
K8s Vertical Pod Autoscaling
We configure Kubernetes VPA and monitor the effects with Prometheus on an example app

Parts
- Manually monitor pod resources
- Automatically set pod resources with Vertical Pod Autoscaling (this article)
Related
- Practical Guide to Kubernetes Horizontal Pod Autoscaling
- Practical Guide to Kubernetes Node Autoscaling
TL;DR
VPA (Vertical Pod Autoscaling) will suggest or even automatically set values for resource requests and limits for pods inside the cluster.
Resource requests and limits
What?
What are resource requests and limits? This great blog post and video will get you up to date.
Why?
Kubernetes clusters work best when all containers of all pods have resource requests+limits for CPU+memory assigned. This effects pod scheduling, lifetime, termination and priority.
Though often it’s hard to know the resources for your application. If you set these too low, your application might get throttled or even gets terminated. If you set these too high, you might waste costly resources. It’s possible to monitor the resource usage of pods as we did in part 1.
But what if your cluster could set the requests and limits automatically for you?
Horizontal vs Vertical scaling
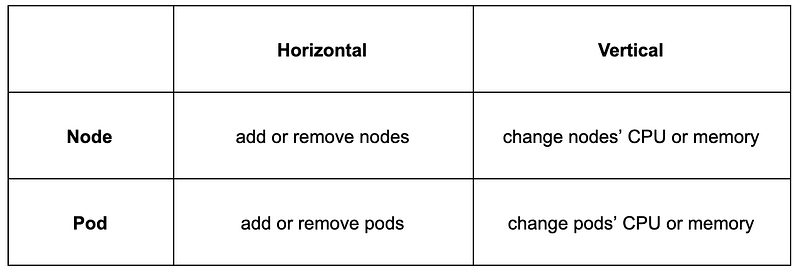
Horizontal scaling means raising the amount of your instance. For example adding new nodes to a cluster/pool. Or adding new pods by raising the replica count (Horizontal Pod Autoscaler).
Vertical scaling means raising the resources (like CPU or memory) of each node in the cluster (or in a pool). This is rarely possible without creating a completely new node pool. When it comes to pods though, vertical scaling would mean to dynamically adjust the resource requests and limits based on the current application needs (Vertical Pod Autoscaler).
VPA components
VerticalPodAutoscaler (VPA) is a Kubernetes resource which can be created. It references a specific deployment and some more options in the spec: section. The status: section will contain information and recommendations about the scaling process going on.
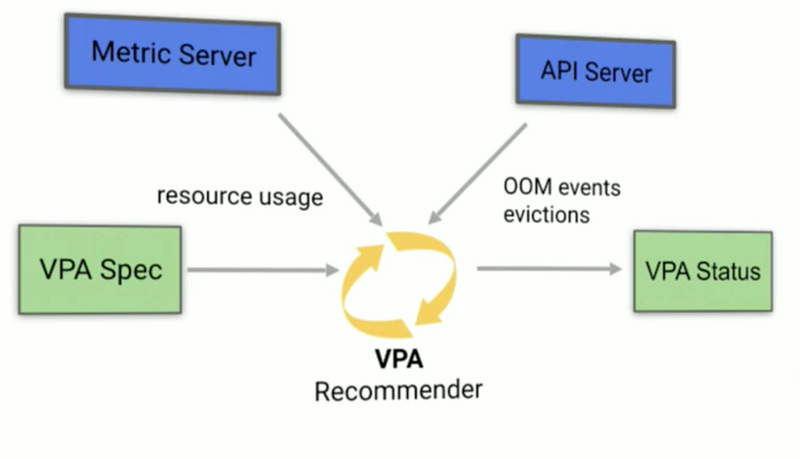
VPA Recommender
The Recommender looks at the metric history, OOM events and the VPA spec of a deployment and suggests fitting values for requests. The limits raised/lowered based on the limits:requests (more further down) proportion defined. Hence the Recommender could just be used by itself if one is unsure what the application actually needs. Further down we see resource suggestions for our example app.
VPA Auto Adjuster
Whatever the Recommender will recommend, the Adjuster will implement if the updateMode: Auto is defined.
Due to Kubernetes limitations, the only way to modify the resource requests of a running Pod is to recreate the Pod. If you create a VerticalPodAutoscaler with an
updateModeof "Auto", the VerticalPodAutoscaler evicts a Pod if it needs to change the Pod's resource requests. (source)
As far as I can see, in-place updating pod resources is planned. Till then pods need to be deleted and recreated to achieve auto-adjusting.
Example App
We use the example repo https://github.com/wuestkamp/k8s-example-vpa which comes with Prometheus, Grafana and an example deployment to stress resources.
App Image
The app uses image gcr.io/kubernetes-e2e-test-images/resource-consumer:1.5. It provides an HTTP endpoint and can receive commands to use resources:
curl --data "millicores=400&durationSec=600" 10.12.0.11:8080/ConsumeCPUcurl --data "megabytes=300&durationSec=600" 10.12.0.11:8080/ConsumeMemUse VPA to FIND fitting resource requests
Set VPA recommendation mode YAML
We want to use VPA only in “suggestion” mode. This is great to see if we even would like to use it:
apiVersion: autoscaling.k8s.io/v1beta2
kind: VerticalPodAutoscaler
metadata:
name: vpa
spec:
targetRef:
apiVersion: "extensions/v1beta1"
kind: Deployment
name: compute
updatePolicy:
updateMode: "Off" # only recommodation modeResource usage in the test app
We created some resource usage and monitored it using Prometheus and Grafana:
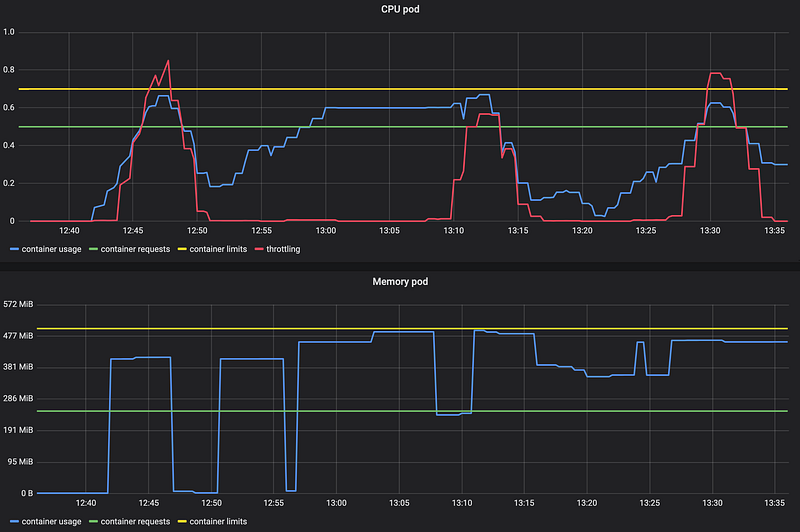
We can see that the CPU got throttled (red) some times. Not easy to see is that the memory usage resulted in OOM kills at 13:07 and 13:16.
VPA view recommendations
To see the VPA request recommendations we wait a couple of minutes and then run:
kubectl describe vpa vpa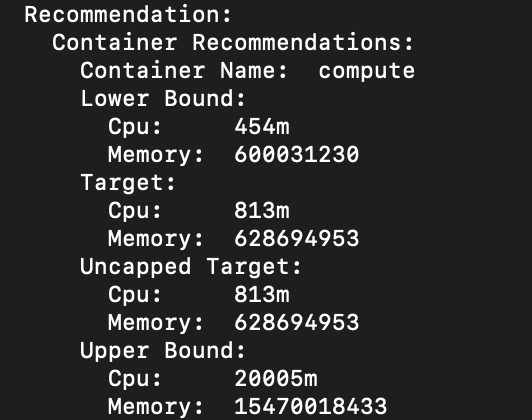
Lower Bound: everything below won’t be sufficient.
Upper Bound: everything close to or above is wasteful.
Target: that's the best value for our requests
We see that for our example app, looking at the current state of metrics the VPA suggests setting CPU requests to 813m and memory requests to 628Mi.
What about limits?
We only get a value to set requests, but what about limits? The limits will be set based on the initial limits:requests ratio that we defined in our Pod spec.
In our example app we defined:
resources:
limits:
cpu: "700m"
memory: "500Mi"
requests:
cpu: "500m"
memory: "250Mi"This means we have a CPU limits:requests ratio of 1.4 which the VPA uses:
# VPA raises limits based on ratio
limits=700
requests=500
ratio = limits / requests = 1.4=> requests * ratio = limits
=> 500 * 1.4 = 700So if the VPA raised our CPU requests to 800m it would raise the limits to (800*1.4) = 1120m.
Use VPA to SET fitting resource requests
We update the VPA resource:
apiVersion: autoscaling.k8s.io/v1beta2
kind: VerticalPodAutoscaler
metadata:
name: vpa
spec:
targetRef:
apiVersion: "extensions/v1beta1"
kind: Deployment
name: compute
updatePolicy:
updateMode: "Auto"This would terminate and recreate pods if their resource requests differ from the suggested target. Though I didn’t test this much. This will consider a Pod Disruption Budget set.
What if a pod has a CPU or memory leak?
You can still define max values the pod’s resources will be scaled up to. This way your vertical scaled pod cannot for example request all available CPU and is still restricted. Just as you define min/max values for HPA for the replica amount. The advantage is that the requests automatically set via VPA are more dynamic.
Can I use VPA with HPA?
No.
Vertical Pod Autoscaler should not be used with the Horizontal Pod Autoscaler (HPA) on CPU or memory at this moment. However, you can use VPA with HPA on custom and external metrics. (source)
Can I use VPA with Istio?
Yes, but you need to disable VPA for the Istio sidecar proxies. I might look into and write another article about using VPA to control the resources of the Istio components because these request a lot of resources by default, which could be optimized.
Recap
The VPA idea is great, though it still needs some experience and feedback I believe. I’ll be curious to get the VPA recommendations for a production cluster and compare it to the currently implemented values. Also, once pod resources can be updated in-place this would be a great improvement.
Do you know more about VPA and resource limits? Let me know in the comments!
More to read / Sources
https://cloud.google.com/kubernetes-engine/docs/concepts/verticalpodautoscaler
https://github.com/kubernetes/autoscaler/tree/master/vertical-pod-autoscaler
Become Kubernetes Certified
