K-Means Clustering Algorithm
Brief: K-means clustering is an unsupervised learning method. In this post, I introduce the idea of unsupervised learning and why it is useful. Then I talk about K-means clustering: mathematical formulation of the problem, python implementation from scratch and also using machine learning libraries.
Unsupervised Learning
Typically, machine learning models make prediction on data, learning previously unseen patterns to make important business decisions. When the data set consists of labels along with data points, it is known as supervised learning, with spam detection, speech recognition, handwriting recognition being some of its use cases. The learning methods where insights are drawn from data points without any ground truth or correct labels falls under the category of unsupervised learning.
Unsupervised learning is one of the basic techniques used in exploratory data analysis to make sense of the data before preparing to make complex machine learning models to make inferences. As this does not consist of human-labelled data, bias is minimized. Also, as there are no labels, there are no correct answers. From a probabilistic standpoint the contrast between supervised and unsupervised learning is the following: supervised learning infers the conditional probability distribution p(x|y), whereas unsupervised learning is concerned with the prior probability p(x).
K-Means Clustering Algorithm
Objective of clustering methods is to separate data points into separate clusters(pre-determined) maximizing inter-cluster distance and minimizing intra-cluster distance(increasing similarity).
K-Means is one of the clustering techniques in unsupervised learning algorithms. Some other commonly used techniques are fuzzy clustering(soft k-means), hierarchical clustering, mixture models. Hard clustering or hard k-means is assigning each data point to only one cluster instead (e.g. email Spam or not Spam) instead of assigning a non-zero membership value to each cluster(Spam: 13%, Not Spam: 87%) as in soft k-means. I am covering hard-clustering in this post.
How the K-means algorithm works:
- Pick k centroids randomly(without replacement) from X.
2. Compute distance(L2 or Euclidean distance) of each x from all μ’s.
3. Pick the closest cluster one as the label for this x.
4. Update centroids by finding arithmetic mean of each k clusters.
5. Repeat steps 2–4 until centroids stop changing.
Mathematically, it can be reduced to finding an optimal partition S* of the dataset X.

Code
Firstly, I will be writing the basic implementation of k-means from scratch in python.
Let’s generate some data and apply k-means to see how it works.
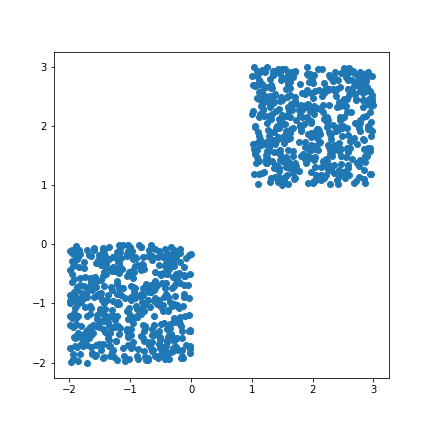
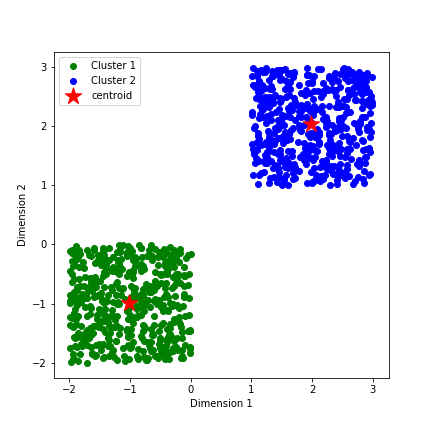
Not bad, huh? Building a model from scratch in 50 lines of code is cool :)
The same task can be done within a few lines by importing the scikit-learn library.
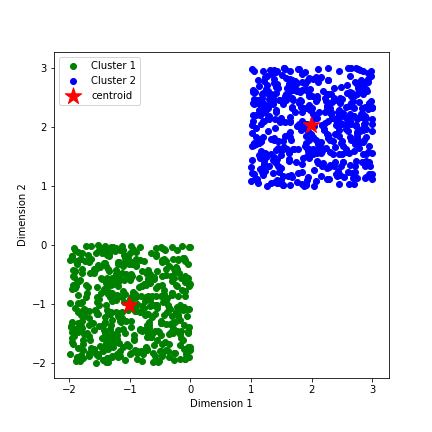
Sklearn gives pretty much the same output as the model we built from scratch on this dummy data set.
Once you have written a basic bare and bones structure from scratch and are familiar with the nitty-gritty of the implementation. After that, implementing k-means or any other algorithm is a walk in the park using specialized library functions.
Conclusion
K-means is one of the simplest unsupervised learning methods. It can be used to draw insights for EDA before moving on to build a sophisticated architecture to make decisions. This blog is a good starting point to get some idea about unsupervised learning, clustering, k-means and its implementation.
Feel free to read, code and explore to learn more. Drop a note down below to share your experience. Thanks for reading :)