LANGCHAIN — Can Benchmarking Agents Help with Tool Use?
The most dangerous phrase in the language is, ‘We’ve always done it this way.’ — Grace Hopper
Can Benchmarking Agents Help with Tool Use?
Do you want to build and evaluate agents for tool use but find it challenging? Function calling is essential for effective tool use, yet measuring function calling performance lacks good benchmarks. In this tutorial, we’ll explore new test environments for benchmarking agents’ ability to effectively use tools to accomplish tasks. We aim to make it easier for everyone to test different language model models (LLMs) and prompting strategies to determine the best agentic behavior.
Experiment Overview
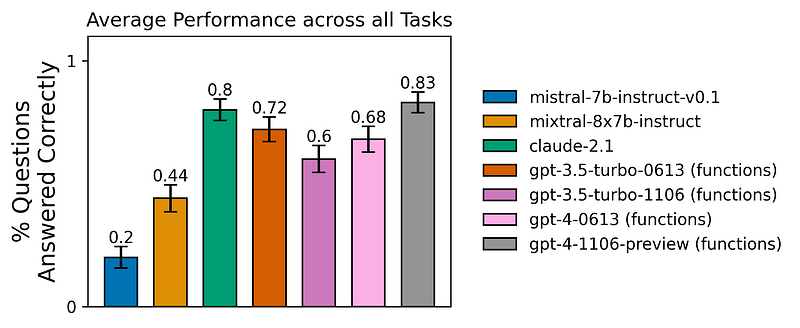
We will be sharing results and code to reproduce experiments for 7 models across 4 tool usage tasks. The tasks include Typewriter (Single tool), Typewriter (26 tools), Relational Data, and Multiverse Math. For each task, we calculate four metrics: Correctness, Correct final state, Intermediate step correctness, and Ratio of steps taken to the expected steps.
Typewriter (Single tool)
In the single-tool setting, the model is given a single type_letter tool that accepts a character as input. The goal is to call the tool for each letter in the right sequence to type a given word. A surprisingly poor performance of the fine-tuned mistral-7b-instruct-v0.1 model on this task leaves room for improvement. You can run this task yourself using the provided dataset and task documentation.
Typewriter (26 tools)
The 26-tool typewriter task tests the ability of the agent to type a provided word using the provided tools. It triggers pathological behavior across many models, resulting in a large drop in performance for agents based on OpenAI models. Explore the dataset and the task documentation to run this task on your own agent.
Relational Data
In the relational data task, the agent must answer questions based on data contained across 3 relational tables. This task most closely resembles tool usage in real-life web applications. While GPT-4 performs well on this task, there is still room for improvement. You can explore the dataset and view the results for this task.
Multiverse Math
In the multiverse math task, agents must answer simple math questions in an alternate mathematical universe. The dataset tests the ability of the LLM to “reason” compositionally and follow instructions that may contradict the pre-trained knowledge. While GPT-4 does not reliably out-perform gpt-3.5 or claude-2.1 on this task, the open-source mistral-7b model performs surprisingly well.
Additional Observations
Despite the relatively small dataset size for these experiments, random-yet-frequent 5xx internal server errors were encountered. The need for better open-source alternatives for tool use is evident. The open-source community is rapidly developing better function calling models, and more competitive options are expected to be available soon.
Conclusion
These experiments reveal the need for better benchmarks for measuring function calling performance and the importance of service reliability and stability. You can reproduce these results yourself by running the notebooks in the langchain-benchmarks package. We hope that these results will lead to changes and improvements in the development of function calling models.
Thank you for reading, and feel free to share feedback on what models and architectures you’d like to see tested on these environments. For more findings, you can check out our previous results in our linked posts.