
DEUTSCH — CHATGPT UND KI-KURZARTIKEL
Kreativität entfesselt: Die ethische Reise von ChatGPT im Zeitalter des Urheberrechts
ERKUNDUNG DER KÜNSTLICHEN INTELLIGENZ IN KLEINEN DOSIERUNGEN VON WISSEN

Teil I — Ethische und rechtliche Herausforderungen der generativen KI im Urheberrecht
1 — Einleitung
In der Content-Produktion, sei es Text, Audio, Bilder, Video, virtuelle Umgebungen, Malerei oder Computercode, werden Urheberrechte traditionell Menschen zugeschrieben.
Jedoch, wenn ChatGPT ins Spiel kommt, um Inhalte zu generieren, entstehen Komplexitäten, und die Autorschaft verflüchtigt sich im Nebel der künstlichen Intelligenz.
Die Schöpfungen der KI lassen uns oft ratlos zurück, ob sie von Maschinen oder Menschen produziert wurden.
Die Unsicherheit schwebt darüber, wem die Urheberrechte gehören: dem Unternehmen, das das Produkt konzipiert hat, dem Benutzer, der die Frage im Chatbot-Prompt formuliert hat, oder den Eigentümern der Daten, die den Algorithmus trainiert haben.
In diesem Tanz zwischen dem von Maschinen Geschaffenen und dem von Menschen Geschaffenen werden wir die ethischen und rechtlichen Herausforderungen erkunden, die die generative KI für das traditionelle Verständnis von Autorschaft mit sich bringt.
Willkommen auf der ethischen Reise von ChatGPT im Zeitalter des Urheberrechts, wo Menschen und Maschinen darum konkurrieren, wer der Autor des kreativen Prozesses in Zukunft sein wird.
2 — Herausforderungen des Urheberrechts im Zeitalter der KI
Im Bereich des Urheberrechts gibt es Debatten darüber, ob künstliche Intelligenz (KI) als Autor betrachtet werden kann oder nicht.
Die Festlegung von Schutzkriterien, um zu bestimmen, ob ein von KI generiertes Werk durch Urheberrechte geschützt werden kann, ist eine komplexe Herausforderung.
Für einige ist KI keine menschliche Entität und kann nicht als Autor betrachtet werden. Für andere wird diese Überlegung gültig, wenn die produzierte Arbeit originell und kreativ ist.
Für gemeinsam entwickelte Werke von Autor und KI stellt sich die Frage, ob die KI als Mitautorin betrachtet werden könnte.
Ein weiterer Punkt ist die Bewertung der Originalität eines von KI geschaffenen Werks, unter Berücksichtigung, dass seine Reproduktion auf den Trainingsdaten basiert, die möglicherweise ohne Zustimmung der Autoren verwendet wurden.
Wie sollen die Gesetze des fairen Gebrauchs auf von KI geschaffene Werke angewendet werden, angesichts der Ambiguität dieser Fragen, die die ethischen und rechtlichen Herausforderungen widerspiegeln, die die künstliche Intelligenz im Urheberrechtsbereich aufwirft?
Dies ist die faszinierende neue Welt des Urheberrechts im Zusammenhang mit von KI generierten Werken.
3 — Aktuelle Herausforderungen der Regulierung im Urheberrecht der KI
Einige Länder beginnen, die Regulierung des Urheberrechts für KI in Betracht zu ziehen.
In den Vereinigten Staaten hat das Gericht entschieden, dass Werke, die mit Hilfe von KI erstellt wurden, nicht durch das Gesetz geschützt werden, sondern nur für Kunst, die von Menschen produziert wurde.
Im Jahr 2023 hat der Kongress der Vereinigten Staaten eine Untersuchung zu den Urheberrechten im Zusammenhang mit KI eingeleitet und die Auswirkungen dieses Fortschritts auf die Kreativindustrie untersucht.
Im Jahr 2022 schlug die Europäische Union eine spezifische Regulierung für die Urheberrechte der KI vor und erkannte sie unter bestimmten Bedingungen als Autor an.
In Asien und China scheint die Situation weniger reguliert zu sein, während in Brasilien KI keine rechtliche Persönlichkeit hat und nicht als eine Einheit mit Rechten betrachtet wird.
Alle sind besorgt, da die Generative KI die Weltpolitik und -wirtschaft aus dem Gleichgewicht bringen kann.
Die KI ist zu einem obligatorischen Thema bei Treffen weltweiter Führer geworden, und eine Reihe kleiner Verträge wurden unterzeichnet, während die Regulierung gesucht wird.
4 — Rechtsstreitigkeiten im Zeitalter der KI
Diejenigen, die sich ungerecht behandelt fühlen, haben sich an die Gerichte gewandt.
Der jüngste Fall betrifft die Klage der New York Times (NYT) gegen OpenAI und Microsoft, Partner bei der Entwicklung des ChatGPT.
Die Anklage lautet, dass die Unternehmen ihren Inhalt ohne Erlaubnis oder Zahlung verwendet haben, um KI-Modelle zu trainieren.
Diese KI-Modelle bedrohen Qualitätsjournalismus, indem sie es den Medien erschweren, ihre Inhalte zu schützen und zu monetarisieren.
Die Entschädigung beläuft sich auf Milliarden von Dollar, um erlittene Schäden und die Kopie von Werken abzudecken.
Im Jahr 2023 reichte eine Gruppe von Künstlern eine Klage gegen Google ein, mit der Behauptung, dass das Unternehmen das Urheberrecht verletze, indem es ihre Werke zur Schulung seiner KI-Modelle verwende.
Im Jahr 2024 reichte eine Gruppe von Autoren eine Klage gegen OpenAI ein, mit der Behauptung, dass das Unternehmen das Urheberrecht verletze, indem es ihre Werke zur Schulung seines KI-Modells verwende.
Diese Klagen, zusammen mit vielen anderen im Laufe der Zeit, sollen etwas Licht auf die zukünftige KI-Gesetzgebung werfen.
Trotz der Dringlichkeit gibt es einen Dialog zwischen Regierungen und Privatwirtschaft, um echte Parameter für eine Regulierung zu finden.
Parte II — Wirtschaftliche und soziale Auswirkungen der KI-Technologie

1 — Welle synthetischer Inhalte: Die herausfordernde Verbreitung von Kreationen der KI
Synthetische Inhalte sind von Maschinen generierte Inhalte, die Texte, Bilder, Videos, Audios und Computercode umfassen und die menschliche Produktion imitieren.
Wir erleben eine regelrechte Explosion in der Produktion dieser Art von Inhalten, wobei die ersten Unternehmen und Produkte wie ChatGPT, Jasper, Stable Diffusion, Stability.AI, Character.AI, Replika, Midjourney, Lexica Art, You.Com den Weg ebnen.
Darüber hinaus markieren Giganten wie Google, Adobe, Meta und Microsoft ihre aggressive Präsenz in diesem Bereich mit auf KI ausgerichteten Produkten und Dienstleistungen.
Die massenhafte Generierung synthetischer Inhalte hat das Internet überschwemmt und stellt eine Herausforderung dar, um festzustellen, ob diese Kreationen urheberrechtlich geschützt sind, ob sie von Menschen oder Maschinen entwickelt wurden und woher die Unternehmen die Daten für das Training ihrer Algorithmen erhalten haben.
Achten Sie von nun an genau darauf, denn vieles von dem, was Sie im Internet nutzen, wurde nicht von Menschen, sondern von Maschinen erstellt. Dies sind synthetische Inhalte.
Es ist möglich, dass in naher Zukunft maschinengenerierte Inhalte die von Menschen generierten übertreffen werden.
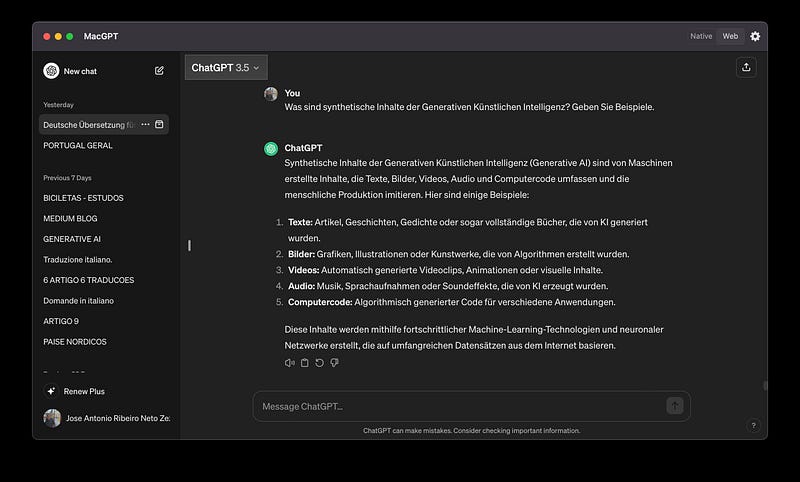
2 — Auswirkungen der Generierung synthetischer Inhalte: Eine Bedrohung für die Kreativwirtschaft?
Die Kreativwirtschaft lebt von der Produktion von Werken, Urheberrechten und dem Verkauf von Dienstleistungen.
Der Aufstieg der maschinengenerierten synthetischen Inhalte wirft die Frage auf: Trägt diese technologische Innovation zur Arbeitslosigkeit in diesen Branchen bei? Wenn wir die KI darum bitten, synthetische Inhalte wie Gemälde, Bilder oder Texte zu erstellen, besteht die Möglichkeit, die Nachfrage nach kreativen Fachleuten wie Malern, Schriftstellern, Autoren und Content- und Code-Produzenten zu reduzieren?
Diese Veränderungen werfen die entscheidende Frage auf: Ist die Kreativwirtschaft gefährdet? Die Einführung dieser Technologie hätte das Potenzial, Märkte, Arbeitsplätze und die Wirtschaft als Ganzes signifikant zu verändern und eine neue Ära einzuleiten, in der menschliche Kreativität mit maschinellem Support verschmilzt.
Experten argumentieren, dass diese Form von Intelligenz praktisch alle Branchen neu erfinden kann, einschließlich Suchmaschinen, und prognostizieren, dass Unternehmen dies mit oder ohne Regulierung übernehmen werden.
Die Kreativwirtschaft wird von diesen Technologien direkt betroffen sein, und wenn Sie in diesem Bereich tätig sind, ist es ratsam, gut informiert zu sein, um nicht unvorbereitet erwischt zu werden.
3 — Erforschung der Generativen Künstlichen Intelligenz (Generative AI)
Die Generative Künstliche Intelligenz (Generative AI) ist der Bereich der Künstlichen Intelligenz, der sich der Erstellung synthetischer Inhalte widmet.
In diesem Bereich werden Modelle entwickelt, die auf fortschrittlichen Machine-Learning- und neuronalen Netzwerktechnologien basieren und umfangreiche Datensätze aus dem Internet verwenden, um die Modelle oder Algorithmen zu trainieren.
Eines der häufigsten Modelle ist das LLM (Large Language Models), das für die Verarbeitung natürlicher Sprache (NLP) in Aufgaben wie Sprachübersetzung, Textgenerierung, Fragestellungen und Antworten verwendet wird.
Bemerkenswerte Namen in der Kategorie LLM sind GPT, Gemini, BERT, Llama, Claude und andere, die eine wesentliche Rolle in verschiedenen Chatbots spielen.
Die Generative KI stellt eine signifikante Weiterentwicklung der Fähigkeit von Maschinen dar, nicht nur Informationen zu verarbeiten, sondern auch originale Inhalte zu erstellen. Sie definiert die Grenzen dessen neu, was im Bereich der künstlichen Intelligenz möglich ist.
4 — Ursprünge der Daten für das Training Generativer Algorithmen
Die Datensätze, auch als Datasets bekannt, die für das Training von auf generativen Modellen basierenden Systemen wesentlich sind, werden aus dem Internet extrahiert und bestehen aus offenen und öffentlichen Daten.
Dieser Prozess, als “Web Scraping” bezeichnet, umfasst die sorgfältige Sammlung von Informationen mithilfe von Scraping-Software und Bots. Die gesammelten Daten umfassen eine Vielzahl von Typen, können strukturiert oder unstrukturiert sein.
Sie umfassen Text, Bilder, Videos, Computercode, HTML und Metadaten. Die Reichhaltigkeit und Vielfalt dieser Daten tragen zur Robustheit und Anpassungsfähigkeit der Algorithmen der Generativen Künstlichen Intelligenz während des Trainings bei, was es ihnen ermöglicht, synthetische Inhalte mit größerer Komplexität und Originalität zu generieren.
In diesem Prozess werden die ursprünglichen Datenquellen, die im System zu Tokens wurden, verworfen, verschwinden und machen Platz für ein konsolidiertes Modell, was es schwierig macht, Urheberrechte zu identifizieren, da die Reproduktion der Daten sicherlich nicht auf einer Kopie basiert, sondern auf Statistiken über wiederholte Tokens und Wörter.
5 — Training der Modelle und die Generierung von falschen Informationen
Im Prozess des Trainings von KI-Modellen für die Generierung von Text werden sie mit umfangreichen Mengen von Text aus dem Internet und anderen digitalen Quellen konfrontiert.
Während dieses Prozesses besteht die Gefahr, korrekte Inhalte mit falschen Informationen zu vermischen, da die Modelle wiederholen, was sie aus den Trainingsdaten gelernt haben.
Wenn die Trainingsdaten nicht verlässlich sind, werden auch die Ergebnisse der Generierung von synthetischem Inhalt nicht verlässlich sein.
Schlimmer noch, das endgültige Ergebnis eines Systems, das viele Schichten von neuronalen Netzwerken verwendet, ist eine Blackbox, das heißt, niemand weiß wirklich, was daraus kommen kann, eine Frage, die alle, einschließlich Wissenschaftler und Experten, beunruhigt.
Daher haben wir trotz der Entwicklung dieser Technologie immer noch keine vollständige Vorstellung von dem Potenzial dieser Systeme, falsche Informationen zu generieren.
Viele Fehler in synthetischen Texten können unbemerkt bleiben und erst von Experten erkannt werden, die Nuancen wahrnehmen können, wenn sie mit Plattformen wie dem ChatGPT interagieren.
Diese Fähigkeit des menschlichen Unterscheidungsvermögens ist entscheidend, um mögliche Verzerrungen oder Ungenauigkeiten zu identifizieren und während des Trainings dieser KI-Modelle zu korrigieren.
Es gibt Bemühungen von KI-Unternehmen, ihre Systeme zu trainieren und neu zu trainieren, um zu verhindern, dass solche Situationen auftreten.
Es ist jedoch nicht einfach, und der jüngste Fall von Taylor Swift, bei dem pornografische Bilder der Sängerin verbreitet wurden, zeigt, dass es nicht viel Kontrolle über die Trainingsdaten dieser Systeme gibt.
6 — Risiken der Generativen KI, die in die Urheberrechte eingreifen
Die mit der Generativen KI verbundenen Risiken sind vielfältig und umfassen:
- Generierung von Inhalten mit Plagiaten.
- Auswirkungen auf Urheberrechte und ethische Fragen.
- Möglichkeit der Generierung von giftigem Inhalt.
- Generierung von unzuverlässigen und falschen Inhalten.
- Generierung plausibler Antworten, jedoch mit falschen Punkten.
- Veraltet machen des Turin-Tests.
- Generierung tendenziöser Inhalte.
Das Management dieser Risiken ist entscheidend für die ethische und verantwortungsbewusste Entwicklung der Generativen KI.

7- Die beiden Seiten derselben Medaille
Die Dualität der Perspektiven in Bezug auf die Generative KI stellt sich als eine komplexe Debatte dar.
Einige argumentieren, dass diese Systeme konflikthafte ethische Fragen mit sich bringen, Urheberrechtsverletzungen begehen und bedeutende rechtliche Herausforderungen bewältigen müssen. Die Sorge dreht sich um die Urheberschaft von von KI generierten Inhalten und wirft Fragen darüber auf, wer die Urheberrechte besitzt und wie diese Rechte geschützt werden können.
Auf der anderen Seite gibt es diejenigen, die behaupten, dass die Generative KI über rechtliche Schritte erhaben ist. Unternehmen in diesem Bereich argumentieren, dass die Verwendung von Daten in den USA durch die Lehre der fairen Verwendung (fair use) abgedeckt ist, die die Meinungsfreiheit fördert, indem sie die Verwendung urheberrechtlich geschützter Werke für Zwecke wie Kritik, Kommentare, Nachrichten und Lehre unterstützt.
Im rechtlichen Bereich entsteht die Notwendigkeit, entscheidende Fragen zu Urheberrechten im Zusammenhang mit den Ein- und Ausgangs-Trainingsdaten der KI zu klären.
Für die Ausgabedaten, wer ist der Eigentümer: der Benutzer, das Unternehmen, das das Modell erstellt hat, oder der Inhaber der Originaldaten?
In Bezug auf die Eingabedaten, wer hat die Rechte an diesen Daten, und wie spiegelt sich dies rechtlich im generierten Inhalt wider?
Die Festlegung rechtlicher Beschränkungen bei der Datensammlung wird zu einer zentralen Frage, um einen ethischen und gerechten Ansatz bei der Nutzung der Generativen KI zu gewährleisten.
8 — Wirtschaftliche und soziale Auswirkungen der Technologie.
Die wirtschaftlichen und sozialen Auswirkungen der Technologie, insbesondere der Generativen Künstlichen Intelligenz (Generative AI), stehen im Mittelpunkt intensiver Debatten und Reflexionen.
Einige prognostizieren eine Situation mit Massenarbeitslosigkeit aufgrund der Automatisierung und dem Ersatz menschlicher Arbeitskräfte durch KI-Systeme. Für andere betreten wir eine neue Ära der Zusammenarbeit zwischen Menschen und Maschinen, in der die Generative KI den kreativen Prozess vorantreiben kann, indem sie die Phase der Ideen- und Inhaltegenerierung beschleunigt.
Die Governance dieser Technologie liegt größtenteils in den Händen der Unternehmen, die Generative Modelle produzieren. Einige verfolgen einen vorsichtigen Ansatz, besorgt über mögliche negative und ethische Auswirkungen, während andere die breite Freigabe dieser Modelle unterstützen, um den Zugang zur Technologie zu demokratisieren und Innovationen in der Gesellschaft und Wirtschaft voranzutreiben.
Unternehmen, die KI-Produkte entwickeln, behaupten, dass ihre Praktiken innerhalb der gesetzlichen Grenzen liegen, während die Inhaber von Urheberrechten beginnen, ihre Position zu beziehen und die erforderlichen rechtlichen Schritte ergreifen, um ihre Interessen in dieser neuen technologischen Landschaft zu schützen.
Aus diesen und anderen Gründen betreten wir eine neue Ära, die sogenannte Ära oder Wirtschaft der Künstlichen Intelligenz (KI), in der menschliche Aktivitäten jeglicher Art von KI-Technologien beeinflusst und unterstützt werden.
Wir hoffen, dass das Urheberrecht seinen Platz in diesem Ökosystem finden kann.
Autor: José Antonio Ribeiro Neto (Zezinho).