

Is AI A Truly Disruptive Technology?
The argument for yes
I’ve been thinking about this for a while — is AI a truly disruptive technology? I’m still not convinced that it is. But to play devil’s advocate to myself let me spend today’s post arguing that it is.
The traditional way that the world’s leading knowledge companies like Google, Microsoft, and Facebook seem to know everything about everything is knowledge graphs. You can imagine a knowledge graph as a bunch of connected nodes where the nodes can be concepts, people, places, ideas, etc. and the edges between the nodes encode the relationship (and sometimes the strength of the relationship as well).
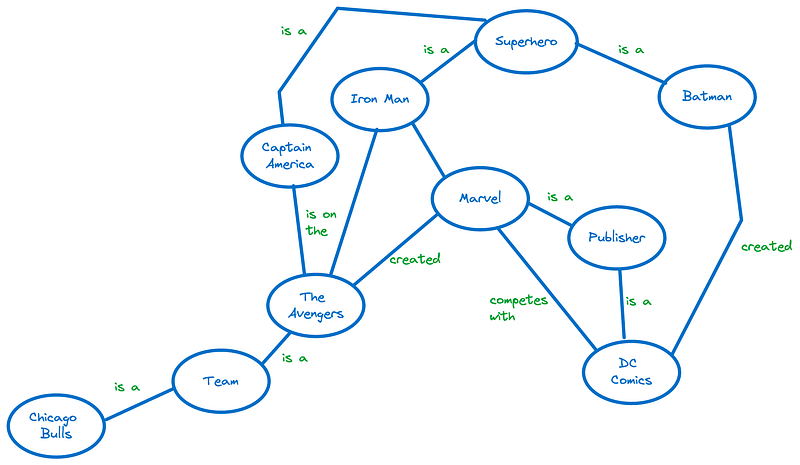
In the example above, we can infer from the graph that:
- Marvel is a publisher and competes with DC Comics.
- Iron Man and Captain America are on the Avengers which is a team created by Marvel.
- Batman is a superhero and was created by DC Comics.
The bigger you can build your knowledge graph in terms of breadth (holding all the entities in the world) and depth (encoding all the relationship types between entities in the world), the better you can answer questions or respond to search queries. This is the thing that butters the bread of companies like Google, which over the years has built the biggest and best knowledge graph in the world. On top of that Google has invested billions in optimizing its ability to both update the graph (as relationships change) and retrieve information from it at lightning speed.
So how might AI disrupt all this?
To understand this, we need to first understand a little about how AI works under the hood. At the heart of most machine learning models, including the current generation of AI LLMs (Large Language Model) such as ChatGPT, is a transformer.
Transformers are sequence to sequence models — meaning that they take a sequence of words (it can be other types of data as well), encode it into a numerical representation of those words (that has meaning to computers) a.k.a. a thought vector, and then do something with that thought vector. For example, an English to Japanese translation model would turn a given English sentence into a thought vector and then find the sequence of Japanese words that most closely matches that thought vector and return that as the output.
Similarly, a LLM given a question turns it into a question thought vector, uses that question thought vector to generate a predicted answer thought vector (because it’s been trained to do so on massive amounts of data), and turns that answer thought vector into understandable English.
The keys are these thought vectors, which you can think of as a long string of numbers — where the numbers represent coordinates in a latent space. And these coordinates encode the meaning of that thought (a.k.a. sequence of words). This is similar to word embeddings except where with something like word2vec, once trained, a word has just a single embedding, transformers are able to shift the thought vectors based on context. In other words, a transformer knows that Michael Jordan has a very different meaning (and different vector representation) in the following sentences:
“Michael Jordan won 6 championships.”
“Michael Jordan was great in the Rocky spinoff.”
It can tell the difference between MJ the athlete and MJ the actor, because it understands context (by using the rest of the sentence as context clues). Which if you step back for a second sounds a lot like a knowledge graph (which knows about the two MJs because in the graph there are two separate MJ nodes, one tagged as an athlete and one tagged as an actor). So in essence, current generation AI models like ChatGPT are able to construct from scratch enormous knowledge graphs. Of course, it requires training on massive amounts of data and at least tens of millions of dollars in GPU compute time. But that’s a rounding error compared to what Google has spent to put together its knowledge graph.
Of course, ChatGPT is more than just a knowledge graph — a lot of effort (and human intervention) was used to get it so that its responses sounded like something a human would say. But how ChatGPT says something (and whether it’s grammatically correct) is independent to what it actually says (i.e. whether the data in its response is right). The latter is the important part and what search engines like Google have built their economic moats with.
Now companies are able to replicate this knowledge graph in a good enough way using just a bunch of Internet data and a bunch of GPUs. Suddenly that moat looks a lot less wide that it did just a year ago.
Search has been such a monopoly the past few decades because it’s winner-take-all. Given that it’s a free service, there’s no reason or financial incentive to use the second best search engine when you can use the best. So whatever search engine cements its reputation as the best like Google did gains a huge advantage — its dominant market share allows it to keep reinvesting in its graph and infrastructure to compound that dominance.
The primary vector of competition in search up until last year has been correctness — whoever is perceived as most correct wins the most market share. ChatGPT and competing AI models upend the rules of the game via their ability to explain to you the answer in a pleasing way (e.g. like you’re 5, via an example, or without any math equations). They’re attempting to disrupt things by making the user interface and user experience more important while commoditizing the graph. If they’re successful, it will open companies like Google to competition in a way that they’ve never encountered before. It’s also why there’s suddenly a mad rush by social media companies to wall data off behind price walls — otherwise AI will scrape your data, learn from it, and commoditize it.