
Just In Time Inference is the Antidote for Poor Generalization in Deep Learning

In a previous post, we discussed the intrinsic complexity of biological neurons (see: Neurons are more complex that we thought) and thus the need for research to explore additional complexities in the standard model of the artificial neural network. In that post, we referenced research on a more complex LSTM node that was hierarchical. Although, a naive and simpler mathematical approach to adding more complexity is to use (pardon the pun) complex values for the weights (see: Should Deep Learning use Complex Numbers?). Complex ( i.e. with imaginary numbers) weights have been shown to primarily effective in Recurrent Neural Networks.
Recently new research papers, that have been pre-published at Arxiv, shows that introducing flexibility to the underlying neural weights can lead to better generalization of a network.
In a paper “Flipout: Efficient Pseudo-Independent Weight Perturbations on Mini-Batches” the authors explore performing stochastic perturbations on the weights while in training. These perturbations of weights are designed to be (1) independent of each other and (2) symmetric around zero. The authors show that this FlipOut method outperforms DropOut. This paper provides us with an early hint of the value of using stochastic weights over the more conventional deterministic weights.
An earlier even paper “On the Robustness of Convolutional Neural Networks to Internal Architecture and Weight Perturbations” revealed that ConvNets were robust to weight perturbations at the higher layers (Not so for the lower layers). This tell here aligns with the intuition that greater inference flexibility is needed at inference of higher abstractions.
Uber, with great fanfare, has revealed a new paper where they describe “Differential Plasticity”, the crux of their approach is to augment the standard weight with an additional term that becomes adjustable after training (see term below that is in red).
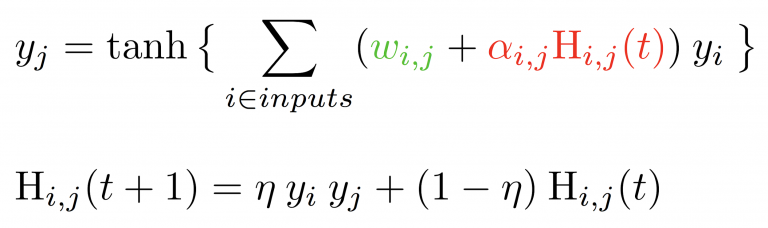
This simple addition appears to address the well-known inflexibility of neural networks to make adjustments after training. Conventionally, Deep Learning networks are hardwired after training. Adding this plasticity term that is able to continually (or gradually) make adjustments over time. One obvious deficiency of neural networks is that of premature optimization.
We know this from computer science in the more general form of eager versus lazy evaluation. In its most general sense, it involves the deferment of execution only at the time that it is needed. Said differently, execution on demand or just in time. This differential plasticity is basically on demand inference or just-in-time inference.
Another Arxiv pre-publication “Iterative Visual Reasoning Beyond Convolutions” shows how to use even more complex inference methods layered on top of standard ConvNets. In this paper, the authors show that through the use of knowledge graphs, region graphs and the assignment of regions to classes that they are able to improve conventional ConvNet classification by a whopping 8.4% improvement.
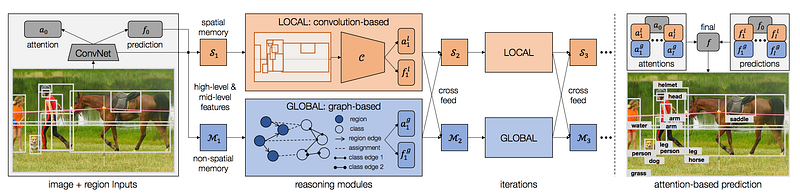
Also interesting in this architecture is the idea of a reasoning module:
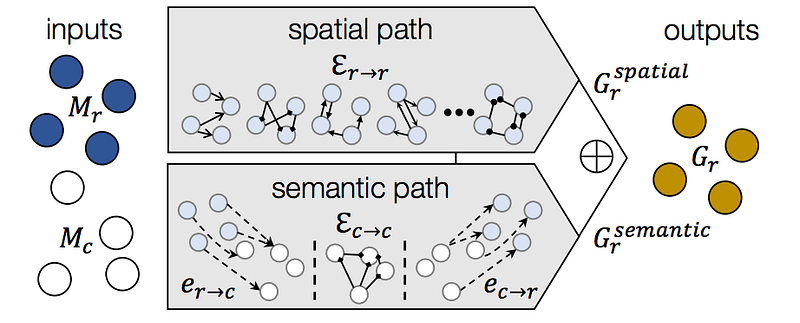
That appears to encapsulate a kind of ‘dual process’ model found in cognition.
This approach to deferred execution is clearly critical to achieving better generalization. After all, it is illogical to have a cognitive system that is absent of any adaptive mechanism. This is the problem with conventional neural networks. Their weights have always been fixed. This notion of just in time originates from the “Loosely Coupled Principle” that forms the basis of more advanced Deep Learning Architectures.
More about the Loose Coupling Principle and Deep Learning can be found here:
