
Introduction to Recurrent Neural Networks
Exploring the Intricacies of Recurrent Neural Networks: From Voice Assistant Technologies to Advanced AI Memory Processing
The Role of RNNs in Modern AI Applications
Siri, look up “Recurrent Neural Networks.” Alexa, play “Memories” by Maroon 5. Have you ever wondered how these virtual voice assistants respond to such varied commands? They operate using an advanced form of AI technology known as Recurrent Neural Networks. But there’s more than just technological wizardry at play here. Have you considered how the default female voice and persona of these assistants might reinforce certain gender biases? For an intriguing exploration of this topic, be sure to check out “Echoes of Yesterday: AI’s Unchanged Gender Dynamics”. If you’re new to the world of neural networks, I recommend beginning your journey with my comprehensive two-part introduction to neural networks (Part 1 and Part 2).
An Analogy for Understanding RNNs: The College Ice Breaker
Do you recall your freshman year in college? If you’re a freshman now, beware of this ice breaker! Our dorm resident advisor subjected everyone on our floor to a dreadful ice breaker. We sat in a circle and each had to introduce ourselves, but with a twist: each person also had to reintroduce every person who came before them. So, the first lucky soul introduced themselves with ease, the second person introduced person 1 and themselves, the third person introduced persons 2, 1, and themselves, and so forth. This cumulative memory task is analogous to how RNNs operate, with each new piece of information (or person introduced) being considered in the context of what has already been processed.
How RNNs Process Information: The Power of Sequential Memory
Just like this anxiety-inducing icebreaker, RNNs pass information from one step to the next in a sequence. Each word, like each person’s name in our game, is a timestep in the sequence the RNN processes. But unlike us mere mortals who might falter in our recollection, RNNs have a form of ‘perfect memory.’ Through hidden states — think of these as sticky notes where essential bits are jotted down — RNNs remember the inputs they process and use this memory to inform the processing of new inputs. This makes them excellent at handling tasks that involve sequences, where the order of inputs — like the words in a sentence or notes in a melody — crucially impacts the outcome.
The Feedback Loop: RNNs’ Unique Feature
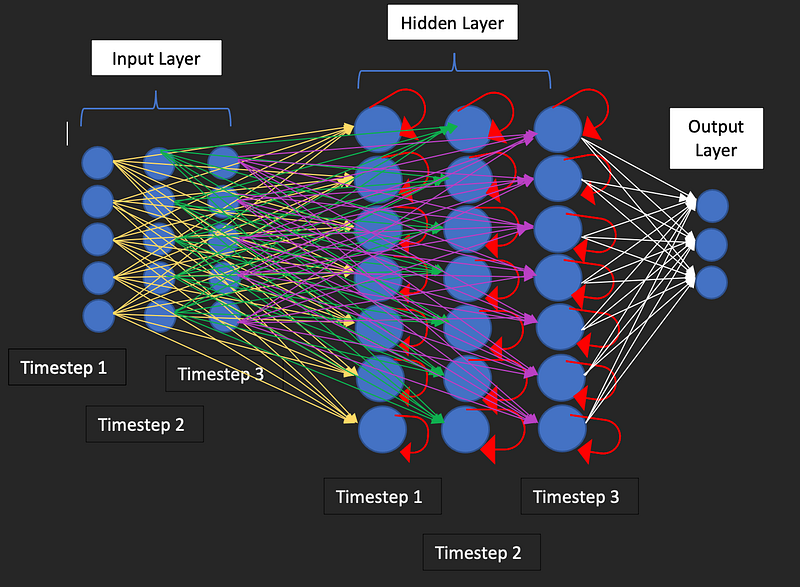
The memory of RNNs is possible because, unlike a Feedforward Neural Network where information flows in only the forward direction, in RNNs, the information can cycle through the network in a loop. Like any other neural network, RNNs receive data in the input layer, but not the entire sequence all at once. In the ice breaker example, when the first person, let’s say me, says “My name is Shalise Ayromloo” (I might have never gone first in the ice breaker, but I’m authoring this blog, so I get to set the scene!), the sentence isn’t input all at once. Instead, the words “My”, “name”, “is” etc., are processed sequentially.
Contextual Data Processing in RNNs: An Interactive Example
Each word is processed and passed to a hidden layer. This is where the “loop” part of an RNN comes into play. Unlike in other neural networks we’ve discussed, where neurons in a hidden layer are only connected to neurons in the preceding and following layers, in an RNN, each neuron in the hidden layer is also connected to itself through a mechanism known as a feedback loop. This loop enables the neuron to retain a form of memory, much like our brains do when trying to remember a series of names.
When the network processes the first input, it generates a hidden state in the hidden layer based on that input. When it moves on to the next input, it doesn’t just use that next input. It also uses the hidden state from the previous input, which acts as a form of short-term memory. This allows the network to maintain a context over time.
The hidden state is like the neuron’s memory. It remembers what happened with the previous input. This memory gets updated each time a new input comes in, allowing the RNN to “learn” from the sequence of data it’s processing.
So, when the second person in our ice breaker introduces themselves and says, “My name is John Doe”, the network doesn’t just process this information on its own, but it also considers the information stored in the hidden state, which is the memory of the first person’s introduction. In this way, the network “remembers” the first person’s introduction when processing the second person’s introduction.
When the second person repeats the first person’s name (“Her name is Shalise Ayromloo”), this is part of the new input being processed, but the network is also using its “memory” (the information in the hidden state) to understand this new input in the context of the previous input.
Finally, based on the information processed in the hidden layers, the output layer generates the final output. It’s worth mentioning that the memory of RNNs are not as perfect as I made it out to be and RNNs do struggle with long sequences of data, known as the “long-term dependency” problem. This is where more advanced RNNs like LSTM (Long Short-Term Memory) and GRU (Gated Recurrent Units) networks come in, offering more sophisticated mechanisms for managing memory over longer sequences. But that’s a topic for another day!