
Introducing FinGPT Forecaster: The Future of Robo-Advisory Services
Anticipating Stock Movements with AI-Driven Insights

In the ever-evolving landscape of financial services, the emergence of artificial intelligence as a key player has transformed how we interpret market data and make investment decisions. FinGPT-Forecaster is poised at the cusp of this transformation, signifying a giant leap in the domain of robo-advisory services.
What is FinGPT-Forecaster?
FinGPT-Forecaster is an LLMs model that synthesizes recent market news and relevant financials of a given company to provide a dual output — a rundown of the company’s latest positive strides and potential concerns, as well as a forecast of the stock price movements for the upcoming week, complete with an analytic summary.
Developed with a fine-tuned Llama-2–7b-chat-hf with LoRA, leveraging the latest year’s market data from the DOW 30, FinGPT-Forecaster not only brings precision to predictions for these blue chips but also demonstrates remarkable generalization capabilities across various stock symbols.
FinGPT-Forecaster stands as a testament to the promise and potential of AI in finance, a junior robo-advisor that combines ease of deployment with strategic foresight, marking a significant milestone on our path to the future of automated financial advisory.
Why Build FinGPT-Forecaster?
The vision behind FinGPT-Forecaster goes beyond the mere creation of an algorithmic tool. It is about forging a future where the vast complexities of financial markets are navigated with the assistance of intelligent, automated systems that are accessible, accurate, and user-friendly.
In a financial world where information overload can paralyze even seasoned investors, FinGPT-Forecaster offers a beacon of clarity. By distilling vast amounts of market data into actionable insights, it empowers investors to make well-informed decisions swiftly.
Moreover, it democratizes access to financial expertise. Small investors, who may not have the resources for comprehensive market analysis or professional advisory services.
How to use FinGPT-Forecaster?
FinGPT-Forecaster is hosted on Hugging Face Spaces, allowing anyone with internet access to use it without any cost. It’s the embodiment of open-source philosophy — shared, improved, and used by a community of developers and financial analysts alike.
Inputting Data
To start your forecasting journey, you simply need to:
- Select Your Ticker Symbol: Enter the ticker symbol for the company you are interested in, such as ‘AAPL’ for Apple Inc. or ‘MSFT’ for Microsoft.
- Set Your Date: Choose the specific day (formatted as yyyy-mm-dd) from which you want the prediction to commence.
- Determine the News Timeframe: Decide on the number of past weeks for which you’d like to gather market news. This helps the model to understand recent trends and sentiments.
- Incorporate Financials: Opt-in to add the latest basic financials for a more informed prediction, if desired.
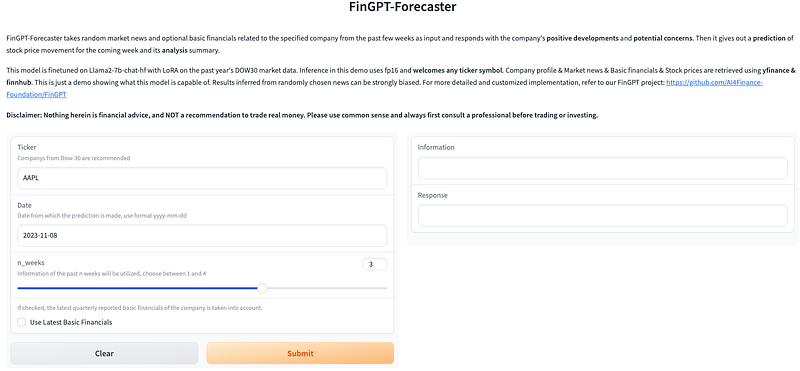
Receiving Your Prediction
Once you click ‘Submit,’ the model leaps into action, processing the inputs through its complex algorithms. In moments, you receive:
- A concise breakdown of the company’s recent positive developments and possible concerns.
- A predictive summary of the expected stock price movement for the subsequent week.
⚠️Warning: This is just a demo showing what this model is capable of. During each individual inference, company news is randomly sampled from all the news from designated weeks, which might result in different predictions for the same time period. We suggest users deploy the original model or clone this space and inference with more carefully selected news in their own favorable ways. Setting do_sample=False or modifying the temperature during the generation process also helps stabilize the prediction result.
AAPL:

TSLA:

V:

AMZN:

GOOGL:

Understanding the Output
It’s important to note that while the FinGPT-Forecaster is a robust model, the demo’s purpose is to exhibit the potential of AI in market forecasting. The results, particularly when based on randomly selected news, may exhibit biases. This is a starting point for financial analysis, not the end-all.
For those seeking to delve deeper into financial analytics, we encourage reading further into the specifics of the model and considering a tailored approach. By integrating FinGPT-Forecaster into your analysis framework, you gain a cutting-edge tool in the pursuit of informed investment strategies.
Remember, FinGPT-Forecaster is more than a technical marvel; it’s your entryway into the future of finance. Whether you’re a hobbyist investor, a professional trader, or simply curious about the convergence of AI and financial markets, this tool is here to enhance your understanding and forecasting abilities. Try it, test it, and see the future of robo-advisory services unfold before you.
How to Train Your Own FinGPT-Forecaster?
At the heart of the FinGPT project lies a commitment to open-source principles. We believe that by sharing knowledge and tools, we can foster a community that innovates and grows together. This is why we’re not just introducing a product but an ecosystem where everyone can contribute and benefit.
The Full Recipe for Innovation
Training your FinGPT-Forecaster isn’t a walk in the park, but we’re here to guide you through each step. To start, you’ll need to prepare the following ingredients:

Prepare Data:
The foundation of any AI model is data. For the FinGPT Forecaster, the data comes in three flavors:
- Company News: Curate a dataset of news articles related to the companies of interest. The more comprehensive and up-to-date this data, the more nuanced the insights your model will provide.
- Company Fundamentals: Collect data that reflects the financial health of these companies. This includes earnings reports, balance sheets, cash flow statements, and more.
- Stock Price: Historical stock price data is crucial as it serves as a reference for your model’s predictions.
Data Preparation Script
To aid you in this process, we offer scripts that streamline the data preparation phase, ensuring that your data is clean, organized, and model-ready.
import os
import re
import csv
import math
import time
import json
import openai
import random
import finnhub
import datasets
import pandas as pd
import yfinance as yf
from datetime import datetime
from collections import defaultdict
from datasets import Dataset
START_DATE = "2022-12-31"
END_DATE = "2023-05-31"
DATA_DIR = f"./{START_DATE}_{END_DATE}"
os.makedirs(DATA_DIR, exist_ok=True)
finnhub_client = finnhub.Client(api_key="your finnhub key")
openai.api_key = 'your openai key'
def prepare_data_for_company(symbol, with_basics=True):
data = get_returns(symbol)
data = get_news(symbol, data)
if with_basics:
data = get_basics(symbol, data)
data.to_csv(f"{DATA_DIR}/{symbol}_{START_DATE}_{END_DATE}.csv")
else:
data['Basics'] = [json.dumps({})] * len(data)
data.to_csv(f"{DATA_DIR}/{symbol}_{START_DATE}_{END_DATE}_nobasics.csv")
return data
DOW_30 = [
"AXP", "AMGN", "AAPL", "BA", "CAT", "CSCO", "CVX", "GS", "HD", "HON",
"IBM", "INTC", "JNJ", "KO", "JPM", "MCD", "MMM", "MRK", "MSFT", "NKE",
"PG", "TRV", "UNH", "CRM", "VZ", "V", "WBA", "WMT", "DIS", "DOW"
]
for symbol in DOW_30:
prepare_data_for_company(symbol)
ticker = "AAPL"
n_weeks = 2
curday = get_curday()
steps = [n_weeks_before(curday, n) for n in range(n_weeks + 1)][::-1]
data = get_stock_data(ticker, steps)
data = get_news(ticker, data)
data['Basics'] = [json.dumps({})] * len(data)
# data = get_basics(ticker, data, always=True)
info, prompt = get_all_prompts_online(ticker, data, curday, False)
print(prompt)

The Training Process
Once your data is prepared, the real magic begins: training your model. It’s a delicate process that involves fine-tuning a complex AI model to understand and predict stock price movements based on the data you’ve fed it.
from transformers.integrations import TensorBoardCallback
from transformers import AutoTokenizer, AutoModel, AutoModelForCausalLM
from transformers import TrainingArguments, Trainer, DataCollatorForSeq2Seq
from transformers import TrainerCallback, TrainerState, TrainerControl
from transformers.trainer import TRAINING_ARGS_NAME
from torch.utils.tensorboard import SummaryWriter
import datasets
import torch
import os
import re
import sys
import wandb
import argparse
from datetime import datetime
from functools import partial
from tqdm import tqdm
from utils import *
# LoRA
from peft import (
TaskType,
LoraConfig,
get_peft_model,
get_peft_model_state_dict,
prepare_model_for_int8_training,
set_peft_model_state_dict,
)
# Replace with your own api_key and project name
os.environ['WANDB_API_KEY'] = 'ecf1e5e4f47441d46822d38a3249d62e8fc94db4'
os.environ['WANDB_PROJECT'] = 'fingpt-forecaster'
class GenerationEvalCallback(TrainerCallback):
def __init__(self, eval_dataset, ignore_until_epoch=0):
self.eval_dataset = eval_dataset
self.ignore_until_epoch = ignore_until_epoch
def on_evaluate(self, args, state: TrainerState, control: TrainerControl, **kwargs):
if state.epoch is None or state.epoch + 1 < self.ignore_until_epoch:
return
if state.is_local_process_zero:
model = kwargs['model']
tokenizer = kwargs['tokenizer']
generated_texts, reference_texts = [], []
for feature in tqdm(self.eval_dataset):
prompt = feature['prompt']
gt = feature['answer']
inputs = tokenizer(
prompt, return_tensors='pt',
padding=False, max_length=4096
)
inputs = {key: value.to(model.device) for key, value in inputs.items()}
res = model.generate(
**inputs,
use_cache=True
)
output = tokenizer.decode(res[0], skip_special_tokens=True)
answer = re.sub(r'.*\[/INST\]\s*', '', output, flags=re.DOTALL)
generated_texts.append(answer)
reference_texts.append(gt)
# print("GENERATED: ", answer)
# print("REFERENCE: ", gt)
metrics = calc_metrics(reference_texts, generated_texts)
# Ensure wandb is initialized
if wandb.run is None:
wandb.init()
wandb.log(metrics, step=state.global_step)
torch.cuda.empty_cache()
def main(args):
model_name = parse_model_name(args.base_model, args.from_remote)
# load model
model = AutoModelForCausalLM.from_pretrained(
model_name,
# load_in_8bit=True,
trust_remote_code=True
)
if args.local_rank == 0:
print(model)
tokenizer = AutoTokenizer.from_pretrained(model_name, trust_remote_code=True)
tokenizer.pad_token = tokenizer.eos_token
tokenizer.padding_side = "right"
# load data
dataset_list = load_dataset(args.dataset, args.from_remote)
dataset_train = datasets.concatenate_datasets([d['train'] for d in dataset_list]).shuffle(seed=42)
if args.test_dataset:
dataset_list = load_dataset(args.test_dataset, args.from_remote)
dataset_test = datasets.concatenate_datasets([d['test'] for d in dataset_list])
original_dataset = datasets.DatasetDict({'train': dataset_train, 'test': dataset_test})
eval_dataset = original_dataset['test'].shuffle(seed=42).select(range(50))
dataset = original_dataset.map(partial(tokenize, args, tokenizer))
print('original dataset length: ', len(dataset['train']))
dataset = dataset.filter(lambda x: not x['exceed_max_length'])
print('filtered dataset length: ', len(dataset['train']))
dataset = dataset.remove_columns(
['prompt', 'answer', 'label', 'symbol', 'period', 'exceed_max_length']
)
current_time = datetime.now()
formatted_time = current_time.strftime('%Y%m%d%H%M')
training_args = TrainingArguments(
output_dir=f'finetuned_models/{args.run_name}_{formatted_time}', # 保存位置
logging_steps=args.log_interval,
num_train_epochs=args.num_epochs,
per_device_train_batch_size=args.batch_size,
per_device_eval_batch_size=args.batch_size,
gradient_accumulation_steps=args.gradient_accumulation_steps,
dataloader_num_workers=args.num_workers,
learning_rate=args.learning_rate,
weight_decay=args.weight_decay,
warmup_ratio=args.warmup_ratio,
lr_scheduler_type=args.scheduler,
save_steps=args.eval_steps,
eval_steps=args.eval_steps,
fp16=True,
deepspeed=args.ds_config,
evaluation_strategy=args.evaluation_strategy,
remove_unused_columns=False,
report_to='wandb',
run_name=args.run_name
)
model.gradient_checkpointing_enable()
model.enable_input_require_grads()
model.is_parallelizable = True
model.model_parallel = True
model.model.config.use_cache = False
# model = prepare_model_for_int8_training(model)
# setup peft
peft_config = LoraConfig(
task_type=TaskType.CAUSAL_LM,
inference_mode=False,
r=8,
lora_alpha=16,
lora_dropout=0.1,
target_modules=lora_module_dict[args.base_model],
bias='none',
)
model = get_peft_model(model, peft_config)
# Train
trainer = Trainer(
model=model,
args=training_args,
train_dataset=dataset['train'],
eval_dataset=dataset['test'],
tokenizer=tokenizer,
data_collator=DataCollatorForSeq2Seq(
tokenizer, padding=True,
return_tensors="pt"
),
callbacks=[
GenerationEvalCallback(
eval_dataset=eval_dataset,
ignore_until_epoch=round(0.3 * args.num_epochs)
)
]
)
if torch.__version__ >= "2" and sys.platform != "win32":
model = torch.compile(model)
torch.cuda.empty_cache()
trainer.train()
# save model
model.save_pretrained(training_args.output_dir)
if __name__ == "__main__":
parser = argparse.ArgumentParser()
parser.add_argument("--local_rank", default=0, type=int)
parser.add_argument("--run_name", default='local-test', type=str)
parser.add_argument("--dataset", required=True, type=str)
parser.add_argument("--test_dataset", type=str)
parser.add_argument("--base_model", required=True, type=str, choices=['chatglm2', 'llama2'])
parser.add_argument("--max_length", default=512, type=int)
parser.add_argument("--batch_size", default=4, type=int, help="The train batch size per device")
parser.add_argument("--learning_rate", default=1e-4, type=float, help="The learning rate")
parser.add_argument("--weight_decay", default=0.01, type=float, help="weight decay")
parser.add_argument("--num_epochs", default=8, type=float, help="The training epochs")
parser.add_argument("--num_workers", default=8, type=int, help="dataloader workers")
parser.add_argument("--log_interval", default=20, type=int)
parser.add_argument("--gradient_accumulation_steps", default=8, type=int)
parser.add_argument("--warmup_ratio", default=0.05, type=float)
parser.add_argument("--ds_config", default='./config_new.json', type=str)
parser.add_argument("--scheduler", default='linear', type=str)
parser.add_argument("--instruct_template", default='default')
parser.add_argument("--evaluation_strategy", default='steps', type=str)
parser.add_argument("--eval_steps", default=0.1, type=float)
parser.add_argument("--from_remote", default=False, type=bool)
args = parser.parse_args()
wandb.login()
main(args)Benchmarking Success
During our initial training with random news, we achieved a binary accuracy of 0.6809. It’s a solid start, but there’s room for improvement, and that’s where you come in. By joining our community and building upon our foundation, you help us all move closer to more accurate, reliable, and insightful predictions.
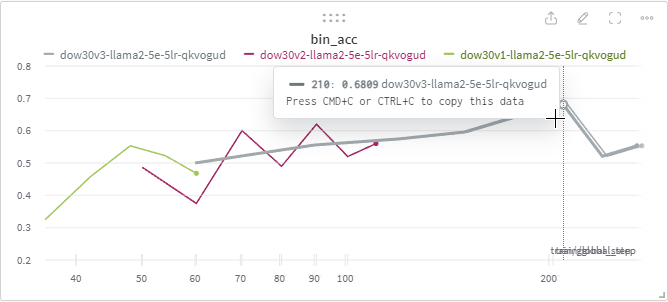
Join Us on This Journey
By now, you might be intrigued or even ready to roll up your sleeves and dive into training your FinGPT Forecaster. We invite you to join our open-source community, where we’re committed to empowering each other with the tools and knowledge to revolutionize the field of robo-advisory. Together, we’re not just predicting the future; we’re shaping it.
Disclaimer: Nothing herein is financial advice, and NOT a recommendation to trade real money. Please use common sense and always first consult a professional before trading or investing.
Subscribe to DDIntel Here.
Have a unique story to share? Submit to DDIntel here.
Join our creator ecosystem here.
DDIntel captures the more notable pieces from our main site and our popular DDI Medium publication. Check us out for more insightful work from our community.
DDI Official Telegram Channel: https://t.me/+tafUp6ecEys4YjQ1





