
It’s a Mistake to Trust the Best Model of a GridSearchCV
Explained through four examples where the “best model” isn’t actually the best model

Scikit-learn’s GridSearchCV is an often-used tool to optimize the hyperparameters of a machine-learning model. Unfortunately, not everyone is analyzing its output thoroughly, and simply uses the GridSearchCV’sbest estimator. This means in a lot of situations you might not be using the actual best estimator. Let’s first determine how to run a grid search and detect which estimator it chooses as its best.
A very basic GridSearchCV could look like this:
import pandas as pd
from sklearn.model_selection import GridSearchCV, train_test_split
from sklearn.tree import DecisionTreeRegressor
df = pd.read_csv('data.csv')
X_train, X_test, y_train, y_test = train_test_split(df.drop('target'),
df['target'],
random_state=42)
model = DecisionTreeRegressor()
gridsearch = GridSearchCV(model,
param_grid={'max_depth': [None, 2, 50]},
scoring='mean_absolute_error')
gridsearch.fit(X_train, y_train)
gridsearch.train(X_train, y_train)
# get the results. This code outputs the tables we'll see in the article
results = pd.DataFrame(gridsearch.cv_results_)
# what many data scientists do, while they shouldn't without analyzing first
Y_pred = gridsearch.best_estimator_.predict(X_test)
In the bottom lines of the code above I warn about using the best_estimator_. Therefore it is important to understand how scikit-learn chooses the best estimator of a GridSearchCv . We only need to look at one column of the resultsdata frame generated with cv_results_to determine why a model has been selected as the best: mean_test_score :
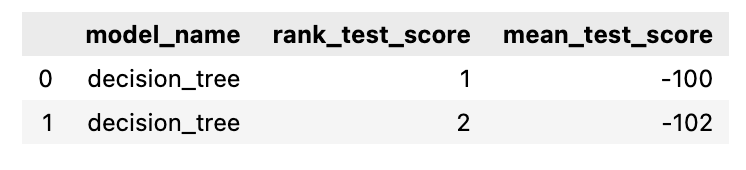
mean_test_score displays the average score of that model on the test sets; e.g. by default parameter cv=5 which means the mean_test_score is the average of the model’s test score for 5 test sets. If you would change cv to 4 you’d get the following train-test data division:
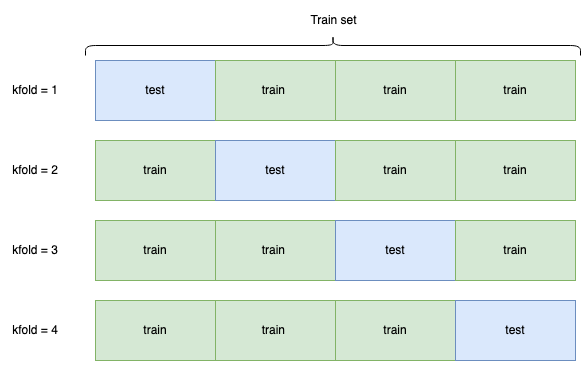
By default, GridSearchCV picks the model with the highest mean_test_score and assigns it a rank_test_score of 1. This also means that when you access a GridSearchCV’s best estimator through gs.best_estimator_you will use the model with a rank_test_scoreof 1. However, there are many cases when the model with a rank_test_score of 1 isn’t actually the best model. Let’s illustrate this through four examples where the ‘best’ model isn’t the best model, and see how we can determine what the actual best model is.
Example #1: test score’s standard deviation

If we take a look at the table above we can see that the ‘best’ model has a mean_test_score of -100 and a std_test_score of 21, which are expressed in the mean absolute error. Because this is an error score, the closer the value is to zero, the better the score. The ‘second best’ model has a mean_test_score of -102 and a std_test_score of 5. std_test_score stands for the standard deviation of the scores of the model on the test set, and this is an absolute value, hence, the closer to 0 the more consistent the model performs. Even though the #1 model has a slightly better mean, its standard deviation is much larger. This means that the performance of the model is less consistent and less reliable and most often this is not ideal. That’s why in this example I would pick model #2 over model #1, and in most use cases you should too.
Example #2: train scores
Let’s now consider two models which perform nearly identically on the test set:

Even though these models seem to be nearly equal in performance, they are not, but to be able to detect that we have to set the return_train_score parameter of GridSearchCV from its default value False to True:
from sklearn.model_selection import GridSearchCV
from sklearn.tree import DecisionTreeClassifier
model = DecisionTreeClassifier()
param_grid = {...}
gridsearch = GridSearchCV(model,
param_grid,
scoring="mean_absolute_error",
return_train_score=True)Now if we run gridsearch.cv_results_ after fitting and training, we notice there are multiple columns added, of which one is displayed below: mean_train_score :

What we can notice now is that even though both models seem to perform equally on the test set, the second model is actually significantly better on the train set compared to the first model. Of course, this could imply overfitting in some situations, but here the mean train score aligns better with the mean test score and therefore doesn’t seem to imply overfitting. Generally speaking, when two models perform similarly on the test sets, the model which performs more consistently when also taking the train scores into account should be preferred.
Example #3: Model Complexity
Let’s consider the following grid search results:

Above we have two models with nearly identical test and train scores. Yet, there is more important information to consider before confirming the first model to be the best one. In the last column, we see param_tree__max_depth , which shows the tree depth of each model’s decision tree. The ‘best’ model’s decision tree has a tree depth of 50, while the ‘second best’ decision tree has a tree depth of just 2. In this case, we could choose the second model to be the best model, because this decision tree is much better interpretable. E.g., we could plot the tree using sklearn.tree.plot_tree and see a very simple and easy-to-interpret tree. A tree with a depth of 50 is hardly readable and interpretable at all. As a rule of thumb, a less complex model should be preferred over a more complex model when two models perform equally on both the test set and the train set.
Example #4: Model Speed Performance
The last example I’d like to show is one of speed performance. Let’s assume we have the same grid search results as in example #3 but with one added column: mean_score_time.

Now, another reason appears why we could prefer the second model over the first model. The first model takes more than 6 times as long as the second model, probably due to its extra complexity. Of course, as mean_score_time expresses the mean time it took the model to predict a validation set, this difference seems neglectable. However, imagine a model that needs to predict machine failure based on hundreds of sensors per machine. For such a model that needs to make live streaming predictions on huge amounts of data, a difference between 0.02 seconds on n observations versus 0.003 seconds on n observations can make a significant difference.
To Conclude
In this article, we’ve seen four examples that show why you should never blindly trust a scikit-learn’s GridSearchCV's best estimator. Rather than just relying on the mean test score, we should also consider other columns of the cross-validation results to determine which model is the best, especially when the top models’ test scores are similar.
If you want to learn more about machine-learning and/or grid searching make sure to read these other articles about it:





