
[4] C.J.C. Burges, R.Ragno and Q.V. Le. Learning to Rank with Non-Smooth Cost Functions. Advances in Neural Information Processing Systems, 2006.
[5] Q. Wu, C.J.C. Burges, K.Svore and J.Gao. Adapting Boosting for Information Retrieval Measures. Journal of Information Retrieval, 2007.
[6] Oosterhuis, Harrie, Rolf Jagerman, and Maarten de Rijke. “Unbiased learning to rank: counterfactual and online approaches.” Companion Proceedings of the Web Conference 2020. 2020.
[7] Wang, Xuanhui, et al. “The lambdaloss framework for ranking metric optimization.” Proceedings of the 27th ACM international conference on information and knowledge management. 2018.





