

IT Incident Ticket Classification with ML, DL and Language Models
Learning from a practical NLP project
The problem of incident ticket classification is one of huge impact to IT companies. When users raise a ticket, the ticket needs to be directed to the right team as quickly as possible, to ensure speedy resolution. Sending it to the wrong department leads to longer resolution times since it takes time for the ticket to be redirected to the right team. Currently, in most of the companies, ticket classification is done manually, which is prone to errors, and is tedious as the volume of tickets increases. Hence, we need a better solution to handle this problem.
Auto-ticket assignment: Problem
In order to reduce the possibility of misclassification of a ticket to the wrong assignment group (referred to in this post as ‘class’), we explore various classification methods and embedding methods and evaluate their performance on a sample dataset.
Dataset: Analysis and Insights
The raw dataset consists of 8500 tickets placed in various languages. These tickets belong to 69 unique classes.

We see that Caller column is irrelevant to the output class the ticket will be classified into. Hence it is discarded. Caller names are present in Description column, and need to be removed from there as well.
Short description is repeated in the Description column. Hence, we can also do away with the Short Description column.
We observe tickets written in multiple languages such as German, Spanish, Chinese, etc. There are two ways to deal with multi-language corpora: 1. Translate the tickets to a common language, and then use ML models 2. Filter out foreign language tickets and build models on the filtered corpora
We tried to use Google’s translation API, but owing to a limit on the number of requests to be handled per day, it didn’t seem like a feasible approach.
As an alternative, we discarded the Chinese tickets, and processed the German and Spanish tickets and built a Naive Bayes Classifier on it. This attempt yielded an accuracy of close to 24%. This seemed very disappointing. The data is rife with multiple issues, having a mix of English and non-English tickets being one. We decided to ignore the non-English tickets and restrict the current efforts to address only the English tickets. Hence, foreign language tickets were discarded.

As we can see, the dataset is highly imbalanced, with around 50% of the tickets belonging to just one class. Since close to 20 categories contained foreign language tickets, they were discarded (earlier attempts were made to model them but yielded close to 25% accuracy only).
Another 10 categories had less than 2 tickets, rendering them useless for building a reliable model, these categories were also discarded. We were left with a final pool of 40 unique output classes. We are also left with 4625 tickets (rows) and two columns (Description and Assignment Group).
Data Processing
Based on the insights gained from the Data Analysis, we process the data as follows:
- Remove Caller name from Description column
- Drop Caller and Short Description columns
- Remove special characters (\n, \t, etc.) from Description
- Word Embedding (converts words to numerical vectors)
A note on Unbalanced Data
We tried to address the issue of data imbalance. We up-sampled the minority classes and ran our ML model (Naive Bayes) on it, and performed a k-fold cross-validation. This yielded an accuracy of as high as 93%. This is a huge jump from 24% in the unprocessed data and 52% in processed data.
While investigating the reason behind such a huge jump, we realised that some of the minority classes has so few, yet identical tickets that up-sampling resulted in hundreds of tickets of the same identical Description. Even the test data with tickets from those classes had identical content, hence it was easier for the model to classify them. This could be a fortunate coincidence in the dataset. However, this could not be trusted. Hence, we ignored the results of the up-sampled dataset.
Choice of Language Model
We assume that the vocabulary in the corpus will be limited, repetitive and niche, since the technical terms around the domain limit the vocabulary to a great extent. In view of this assumption, we use the Term frequency- Inverse Document frequency (Tf-IDf) method for creating Word Embeddings. Details about the Tf-IDf method can be found here and here.
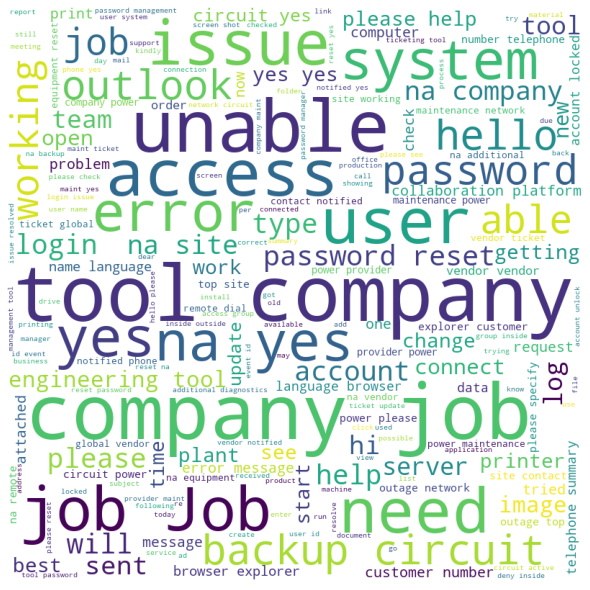
We see from the wordcloud that the most frequent terms in the tickets are “company”, “job”, “tool”, “user”, “unable”, etc. The terms appear very frequently and the vocabulary seems fairly limited, as expected. We go ahead with the Tf-IDf vectors for our machine learning models.
Choice of ML models
The most commonly used ML model for text classification is the Naive Bayes model. Though it makes the assumption that each feature is independent of the other, it is still chosen because: it is easy to interpret, it does not require any hyperparameters/hyperparameter tuning, and it trains quickly.
The performance of the model is as given below (Precision and overall Accuracy):

Using the output of the GNB model as the baseline, we aimed to improve the metrics by opting for Deep Learning models.
We first tried a plain vanilla neural network with two Dense Layers. The results of this model are as follows:

We moved towards the concept of sequence based models. Since each word in a ticket is somehow related to the neighbouring words in the sentence, we hypothesised that a recurrent neural network might be more useful. We specifically chose the LSTM as it eliminates the Vanishing Gradient or Exploding gradient scenario. The results of using this model are as follows:

Can we do better? Language Models
For these models, we skip Step 4 (Embedding step) from the data processing pipeline mentioned above. This doesn’t mean that we are not creating word embeddings. We will not be using Tf-IDf. Instead, language models use sub-word based tokenisations such as wordpiece tokenisation (used in BERT). This method of tokenisation helps relate a root verb with it various conjugations (play will be identified as similar semantically to played, playing and plays, so on).
Until BERT made its entry in 2018, UMLFit was one of the state-of-the-art language models. In an attempt to pit them against each other, we decided to build a text classifier on top of both of them and compare their performance.
ULMFit was chosen as it was one of the earliest context based models that proved that by just hyperparameter optimised LSTMs, state-of-the-art results can be achieved. It also introduced the concept of transfer-learning in NLP.
BERT being the pioneer in Attention based models, is a highly potent model for NLP tasks. But given the lack of rich contextual data or extremely lengthy sentences, it seemed like an overkill for the data we had. However, we wanted to see if the nature of the data would undermine the performance of this powerful model.
We used pre-trained models for both, and re-trained only the final layers of the models. However, we ran ULMFit for 5 epochs, while BERT was run only for one. The reason behind this was BERT training was causing repeated failures in the system due to memory failure or due to taking extremely long time to train, unlike ULMFit, which trained far quicker.
Comparison of Models: Performance
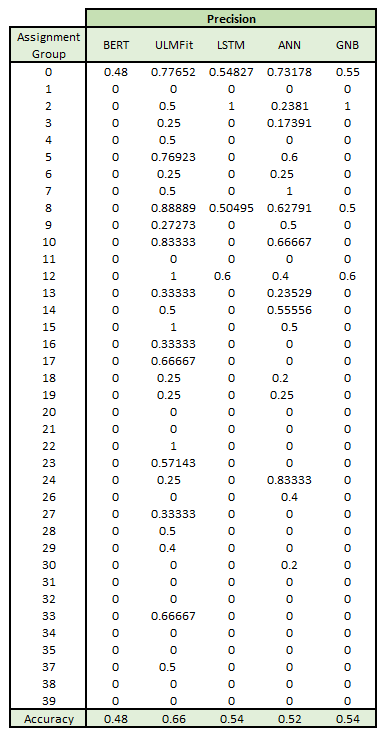
The performance of all the models is summarised on the left. We have chosen Precision as the Main metric to evaluate a model, while we have used accuracy to compare across models.
Based on the metrics, ULMFit seems to have achieved far better results than the rest. This can go on to mean that understanding context of the ticket is actually helpful in determining the output class.
Though BERT seems to have performed relatively poorly, it is in keeping with our assumptions that given a single fine-tuning run (poor attempt at fine-tuning BERT) due to computational limitations, it can probably yield better results given sufficient compute resources to train it on the custom dataset.
Limitation and Future Research
- The current models are prescribed for single language corpora (English). Currently, translation of foreign language tickets has not been done. Neural machine translation can be performed and then the models can be applied on the translated text.
- BERT model took 50 hours to train for one cycle. It also led to many memory failures. Keeping in mind the timeframe of the project, we decided to go ahead with just one fine-tuning run of BERT. In the future, this can be extended to more than 1 (say 5) run, given sufficient time and compute power, in order to get better results.
References
https://static.googleusercontent.com/media/research.google.com/en//pubs/archive/37842.pdf