Introduction to Consistent Hashing in Golang

If you enjoy reading medium articles and are interested in becoming a member, I would be happy to share my referral link with you!
Consistent hashing is a specialized form of hashing technique that has been used extensively in the designing of distributed systems. It allows for the even distribution of data across a distributed environment, and for minimal reshuffling when nodes are added or removed. This technique is fundamental to a lot of distributed systems, including Apache Cassandra and Amazon’s Dynamo.
Understanding Consistent Hashing
In a typical hashing scenario, we have a set of data, and a fixed number of “buckets” that the data is stored in. The bucket a data item ends up in is determined by a hash function. This function will take an input, and produce an output (a hash) which is used to determine the bucket.
However, the issue arises when we add or remove buckets. When this happens, we need to remap all of our data, which can be a costly operation.
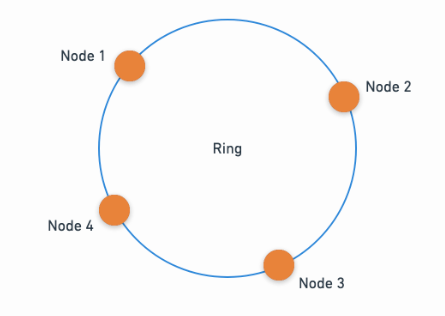
This is where consistent hashing comes in. Consistent hashing aims to minimize the need for remapping, by mapping both the data items and buckets to a continuum or a ring, often referred to as the hash ring.
To be more precise Consistent Hashing is a sophisticated and effective strategy used in distributing data across multiple nodes in a system. Its beauty lies in its simplicity and ability to handle scalability with minimal re-distribution of data. In consistent hashing, the hash space is visualized as a ring, with each node and key assigned a position on this ring based on their hash value. Nodes are responsible for the keys that fall between it and its preceding node on the ring. When a new node is added, it is placed on the ring based on its hash value, and only the keys between it and its preceding node are reassigned to it. This minimal reshuffling is what makes consistent hashing popular in large distributed systems, including the world of distributed caches, databases, and content delivery networks. In the event of node failures, the re-distribution of data remains minimal, thereby making consistent hashing a crucial element in fault-tolerant systems as well.
Implementing Consistent Hashing in Go
Let’s create a basic implementation of consistent hashing in Golang.
import (
"crypto/sha256"
"encoding/binary"
"fmt"
)
type HashRing []uint32
func NewHashRing(nodes []string) HashRing {
hashRing := HashRing{}
for _, node := range nodes {
hash := sha256.Sum256([]byte(node))
hash32 := binary.BigEndian.Uint32(hash[:4])
hashRing = append(hashRing, hash32)
}
sort.Slice(hashRing, func(i, j int) bool {
return hashRing[i] < hashRing[j]
})
return hashRing
}
func (r HashRing) GetNode(key string) string {
hash := sha256.Sum256([]byte(key))
hash32 := binary.BigEndian.Uint32(hash[:4])
idx := sort.Search(len(r), func(i int) bool {
return r[i] > hash32
})
if idx == len(r) {
idx = 0
}
return fmt.Sprintf("%x", r[idx])
}In the code above, NewHashRing function creates a new hash ring from a list of nodes. Each node is hashed into a 32-bit integer using SHA-256 and then added to the hash ring. The hash ring is sorted in ascending order.
The GetNode function takes a key, hashes it into a 32-bit integer, and then finds the first node in the hash ring that is greater than the key's hash. If no such node is found, the key is assigned to the first node in the hash ring.
This setup allows us to easily add or remove nodes, and only affect a small portion of the keys.
Adding a Node
In consistent hashing, the impact of adding a node is localized and affects a much smaller subset of the keys compared to traditional hashing. When a new node is added, it takes over responsibility for some of the keys from other nodes.
Let’s illustrate this by modifying the main function in the previous code to add a new node and see how the keys get reassigned:
func main() {
nodes := []string{"node1", "node2", "node3", "node4"}
hashRing := NewHashRing(nodes)
keys := []string{"myKey1", "myKey2", "myKey3", "myKey4", "myKey5", "myKey6", "myKey7", "myKey8", "myKey9", "myKey10", "myKey11", "myKey12", "myKey13", "myKey14", "myKey15", "myKey16", "myKey17", "myKey18", "myKey19", "myKey20"}
fmt.Println("Before adding a new node:")
for _, key := range keys {
fmt.Printf("Key %s is assigned to Node %s\n", key, hashRing.GetNode(key))
}
// Adding a new node
nodes = append(nodes, "node5")
hashRing = NewHashRing(nodes)
fmt.Println("\nAfter adding a new node:")
for _, key := range keys {
fmt.Printf("Key %s is assigned to Node %s\n", key, hashRing.GetNode(key))
}
}Before adding a new node:
Key myKey15 is assigned to Node 3b5bb1c6After adding a new node:
Key myKey15 is assigned to Node 23af4060This demonstrates the property of consistent hashing. When a new node is added to the system (in this case, node5 which corresponds to 23af4060), only a minimal amount of keys are reassigned to it (in this example, just myKey15). This is in contrast to a naive hashing scheme where the addition of a new node might result in most keys being reassigned.
The main advantage of consistent hashing is this minimal reassignment, which is critical in distributed systems where reassignments can be expensive operations. It helps to maintain system performance and availability during scaling operations.
Conclusion
Consistent hashing is a powerful tool in building distributed systems. It provides a solution to the problem of distributing keys evenly across multiple nodes and dealing with nodes joining and leaving the network. This simple yet effective strategy is an integral part of many distributed data storage systems used today.
The Go implementation provided here provides a starting point for understanding and working with consistent hashing. Further enhancement would be adding virtual nodes to improve the distribution, which is a common practice in real-world applications.