
Introduction to SURF (Speeded-Up Robust Features)
The SURF method (Speeded Up Robust Features) is a fast and robust algorithm for local, similarity invariant representation and comparison of images. The main interest of the SURF approach lies in its fast computation of operators using box filters, thus enabling real-time applications such as tracking and object recognition. The SURF framework described in this paper is based on the Ph.D. thesis of H. Bay [ETH Zurich, 2009], and more specifically on the paper co-written by H. Bay, A. Ess, T. Tuytelaars, and L. Van Gool.

This is part of a 7-series Feature Detection and Matching. Other articles included
- Introduction To Feature Detection And Matching
- Introduction to Harris Corner Detector
- Introduction to SIFT (Scale-Invariant Feature Transform)
- Introduction to FAST (Features from Accelerated Segment Test)
- Introduction to BRIEF (Binary Robust Independent Elementary Features)
- Introduction to ORB (Oriented FAST and Rotated BRIEF)
SURF is composed of two steps
- Feature Extraction
- Feature Description
Feature Extraction
The approach for interest point detection uses a very basic Hessian matrix approximation.
Integral images
The Integral Image or Summed-Area Table was introduced in 1984. The Integral Image is used as a quick and effective way of calculating the sum of values (pixel values) in a given image — or a rectangular subset of a grid (the given image). It can also, or is mainly, used for calculating the average intensity within a given image.
They allow for fast computation of box type convolution filters. The entry of an integral image I_∑ (x) at a location x = (x,y)ᵀ represents the sum of all pixels in the input image I within a rectangular region formed by the origin and x.
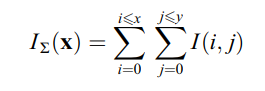
With I_Σ calculated, it only takes four additions to calculate the sum of the intensities over any upright, rectangular area, independent of its size.
Hessian matrix-based interest points
Surf uses the Hessian matrix because of its good performance in computation time and accuracy. Rather than using a different measure for selecting the location and the scale (Hessian-Laplace detector), surf relies on the determinant of the Hessian matrix for both. Given a pixel, the Hessian of this pixel is something like:
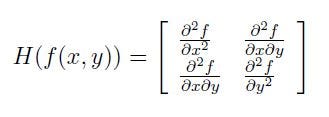
For adapt to any scale, we filtered the image by a Gaussian kernel, so given a point X = (x, y), the Hessian matrix H(x, σ) in x at scale σ is defined as:
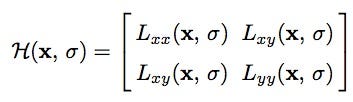
where Lxx(x, σ) is the convolution of the Gaussian second order derivative with the image I in point x, and similarly for Lxy (x, σ) and Lyy (x, σ). Gaussians are optimal for scale-space analysis but in practice, they have to be discretized and cropped. This leads to a loss in repeatability under image rotations around odd multiples of π /4. This weakness holds for Hessian-based detectors in general. Nevertheless, the detectors still perform well, and the slight decrease in performance does not outweigh the advantage of fast convolutions brought by the discretization and cropping.
In order to calculate the determinant of the Hessian matrix, first we need to apply convolution with Gaussian kernel, then second-order derivative. After Lowe’s success with LoG approximations(SIFT), SURF pushes the approximation(both convolution and second-order derivative) even further with box filters. These approximate second-order Gaussian derivatives and can be evaluated at a very low computational cost using integral images and independently of size, and this is part of the reason why SURF is fast.
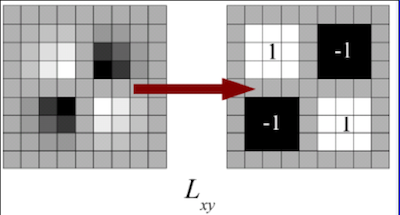
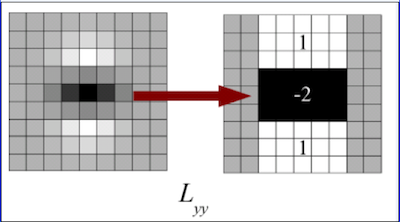
The 9 × 9 box filters in the above images are approximations for Gaussian second order derivatives with σ = 1.2. We denote these approximations by Dxx, Dyy, and Dxy. Now we can represent the determinant of the Hessian (approximated) as:
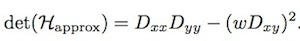
Scale-space representation
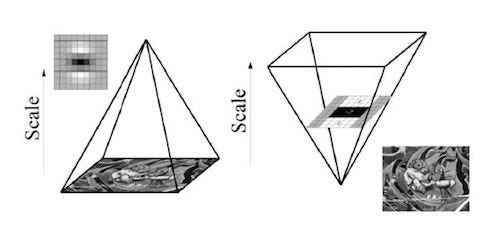
Scale spaces are usually implemented as image pyramids. The images are repeatedly smoothed with a Gaussian and subsequently sub-sampled in order to achieve a higher level of the pyramid. Due to the use of box filters and integral images, surf does not have to iteratively apply the same filter to the output of a previously filtered layer but instead can apply such filters of any size at exactly the same speed directly on the original image, and even in parallel. Therefore, the scale space is analyzed by up-scaling the filter size(9×9 → 15×15 → 21×21 → 27×27, etc) rather than iteratively reducing the image size. So for each new octave, the filter size increase is doubled simultaneously the sampling intervals for the extraction of the interest points(σ) can be doubled as well which allow the up-scaling of the filter at constant cost. In order to localize interest points in the image and over scales, a nonmaximum suppression in a 3 × 3 × 3 neighborhood is applied.
Feature Description
The creation of SURF descriptor takes place in two steps. The first step consists of fixing a reproducible orientation based on information from a circular region around the keypoint. Then, we construct a square region aligned to the selected orientation and extract the SURF descriptor from it.
Orientation Assignment
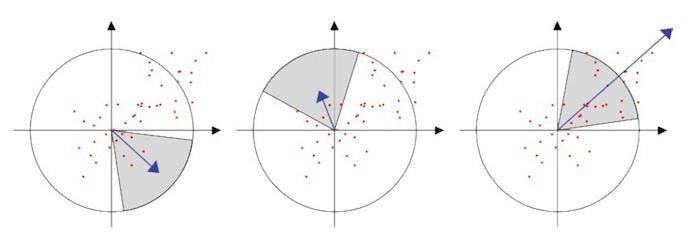
In order to be invariant to rotation, surf tries to identify a reproducible orientation for the interest points. For achieving this:
- Surf first calculate the Haar-wavelet responses in x and y-direction, and this in a circular neighborhood of radius 6s around the keypoint, with s the scale at which the keypoint was detected. Also, the sampling step is scale dependent and chosen to be s, and the wavelet responses are computed at that current scale s. Accordingly, at high scales the size of the wavelets is big. Therefore integral images are used again for fast filtering.
- Then we calculate the sum of vertical and horizontal wavelet responses in a scanning area, then change the scanning orientation (add π/3), and re-calculate, until we find the orientation with largest sum value, this orientation is the main orientation of feature descriptor.
Descriptor Components
Now it’s time to extract the descriptor
- The first step consists of constructing a square region centered around the keypoint and oriented along the orientation we already got above. The size of this window is 20s.
- Then the region is split up regularly into smaller 4 × 4 square sub-regions. For each sub-region, we compute a few simple features at 5×5 regularly spaced sample points. For reasons of simplicity, we call dx the Haar wavelet response in the horizontal direction and dy the Haar wavelet response in the vertical direction (filter size 2s). To increase the robustness towards geometric deformations and localization errors, the responses dx and dy are first weighted with a Gaussian (σ = 3.3s) centered at the keypoint.
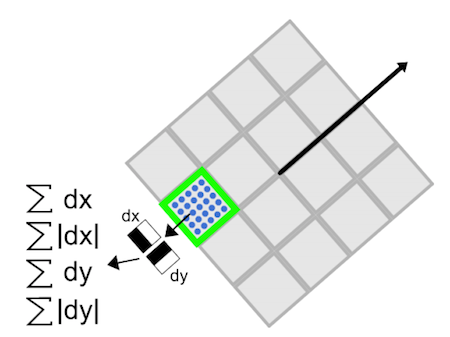
Then, the wavelet responses dx and dy are summed up over each subregion and form a first set of entries to the feature vector. In order to bring in information about the polarity of the intensity changes, we also extract the sum of the absolute values of the responses, |dx| and |dy|. Hence, each sub-region has a four-dimensional descriptor vector v for its underlying intensity structure V = (∑ dx, ∑ dy, ∑|dx|, ∑|dy|). This results in a descriptor vector for all 4×4 sub-regions of length 64(In Sift, our descriptor is the 128-D vector, so this is part of the reason that SURF is faster than Sift).
Implementation
I was able to implement SURF using OpenCV. Here’s how I did it:
Github link for the code: https://github.com/deepanshut041/feature-detection/tree/master/surf
References
- https://docs.opencv.org/3.0-beta/doc/py_tutorials/py_feature2d/py_surf_intro/py_surf_intro.html
- https://in.udacity.com/course/computer-vision-nanodegree--nd891
- https://www.vision.ee.ethz.ch/~surf/eccv06.pdf
- http://eric-yuan.me/surf





