
Is Koalas the new Pandas?
Well… not just yet!

Last week, during the Spark + AI Summit 2020, Koalas 1.0 was released. Here is the demo in case you are curious.
Koalas is bringing to the data science world the promise of translating the Pandas API into PySpark seamlessly. A dream come true! 🤩 Right?
Pandas is one of the most used tools for data wrangling and analysis, however, it does not scale well when dealing with big data sets. At the moment, when faced with big data, most data scientist have to either migrate to PySpark (which has a significantly different syntax) or sample their data to be able to use Pandas. Therefore, Koalas will bring the best of both worlds by allowing data scientists to scale their projects using the good old Pandas syntax.
Does that mean that…?
One brilliant Twitter user asked if that means that we can just do: import databricks.koalas as pd 🔥🐨🐼
In this post, we will put that to the test.
Installing Koalas
First, you have to install Koalas using:
pip install databricks
pip install koalas(Note: You also have to have Spark installed in your environment.)
Let’s compare!
Before I begin, let me clarify that in this post I will test whether or not Koalas has the same functionalities as Pandas, not its speed.
path = "sample.csv"1. Test #1: Loading a CSV file
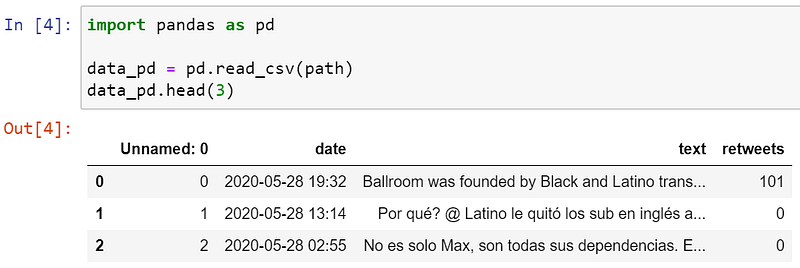
🐼 Pandas
🐨 Koalas
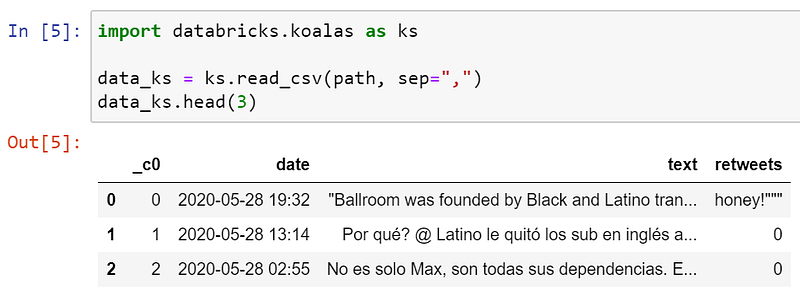
Uh, oh! Koalas has trouble reading some of the lines that contain a comma.
2. Test#2: Sample your dataset
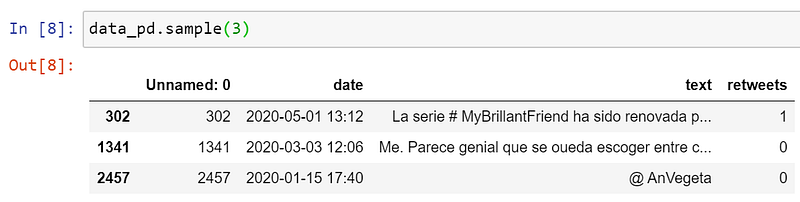
🐼 Pandas
🐨 Koalas
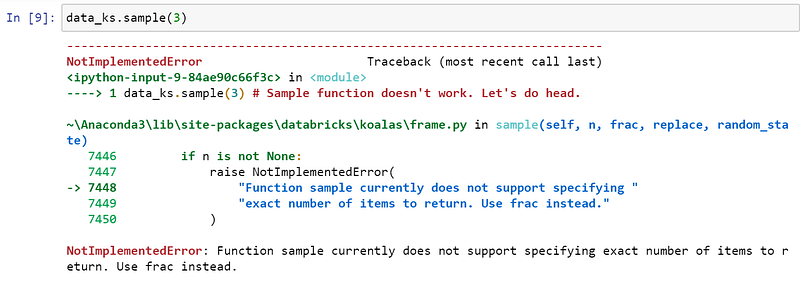
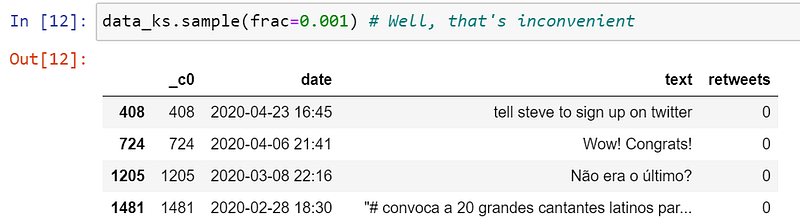
Uh, oh! According to Koalas documentation, they have an n parameter for the number of items to return but it is still not supported, so you have to use frac instead, which will return a fraction of items on the selected axis.
3. Test#3: Dropping and renaming columns
🐼 Pandas

🐨 Koalas
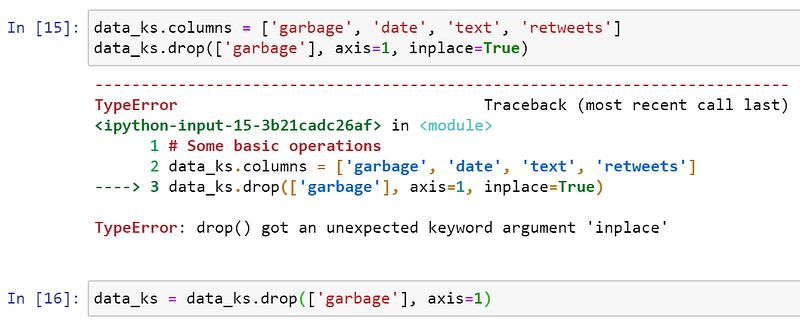
Uh, oh! In Koalas the parameter inplace is not implemented, therefore you have to reassign the result to your variable.
4. Test#4: Dealing with datetime columns
🐼 Pandas

🐨 Koalas
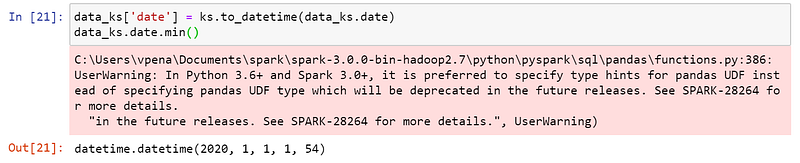
Koalas is not happy about that syntax, but it also got the job done.
5. Test#5: Lambda time!
🐼 Pandas

🐨 Koalas

Seamless! This is really, really nice because using PySpark we would have had to create an ugly UDF (user-defined function).
6. Test#6: Describe
🐼 Pandas
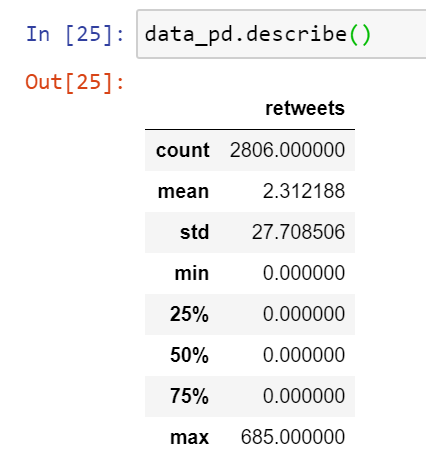
🐨 Koalas

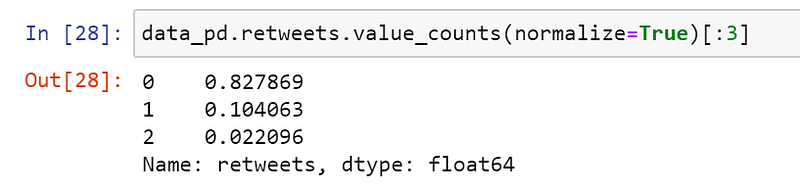
7. Test#7: Value Counts
🐼 Pandas
🐨 Koalas
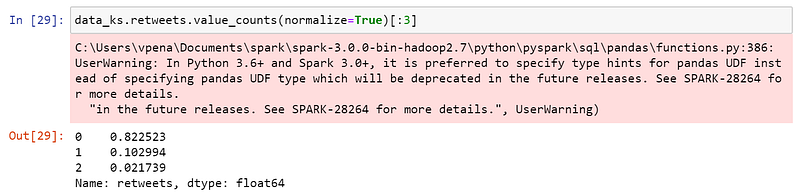
Koalas cried again, but it did the job!
Conclusions
Koalas is still far from being a 100% seamless transition from Pandas to Spark, however, this is just its first release and I am hopeful that the open-source community will make out of Koalas one of the most powerful tools in the Python world 🔥
On a side note, Koalas is very slow when dealing with small datasets. This is expected to happen as Spark is meant to deal with big datasets, nevertheless, I would love to see Koalas getting smart enough to switch under the hood between Pandas and Spark depending on the context.





