
layer-wise inference to effectively run 70B LLM on your local machine
The art of running Mega language model on your local machine
It is well known that extensive GPU resources are necessary to operate large language models.
A question that arises is whether these models can perform inference with just a single GPU, and if yes, what the least amount of GPU memory required is.
Consider a language model with 70 billion parameters; its parameters alone take up 130GB of space. Merely initializing the model on a GPU demands two A100 GPUs with a capacity of 100GB each.
When the model processes input sequences during inference, the memory consumed escalates dramatically due to intricate “attention” computations. Furthermore, the memory needed for these attention processes increases quadratically with the expansion of the input sequence. So, in addition to the model’s 130GB, an ample amount of additional space is indispensable.
Now, the intriguing discussion is about the strategies that allow for this remarkable memory conservation and permit running inference on a mere 4GB GPU without degrading the model’s performance through compression techniques like quantization, distillation, or pruning.
In this article, I shed light on the innovative methods used to drastically save memory while working with colossal models.
A concluding section of this article will introduce you to an open-source solution that simplifies this task with minimal code.
layer-wise inference:
Layer-wise inference leverages the one-directional nature of forward propagation during inference; as each layer completes its computation and passes the output forward, its memory allocation can be released, since it is no longer needed. This cyclical processing of layers allows for consecutive memory cleanup and efficient resource utilization.
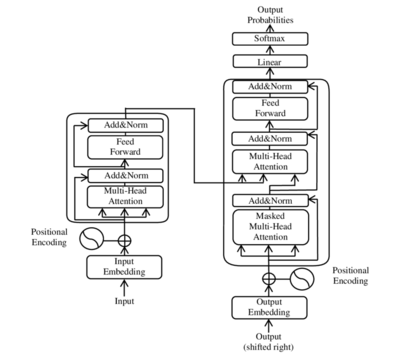
The framework of sizeable language models, especially contemporary ones that use the Multi-head self-attention format initially presented in the “Attention is all you need” paper by Google, is quite standardized. This structure is what’s popularly known as the Transformer model.
A large language model starts with an embedding projection layer, followed by numerous transformer layers, all identical, usually amounting to a total of 80. The end of the model consists of a normalization layer and a fully connected layer that determines the probabilities for the next token.
Sequential layer execution is employed during inference: the output from one layer becomes the input for the next, with only one layer being processed at a time.
It’s thus unnecessary to keep every layer loaded in GPU memory simultaneously. It’s more efficient to load the required layer from storage when it’s turn for processing comes, perform the calculations, and then clear the memory used.
As a result, GPU memory is only taxed with the parameter size of a single transformer layer, approximately 1/80th of the full model, or around 1.6GB.
Additionally, various output caches need to be held in GPU memory, among which the KV cache is the largest, put in place to preclude repetitive computations.
For instance, the KV (key-value pairs) cache for a 70 billion parameter model with an input length of 100 would be approximately:
2 * input_length * num_layers * num_heads * vector_dim * 4
This results in the KV cache demanding about 30MB of GPU memory.
Monitoring tools have recorded the complete inference process taking up less than 4GB of GPU memory.
‘Flash Attention’ optimization:
Then there’s the ‘Flash Attention’ optimization. It stands as a significant enhancement within the domain of large language models, which tend to run on a common codebase. Flash Attention substantially upgrades the memory usage pattern.
Flash Attention borrows from the research paper titled “Self-attention Does Not Need O(n²) Memory”, which dispels the necessity for maintaining O(n²) intermediary outcomes by advocating for their sequential computation, and continuously updating a single result while discarding the rest, reducing memory complexity down to O(logn).
Flash Attention takes a somewhat different approach, possessing a slightly higher memory complexity of O(n) but profoundly optimizing CUDA memory access, which results in a significant speed increase for both inference and training.
Flash Attention computes in small segments, reducing the requisite memory to the size of one segment, compared to storing O(n²) intermediate results in traditional self-attention mechanisms.
Partitioning of the model file:
The next strategic move involves the partitioning of the model file. Typically, the original model file is divided into chunks of around 10GB each. Given that each layer equates to around 1.6GB, loading a full 10GB shard for every layer’s computation leads to an inefficient utilization of memory and disk resources, since disk read speeds often form the bottleneck.
To address this, the original HuggingFace model file is restructured into layer-specific shards.
For storing these shards, we turn to safetensor technology. This storage format closely aligns with the in-memory format and utilizes memory mapping to optimize load speed.
In terms of implementation, the HuggingFace Accelerate library’s meta device is utilized. The meta device serves as a virtual device, permitting the operation of notably large models. When a model is loaded via the meta device, the actual model data isn’t immediately read into memory; instead only code is loaded, effectively reducing memory usage to zero. Parts of the model can be dynamically moved from the meta device to physical devices like the CPU or GPU during execution.
The class:
# Class for sharded llama
class ShardedLlama:
def __init__(self, checkpoint_path, weights_loader, device="cuda:0", dtype=torch.float16):
"""
Sharded version of LlamaForCausalLM : the model is splitted into layer shards to reduce GPU memory usage.
During the forward pass, the inputs are processed layer by layer, and the GPU memory is freed after each layer.
To avoid loading the layers multiple times, we could save all the intermediate activations in RAM, but
as Kaggle accelerators have more GPU memory than CPU, we simply batch the inputs and keep them on the GPU.
Parameters
----------
checkpoint_path : str or Path
path to the checkpoint
weights_loader : WeightsLoader
object to load the weights
device : str, optional
device, by default "cuda:0"
dtype : torch.dtype, optional
dtype, by default torch.float16
"""
# Save parameters
self.checkpoint_path = Path(checkpoint_path)
self.weights_loader = weights_loader
self.device = device
self.dtype = dtype
# Create model
self.config = AutoConfig.from_pretrained(self.checkpoint_path)
self.tokenizer = AutoTokenizer.from_pretrained(checkpoint_path)
self.tokenizer.pad_token = self.tokenizer.eos_token
self.tokenizer.padding_side = "right"
self.init_model()
self.layer_names = ["model.embed_tokens"] + [f"model.layers.{i}" for i in range(len(self.model.model.layers))] + ["model.norm", "value_head"]
def init_model(self):
# Load meta model (no memory used)
with init_empty_weights():
self.model = AutoModelForCausalLM.from_config(self.config)
self.model.lm_head = torch.nn.Linear(8192, 8, bias=False) # originally 32k
self.model.eval()
self.model = BetterTransformer.transform(self.model) # enable flash attention
self.model.tie_weights()
self.layers = [self.model.model.embed_tokens] + list(self.model.model.layers) + [self.model.model.norm, self.model.lm_head]
# Move buffers to device (not that much GPU memory used)
for buffer_name, buffer in self.model.named_buffers():
set_module_tensor_to_device(self.model, buffer_name, self.device, value=buffer, dtype=self.dtype)
def load_layer_to_cpu(self, layer_name):
self.weights_loader.set_state_dict(layer_name, self.device)
state_dict = self.weights_loader.get_state_dict(self.device)
if "value_head.weight" in state_dict:
state_dict = {"lm_head.weight" : state_dict["value_head.weight"]}
return state_dict
def move_layer_to_device(self, state_dict):
for param_name, param in state_dict.items():
assert param.dtype != torch.int8, "int8 not supported (need to add fp16_statistics)"
set_module_tensor_to_device(self.model, param_name, self.device, value=param, dtype=self.dtype)
def __call__(self, inputs):
# inputs = [(prefix, suffix), ...] with prefix.shape[0] = 1 and suffix.shape[0] = 5
# Reboot the model to make sure buffers are loaded and memory is clean
del self.model
clean_memory()
self.init_model()
# Send batch to device
batch = [(prefix.to(self.device), suffix.to(self.device)) for prefix, suffix in inputs]
n_suffixes = len(batch[0][1])
suffix_eos = [(suffix != self.tokenizer.pad_token_id).sum(1) - 1 for _, suffix in inputs]
# Create attention mask for the largest input, and position ids to use KV cache
attention_mask = torch.ones(MAX_LENGTH, MAX_LENGTH)
attention_mask = attention_mask.triu(diagonal=1)[None, None, ...] == 0
attention_mask = attention_mask.to(self.device)
position_ids = torch.arange(MAX_LENGTH, dtype=torch.long, device=self.device)[None, :]
with ThreadPoolExecutor() as executor, torch.inference_mode():
# Load first layer
future = executor.submit(self.load_layer_to_cpu, "model.embed_tokens")
for i, (layer_name, layer) in tqdm(enumerate(zip(self.layer_names, self.layers)), desc=self.device, total=len(self.layers)):
# Load current layer and prepare next layer
state_dict = future.result()
if (i + 1) < len(self.layer_names):
future = executor.submit(self.load_layer_to_cpu, self.layer_names[i + 1])
self.move_layer_to_device(state_dict)
# Run layer
for j, (prefix, suffix) in enumerate(batch):
if layer_name == "model.embed_tokens":
batch[j] = (layer(prefix), layer(suffix))
elif layer_name == "model.norm":
# Only keep the last token at this point
batch[j] = (None, layer(suffix[torch.arange(n_suffixes), suffix_eos[j]][:, None]))
elif layer_name == "value_head":
batch[j] = layer(suffix)[:, 0].mean(1).detach().cpu().numpy()
else:
# Run prefix
len_p, len_s = prefix.shape[1], suffix.shape[1]
new_prefix, (k_cache, v_cache) = layer(prefix, use_cache=True, attention_mask=attention_mask[:, :, -len_p:, -len_p:])
# Run suffix
pos = position_ids[:, len_p:len_p + len_s].expand(n_suffixes, -1)
attn = attention_mask[:, :, -len_s:, -len_p - len_s:].expand(n_suffixes, -1, -1, -1)
kv_cache = (k_cache.expand(n_suffixes, -1, -1, -1), v_cache.expand(n_suffixes, -1, -1, -1))
new_suffix = layer(suffix, past_key_value=kv_cache, position_ids=pos, attention_mask=attn)[0]
batch[j] = (new_prefix, new_suffix)
# Remove previous layer from memory (including buffers)
layer.to("meta")
clean_memory() # proposed by CPMP
# Get scores
return batchThe open-source library AirLLM, simplifies implementation to just a few lines of code. Below, you’ll find usage instructions and also the location to find AirLLM on our GitHub repository.Run the model:
def get_tokens(row, tokenizer):
system_prefix = "Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.\n\n### Instruction:\n{instruction}\n\n### Input:\nContext:\n{context}"
instruction = "Your task is to analyze the question and answer below. If the answer is correct, respond yes, if it is not correct respond no. As a potential aid to your answer, background context from Wikipedia articles is at your disposal, even if they might not always be relevant."
# max length : MAX_LENGTH
prompt_suffix = [f"{row[letter]}\n\n### Response:\n" for letter in "ABCDE"]
suffix = tokenizer(prompt_suffix, return_tensors="pt", return_attention_mask=False, truncation=True, max_length=MAX_LENGTH, padding=True)["input_ids"][:, 1:]
# max length : max(0, MAX_LENGTH - len(suffix))
prompt_question = f"\nQuestion: {row['prompt']}\nProposed answer: "
question = tokenizer(prompt_question, return_tensors="pt", return_attention_mask=False, truncation=True, max_length=max(0, MAX_LENGTH - suffix.shape[1]))["input_ids"][:, 1:]
# max length : min(MAX_CONTEXT, max(0, MAX_LENGTH - len(suffix) - len(question)))
prompt_context = system_prefix.format(instruction=instruction, context=row["context"])
max_length = min(MAX_CONTEXT, max(0, MAX_LENGTH - question.shape[1] - suffix.shape[1]))
context = tokenizer(prompt_context, return_tensors="pt", return_attention_mask=False, truncation=True, max_length=max_length)["input_ids"]
prefix = torch.cat([context, question], dim=1)
return prefix, suffix
def run_model(device, df, weights_loader):
model = ShardedLlama(checkpoint_path, weights_loader, device=device)
f = partial(get_tokens, tokenizer=model.tokenizer)
inputs = df.apply(f, axis=1).values
batches = np.array_split(inputs, N_BATCHES)
outputs = []
for i, batch in enumerate(batches):
outputs += model(batch)
return outputssource: Platypus2–70B with Wikipedia RAG | Kaggle
github repo: Anima/air_llm at main · lyogavin/Anima (github.com)




