
Introduction to Spark Architecture
It is an Open Source, Unified Analytics Engine for Large Scale Data Processing.
Why Spark?
Although we have MapReduce for Handling large Volume of Data. The process involves in Reading and Writing the Data is Little time Consuming.
But Spark helps us to handle data in Lightening Speed and also it can be used for Real Time Data Processing.
The Speed of Spark is due to the In-Memory Computation method and also it uses DAG Scheduler. (Directed Acyclic Graph).
Features of Spark
- It supports various Languages like Java, Sql, Python.
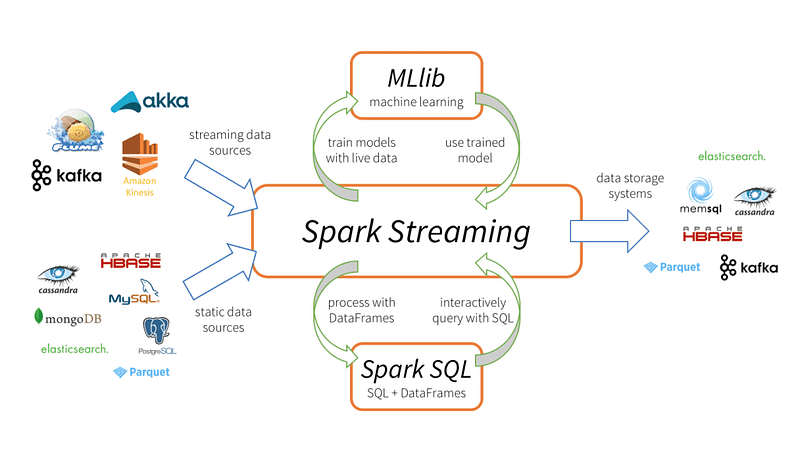
- It supports various Libraries like Spark SQL, Spark Streaming, MLlib, GraphX.
- Spark can use its standalone cluster Manager to run on Apache Mesos, Hadoop Yarn or Kubernetes.
- It can Access data stored in HDFS, S3 and any other Local Storage
- It uses Lazy Evaluation Process as it is the reason for speed of spark.
Difference Between Spark and HDFS?
HDFS -> It acts as a Data Storage Layer. Hadoop is a combination of HDFS and MapReduce Spark -> It acts as a Data Processing Layer. Spark can use HDFS as a data Storage Layer.
UseCases
Following are the places, where spark is largely used
Ecommerce -> for Data Analysing their sales and inventory effectively. Banking -> to Analyse data for Fraud Detection Ola & Uber -> to analyse real time data for calculating price and availability of drivers Personalised Ads -> Based on user’s browser history
Spark vs MapReduce
There are two types of Storage system available generally. They are
- In-Memory
- Disk
MapReduce follows Disk Based Processing System in which the data are stored in the Hard Disk.
Example
If you are trying to process a data, it actually follows up 2 phases. i.e Map & Reduce. In Map, data is fetched form the disk and it is processed and transformed into partition as an intermediate Result and stored in disk. In Reduce, the intermediate Result is fetched from the disk again and it is processed as input and the final result is again stored in the disk.
So lets discuss about the different time delays which happen’s during this Entire process.
Seek Time :
The Time taken by the Read/Write head to move from Current position to New Position.
Rotational Delay :
It is the time taken by the disc to rotate so that it brings the Read/Write head point to the beginning of the data.
Transfer Time :
It it the time taken to Read/Write the data From and To the hard disk.
Access Time :
It denotes the total time Delay between the Request Submitted and the Response Received.
Access Time = Seek Time + Rotational Delay + Transfer Time
MapReduce is useful to read data from large files in small quantity as the number of head movement will be less and the time consumption will be handles effectively.
Why use In-Memory and Why not use Disk Storage?
- If data is stored in-memory, random access is possible whereas it is time consuming in disk as it only allows sequential storage
- Real time data processing is fast, so here in-memory is used as we need immediate results to get processed immediately.
- Immediate results includes two category’s as Interactive Results and Iterative Results are stored in-memory and can be used for further computation
Example Scenario for Iterative Results in Mapreduce and Spark:
If we need to process the data iteratively, in MapReduce after each map and reduce process the data need to be stored in Disk and need to be fetched again which is time consuming.
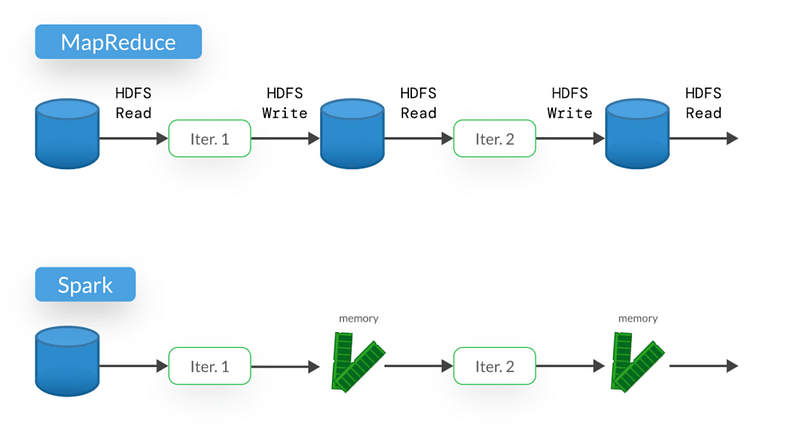
In Spark, we use in-memory storage so the process does not take any extra memory and time for storage and retrieval as it uses lighting speed and the process will be efficient.
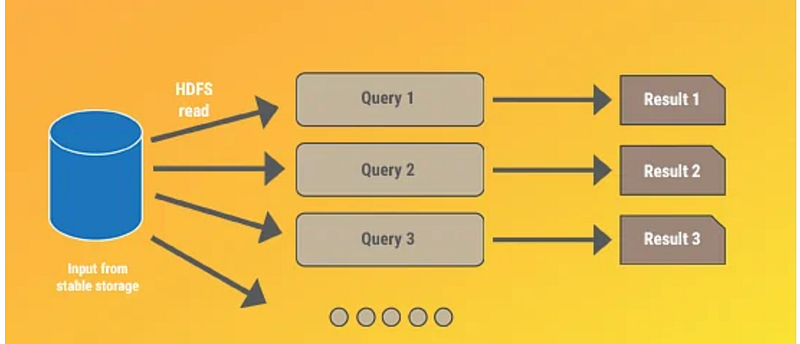
Example Scenario for Interactive Results in Mapreduce and Spark:
In MapReduce, whenever any query need to be processed, then the data need to fetched from the disk for each time and to be processed. It is time consuming process when compared to spark.
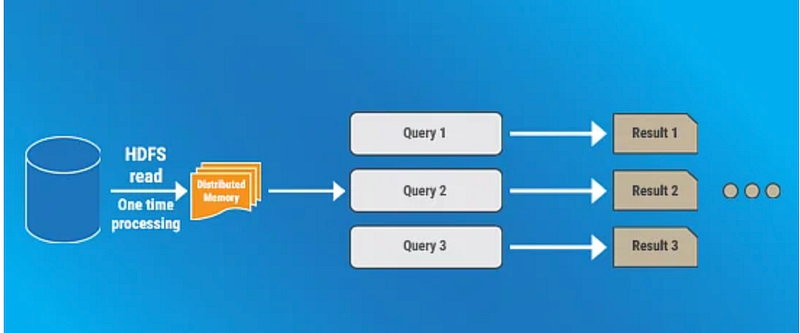
In Spark, the data is stored in the distributed memory. The data is loaded into the distributed memory from the disk as a HDFS read process and it happens once. So even for multiple queries the data’s are fetched from this distributed memory and can be efficient.
Types of Processing
Batch Processing
Data collected over a period of time and is stored in the form of batch also the result cannot be expected immediately. As a result this process in time consuming and does not need any high speed processing frameworks.
Real Time Processing
Instant Responses and high Speed processing. Eg: Banking for Fraudulent Detection.
I hope this article would have given you an idea about why spark and what’s the difference between spark and MapReduce.
Happy learning 😄
Kindly help us to grow by following this publication




