
Keras 3.0 Is Out. Here Is What You Must Know
This is a preview version and is planned for a full release in the Fall of 2023!
Salient points!
- Keras 3.0 is a full rewrite of the codebase
- The backend is now modular
- It can run on any arbitrary framework like TensorFlow, JAX, and Pytorch.
The new Keras will be known as keras_core. This means that using import keras_core as keras in place of from tensorflow import keras is all you need. It should be able to run the same code without any issues.
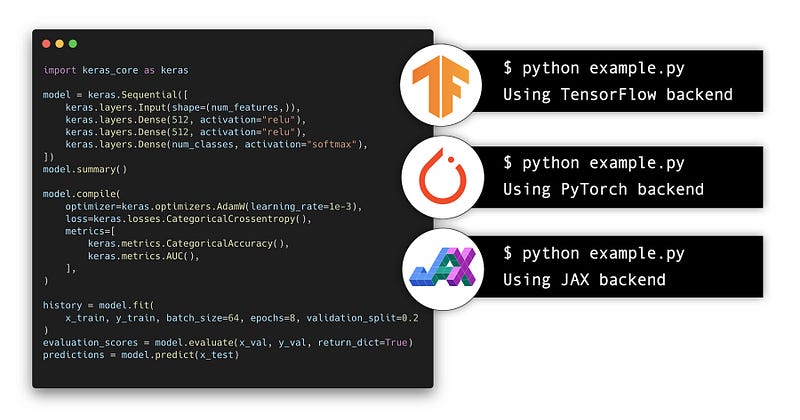
History of Keras
Before 2018, Keras was multi-backend and it could run on Theno, TensorFlow, CNTK, and MXNet. But Keras made a decision that the focus needed to push only the TensorFlow backend only as TF was the backend used the most commonly and was becoming universal.
According to the 2023 Stackoverflow Developer Survey and the 2022 Kaggle Machine Learning & Data Science Survey TensorFlow has been 55% and 60% of the market share and PyTorch has been 40–45%. JAX has been a smaller part of the market share but it has been the go-to backend of the Google DeepMind, Midjourney, Cohere, and some other GenAI projects.
Main Features of Keras Core
Cross-framework low-level language implementation for Deep Learning
Deep learning layers and pre-trained models created using keras_core will work exactly the same way in any framework. Especially keras_core.ops namespace is a cross-functional space that contains —
- A full implementation of NumPy API: these implementations include critical functions like
ops.matmul, ops.sum, ops.stack, ops.einsum etc. - A neural-network-specific functions like
ops.softmax, ops.binary_crossentropy, ops.conv etc.
You can develop custom components using Keras_core and then deploy them using whichever backend works for you, or you can use your framework of choice (locked in).
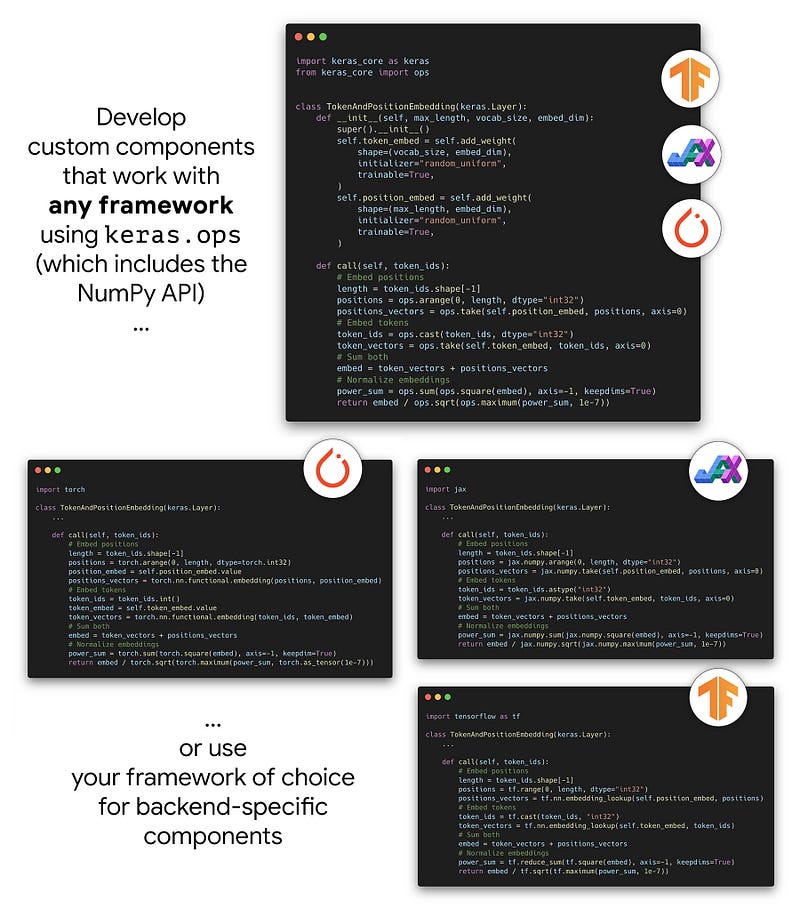
Additionally, Low-level implementations of -
- JAX training loop to train a Keras model using an
optaxoptimizer,jax.grad,jax.jit,jax.pmap. - TensorFlow training loop to train a Keras model using
tf.GradientTapeandtf.distribute. - Low-level PyTorch training loop to train a Keras model using a
torch.optimoptimizer, atorchloss function, and thetorch.nn.parallel.DistributedDataParallelwrapper. - Use a Keras layer or model as part of a
torch.nn.Module.
This means that PyTorch users can start leveraging Keras models whether or not they use Keras APIs! You can treat a Keras model just like any other PyTorch Module.

The same Cross-framework approach will work for pipelines with all backends
tf.data.Datasetpipelines: the reference for scalable production ML.torch.utils.data.DataLoaderobjects.- NumPy arrays and Pandas data frames.
keras_core.utils.PyDatasetobjects.
Keras_core.Applications namespace
keras_core.applications is the namespace where 40 Keras application models are available in all the backends. The vast array of pre-trained models in KerasCV and KerasNLP (e.g. BERT, T5, YOLOv8, Whisper, etc.) also work with all backends.
Edit what you want incrementally
A progressive disclosure of complexity is design principle at the core of keras. You can start with simpler workflows like sequential models and then when you need more flexibility, override a function with a different component. That means you will use most of the same pipeline but override a single function.
here is an example
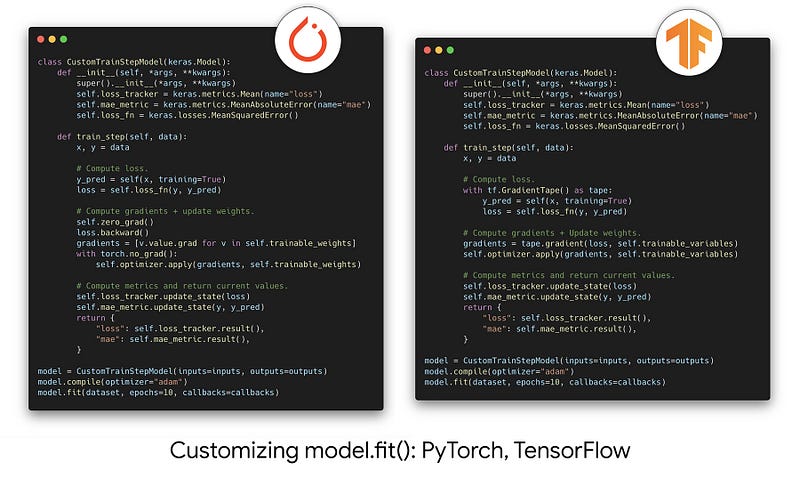
Stateless API to work with JAX
Older Keras was all stateful. This means at each update during training and evaluation of the model, the value of the variables actually changed and there was no access to it. The access to the API makes it possible to use with JAX functions which require these variables to be fully stateless.
The stateless API is available for all layers, models, metrics, and optimizers
- All layers and models have a
stateless_call()method which mirrors__call__(). - All optimizers have a
stateless_apply()method which mirrorsapply(). - All metrics have a
stateless_update_state()method which mirrorsupdate_state()and astateless_result()method which mirrorsresult().
This does not change the way we all have been using Keras. The code does not change but objects generated from it can be used with JAX without affecting TensorFlow and PyTorch.
Still a pre-release: What's not working
The import order is messed up: LOL in its true fashion with imports of the packages you have to import torch AFTER tensorflow. If you import tensorflow before torch, it will crash
Integer dtypes with PyTorch: torch does not support or unit16 or unit32. The backend will fall back to int32 and int64 to maintain compatibility of torch with JAX and TensorFlow
Average Pooling issue: Torch does not have a padding option so the dimensions of the layers may have different dimensions than TF
Using .map() with tf.data pipeline: The .map() inkeras layers and in tf.data pipelines work with only tensorflow backend but not any other backend.
Image layers with channels first or last: Only torch uses the channel_first and other frameworks use channel_last. To keep compatibility keras_core will have to keep swapping the channel_first to last or vice versa. This loses compute efficiency.
Sparse NN support: There is no support for sparse types. It is planned for the future.
If you have read it until this point — Thank you! You are a hero (and a Nerd ❤)! I try to keep my readers up to date with “interesting happenings in the AI world,” so please 🔔 clap | follow | Subscribe 🔔
Become a member using the referral: https://ithinkbot.com/membership
Find me on Linkedin https://www.linkedin.com/in/mandarkarhade/






