
Is Hadoop Dead?
What is the Future of the Big Data Ecosystem?

Hadoop is a Java-based software framework and is used to process large amounts of data on distributed systems at high speed. It is suitable for handling data processing in the Big Data environment. It is, or at least was, the system that accompanied the new era of enterprises into the world of Big Data. But what does it look like today? More and more solutions, especially those from the large cloud providers, are competing against each other these days.
Components of Hadoop
Hadoop is made up of individual components. The four central building blocks of the software framework are [1][2]:
- Hadoop Common
- Hadoop Distributed File System (HDFS)
- MapReduce algorithm and
- Yet Another Resource Negotiator (YARN).
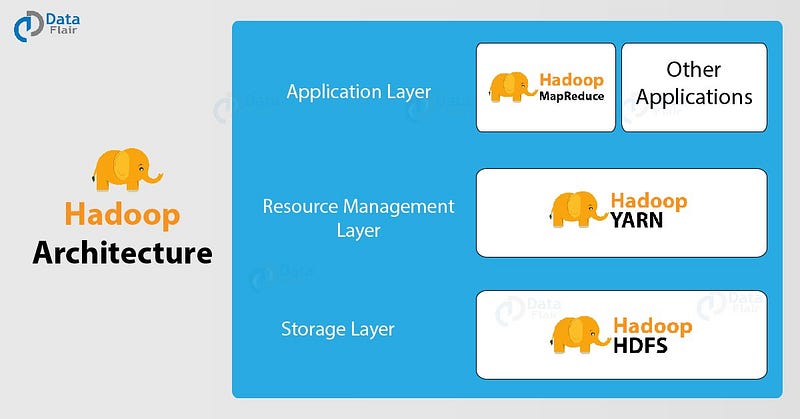
Hadoop Common provides the basic functions and tools for the other building blocks of the software, while the Hadoop Distributed File System is a system that can be used to store data on different systems in a computer network. This makes it possible to store large amounts of data. The central engine of Hadoop is the MapReduce algorithm, the basic features of which were developed by Google. The algorithm provides various functions that allow complex and computationally intensive tasks to be split into many small individual parts across multiple computers. The Yet Another Resource Negotiator is a kind of supplement to the MapReduce algorithm. It can manage the resources in a computer cluster and dynamically assign resources of a cluster to different jobs. YARN uses queues to determine the capacities of the systems for the individual tasks [1,2].
The Competition from SaaS solutions
From my own experience, I know that providing the infrastructure for data analysis and business intelligence solutions can tie up a lot of resources. Money, because you buy the infrastructure in the long term, if you run it on-premise and with large amounts of data and the creation of computationally expensive Data Science Task these must continuously expand, while you rent it as a SaaS solution, if you ever need more. In addition, also the whole issue of operating and building the individual components and operating clusters ultimately ties up IT staff.
Of course, Hadoop and its own operation also has advantages, you do not have to rely completely on the cloud provider and may also have advantages in the area of data protection. At least as a European and within the framework of the GDPR.
Why companies could rely more on other Solutions in the Future
In the figure below, you can see an architecture from a high-level-view. The process is that unstructured and untransformed data is loaded into a Data Lake. From here, data can be used, one the one hand, for ML and Data Science tasks. On the other hand, the data can be also transformed and loaded into the Data Warehouse in a structured form. From here, the classical Data Warehouse distribution of the data via Data Marts and (Self Service) BI tools can be realized.
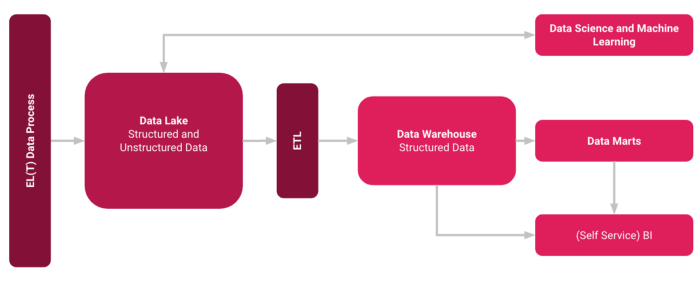
The fact that most of the technologies can be obtained from a single source makes it much easier to set up such data platforms. Which is an advantage for smaller companies. For example, once the data has been loaded into the Data Warehouse, it can be processed further for ETL and Data Marts processes relatively easily via existing interfaces and usually with little programming effort.
Such solutions are mainly offered by the large cloud providers such as Amazon, Google or Microsoft Azure. The advantage here, as already mentioned, is that the company can concentrate on the value-adding activities and leave the infrastructural structure and scaling to the provider.
Summary
So there are good reasons for companies to rely more on solutions from the major cloud providers in the future. As these are modern cloud/SaaS solutions, they are usually easier to use and provide more resources. They are also usually well connected with each other so that Data Warehouse, BI and machine learning can be easily combined. Another indicator can be the following statistic. Here, a clearly negative trend of the popularity of Hadoop can be seen.
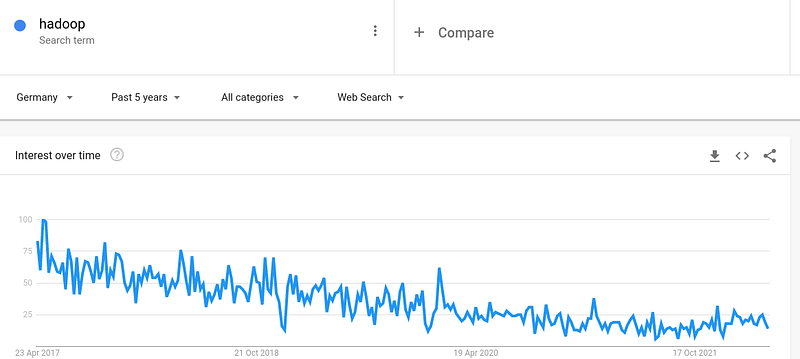
In summary, Hadoop is still a powerful system, but is increasingly facing competition. In the future, companies will probably rely on other solutions, but Hadoop will of course continue to exist in many companies for a while.
Sources and Further Readings
[1] Stefan Luber, Nico Litzel, Was ist Hadoop?(2016)
[2] Medono Zhasa, What Is Hadoop? Components of Hadoop and How Does It Work (2022)
[3] Data Flair, Hadoop Architecture in Detail — HDFS, Yarn & MapReduce (2022)
[4] Google Trends, Search Term Hadoop (2022)





