
Is OpenAI’s Q* Project the Beginning of Singularity
The emergence of AI singularity or all smoke and mirrors?

The last week's OpenAI events have turned tech newsrooms upside down.
The firing of Sam Altman by OpenAI’s board, the revolt of its workforce, the announcement of support by Microsoft, and Sam’s eventual return kept tech journalists busy for the entire week, starting with the tumultuous weekend.
My LinkedIn feed was replete with posts, rumors, and speculation about GPT and its parent OpenAI.
- Journalists kept talking about whether OpenAI led by Altman camp is deviating from its founding philosophy of AI for humanity.
- Investors kept discussing where the fault lines lay: The board, Sam Altman and his camp, or OpenAI’s original mission.
- Tech recruiters kept wondering where OpenAI’s staff (most of the 770 that resigned) would go.
No one fully knew what was actually going on inside the GPU-filled desks and surrounding cabins.
While the rumor mills were churning out new updates, the story kept unfolding.
What really happened?
A Twitter (Oops, X) user provided a complete, relatable chronology of the events on Nov 18:
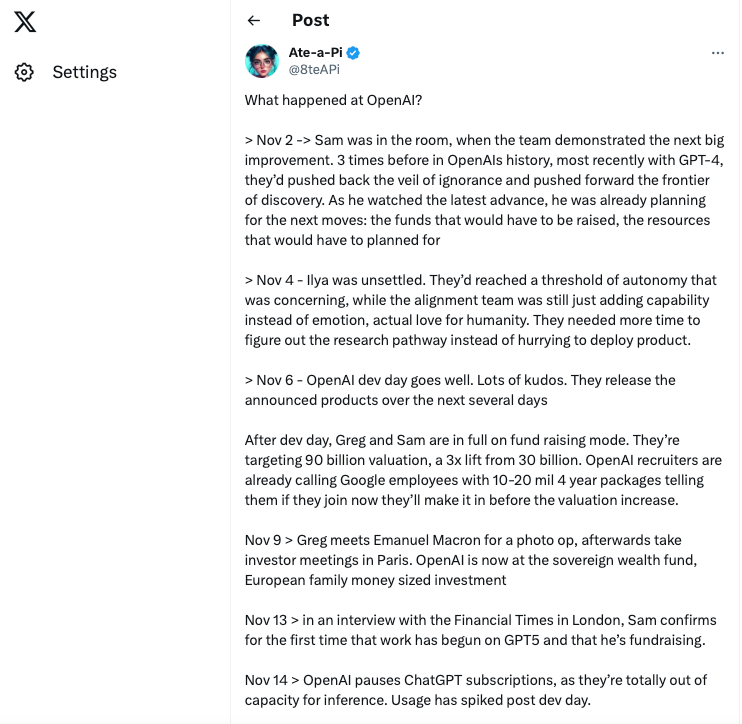
This X post has gained 3M views so far, with equally attractive engagement:
Approximately 912 reposts, 280 quotes, 7000 likes, and 4500 bookmarks as of this writing.
The crux of the matter lay in the first and foremost event: The announcement of the next big improvement that got Sam Altman excited.
At first, the events that followed seemed disconnected from this first event. In a highly talent-concentrated firm like OpenAI, research and improvements are the norm. What’s new?
But if one tries to imagine the scale of the improvement it might be alluding to, one can try beginning to connect the dots.
Probably following this trail, on Nov 23, Reuters posted a sensational story that claimed that OpenAI researchers had warned the board of directors about an AI breakthrough that could threaten humanity.
OpenAI acknowledged the existence of a project codenamed Q* — the answer to OpenAI’s eternal quest for the Artificial General Intelligence (AGI) pinnacle.
For anyone uninitiated (like myself): OpenAI defines AGI as Autonomous systems that surpass humans in most economically valuable tasks.
Why the Q* Project?
Despite its resounding success, the makers of ChatGPT have no doubts about when the LLM-based approach will hit the wall.
This has been rather obvious all along. Gary Marcus, a regular critic of GPT, has said it much earlier. He, in fact, went as far as calling deep learning a fundamentally inaccurate technique:
Deep learning, which is fundamentally a technique for recognizing patterns, is at its best when all we need are rough-ready results, where stakes are low and perfect results optional.
In my 2021 article about the threat GPT posed to writers, I claimed the same thing.
However, only now:
In his most recent speech during the Hawking Fellowship Award, Sam Altman said:
“I think we need another breakthrough. We can push on large language models quite a lot, and we should, and we will do that. We can take our current hill that we’re on and keep climbing it, and the peak of that is still pretty far away. But within reason, if you push that super far, maybe all this other stuff emerged. But within reason, I don’t think that will do something that I view as critical to general intelligence,”
This is coming from someone who has owned it so far. A crucial moment. Not quite surprisingly.
Only now.
ChatGPT and its transformer friends rely on text proximity. However effective, they are quite like students who memorize stuff through rote learning prior to examination time, only to forget it later, never grasping the meaning of the content.
To be effective, LLMs rely on huge computing power and the vocabulary they are trained on.
The magnitude of their capabilities can vary based on parameter tuning, but the variation would still be scale-based.
When the growth relies on scale and scale only, the initial momentum gained via mass adoption will fade sooner or later.
In other words, the assumptions involved in the adoption curve would no longer apply.
To reach from language-based chatbots to the AGI stage, GPT needs something that is akin to what humans are capable of: Consciousness.
My assumption is that Q* is a baby step towards this progress.
What is OpenAI’s Q* Project?
Let’s go back to Reuters story, the part that truly gives out the meat:
Given vast computing resources, the new model was able to solve certain mathematical problems, the person said on condition of anonymity because the individual was not authorized to speak on behalf of the company. Though only performing math on the level of grade-school students, acing such tests made researchers very optimistic about Q*’s future success, the source said.
To dig more, I decided to take a supra-AI approach: Improve upon how ChatGPT answers stuff: Educated guesswork (sometimes better than text proximity 😏).
OpenAI’s research page shows the following papers released during the last 6 months:
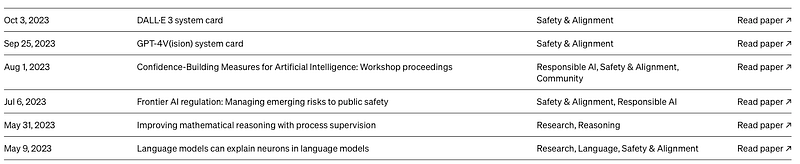
The only entry that matches the Reuters report’s math reference is this paper: Improving mathematical reasoning with process supervision.
The excerpt says:
We’ve trained a model to achieve a new state-of-the-art in mathematical
problem-solving by rewarding each correct step of reasoning
(“process supervision”) instead of simply rewarding the correct final
answer (“outcome supervision”). In addition to boosting performance
relative to outcome supervision, process supervision also has an important
alignment benefit: it directly trains the model to produce a chain-of-thought
that is endorsed by humans.The initial results are astounding, and we are just getting started. The following graph reaffirms that this paper is nearest to what the Reuters article claims:
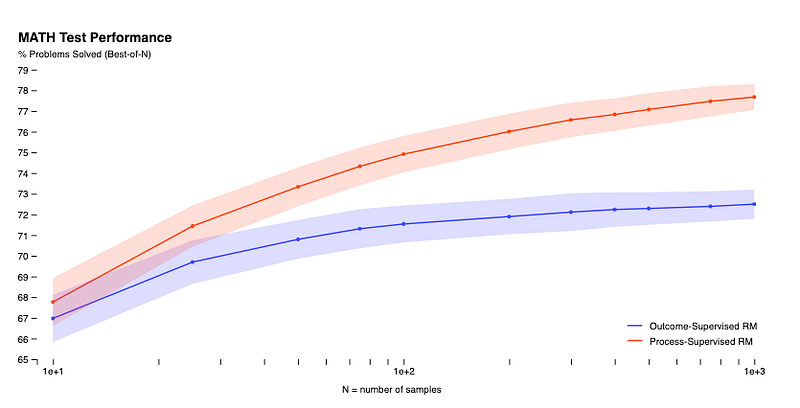
What does this mean? However complex it may be in its proof, here is a simplistic explanation:
The paper outlines the fundamental shift in the approach AI is trained.
Instead of rewarding/punishing AI for the final outcomes, we train it by rewarding/punishing it for the process it follows.
Remember the time of your math exam when you answered a tough question using some cool math acrobatics?
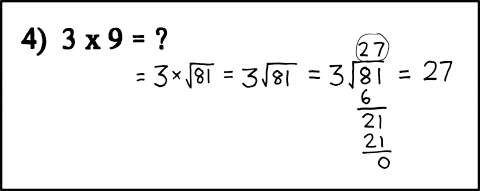
Your friend’s boring solution:
3 x 9 = 3 + 3 + 3 + 3 + 3 + 3 + 3 + 3 + 3 = 27Result: Your friend gets full marks, while you get a zero.
When you question the math teacher, she pulls her hair trying to know how you developed your unique solution. Your answer: Not unlike how LLMs learned.
While your friend’s approach is laborious and verbose, there are better and more efficient ways to express it. Your approach will fail on the question: What’s 3 x 10?
Back to the math story: Out of her true compassion, the math teacher explains to you the reasoning and the right way to get 27 from 3 x 9.
Result? You would never get it wrong again.
How does process supervision draw AI nearer to (or above) human intelligence?
Let’s take the example that made AI famous in the mainstream: The cat vs dog classification problem. The most primitive training approach keeps iterating pixels until a human says: It’s a cat/dog.
If an AI model does it in a quicker, more elegant way, it is simply an iteration on top of this primitive approach.

While correct, this approach is far behind how an adult human brain learns and creates new concepts.
From a human cognition standpoint, all knowledge is additive and classified. The brain constructs bigger ideas from smaller ones, and it can apply attributes based on similarities/differences.
When a human brain thinks about constructing a cat image, it thinks of 2 things:
- A cat is biologically nearer to a dog, and I remember the entire dog’s anatomy along with its differences from a cat’s.
- A cat can be constructed from a cat’s parts, just like a dog can be constructed from dog parts.
Deconstructing is how we solve problems and engineer solutions. When this approach is adopted by AI, the constructs it relies upon while generating responses (text/audio/video) will be much more meaningful.
- From a poorly formatted suicide note, it could outline assumptions, inferences, and conclusions, without those explicit headings it is trained on, from scientific papers.
- It could understand novel poetry without having to search for its style in the literature.
- It could derive math formulas by recognizing patterns.
This approach could take GenAI to a point where creating content would be much akin to how reusable functions replace repetitive code fragments of the old-school procedural programming era, and how OOP templates replace type-dependent classes.
Conclusion:
I must say: That was an utterly uninformed oversimplification of Q*. And I am truly out of options here.
As I am writing this, the world outside OpenAI doesn’t know what Q* actually is.
Q* could as well be a marketing hyperbole driven by sheer valuation grid
A perfect research paper is far from a successful product, let alone mass-adopted technology. However, the sheer amount of possibilities it represents explains a lot of what happened during the past week.
We may probably never know about Q*, due to enormous stakes around its commercialization and public release.
In an alternate storyline:
- Is OpenAI leadership criticizing its own LLM because they have a better poster child now that can skyrocket its private stock through the roof?
- Is Q* simply a hyperbole created by a startup camp that is tempted to take it to the trillion-dollar valuation sooner than its FAAMG predecessors?
- Is the recent battle between Sam Altman + employees vs the board part of the constantly ongoing war within OpenAI, between sheer greed and altruistic goals for human-centered AI?
Either way, one thing is for sure: The world will never be the same once the truth about Q* is out.
For better or worse? Only time will tell.
Want to write for Medium, and read every story on it?
Want to get an email every time Pen Magnet publishes? Click here to join his subscriber list.
Pen Magnet is the author of the popular senior developer interview eBook:
Comprehensive Approach to Senior Developer Interview (40+ example questions)