
Introducing Donut: The OCR-Free Document Understanding Transformer Revolutionising Visual Document Understanding
Research Paper Summary

In this blog, we will be doing a deep dive of the paper OCR-free Document Understanding Transformer.
Outline
Introduction: OCR Free Document Understanding Transformer (Donut)
Synthetic Document Generator: Generating Data for Pre-training
Pre-training of Donut Model
Results and Performance
Conclusion
Introduction: OCR Free Document Understanding Transformer (Donut)
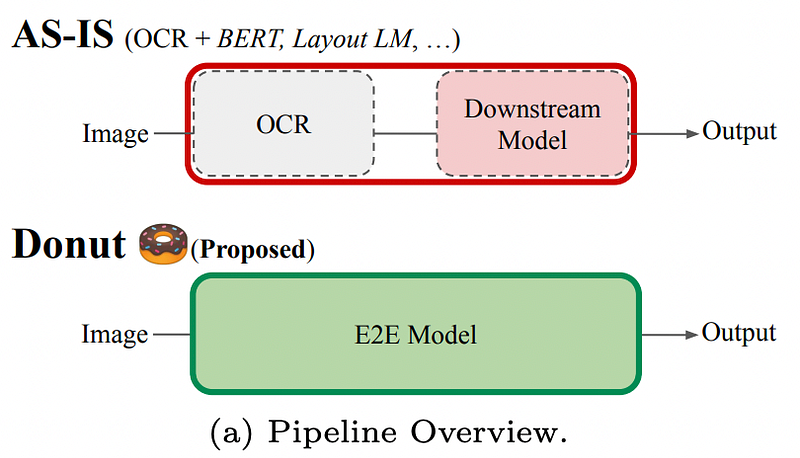
The task of understanding document images such as invoices has been a core but challenging problem. Current Visual Document Understanding (VDU) methods outsource the task of reading text to off-the-shelf OCR engines and focus on understanding the task with the OCR output. This can lead to high computational cost, lack of flexibility for different documents or languages, and propagated errors due to OCR not recognizing characters properly. To address these issues, a new model called OCR Free Document Understanding Transformer (Donut) was proposed. Donut is an end-to-end model which takes an input image and directly produces the output, bypassing the need for an OCR engine. This model achieved state-of-the-art performance on various document tasks in terms of both speed and accuracy. Donut utilizes a transformer encoder and decoder, with a pre-training objective that makes the entire system learn more about the document structure and the inherent property that every document comes with. A technique for generating synthetic data was also proposed to be used for pre-training the model. The model is trained using a combination of real and synthetic data and is capable of achieving state-of-the-art performance on various document parsing tasks.
Synthetic Document Generator: Generating Data for Pre-training
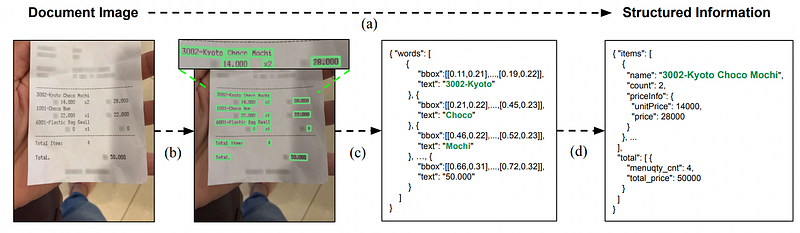
The use of Synthetic Document Generator (SDG) to generate data for pre-training is becoming increasingly popular in document understanding tasks. SDG is a technique for generating data that can be used to pre-train a model to help it understand a given document. The data generated by SDG is usually in the form of an XML-like structure, which contains information about the document, such as its background image, text segments, and their associated bounding boxes. SDG also uses images from ImageNet to fill in the background of the document, and text from Wikipedia to fill in text segments.
Using SDG to generate data for pre-training a model can be beneficial in a number of ways. First, it can reduce the computational cost and memory footprints associated with the traditional OCR-based document understanding pipeline. Second, it can increase the accuracy of the model by providing more meaningful sequences of input data. Finally, it can enable the model to be more flexible when dealing with different types of documents and languages.
Overall, SDG is a powerful tool for generating data for pre-training models. By using this technology, researchers and developers can create more accurate and efficient models for document understanding tasks.
Pre-training of the Donut Model
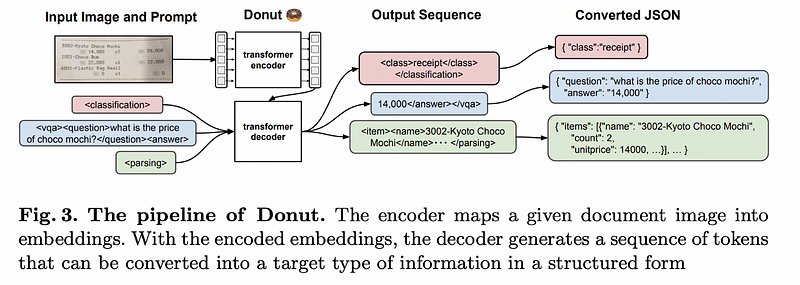
Pre-training of the Donut Model is an important step in the machine learning process, as it allows a model to learn the structure of a dataset, as well as the relationships between different elements of the data. The Donut Model is an end-to-end model which takes in an image, and outputs data based on the prompt given. To pre-train the model, the researchers used synthetic document generator to generate 0.5 million samples per language which was for Chinese, Japanese, Korean and English. Apart from this, they also used the IIT CDIP dataset which had 11 million scanned English document images. The synthetic document generator works by defining certain layouts for an invoice, and using data from sources such as ImageNet and Wikipedia to fill in the required blocks. Pre-training the Donut Model helps it to learn the document structure and the inherent properties of the document, and it is this pre-training step that helps the model achieve state-of-the-art performance on various video tasks.
Results and Performance
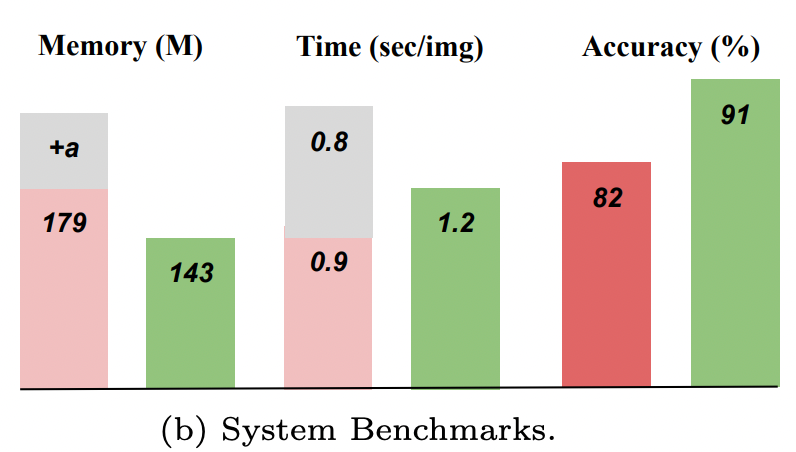
The results and performance of the proposed OCR free document understanding Transformer (Donut) model have been quite remarkable. On various document understanding tasks, the model achieved state-of-the-art accuracy, while also processing images faster with lesser memory. Furthermore, the use of synthetic data for pre-training the model and the end-to-end design of the pipeline helped in achieving such high accuracy. The model also showed promising results when tested on various languages such as Chinese, Japanese, Korean and English. All in all, the results and performance of the Donut model have been quite remarkable and have opened up opportunities for further development and research.
Please Note: The reference for colors mentioned in the below fig. can be found in the first image of this blog.
Conclusion
In conclusion, the OCR free document understanding Transformer (Donut) is a revolutionary way of parsing documents such as invoices. It eliminates the need for OCR engines and post-processing functions, and instead uses a pre-trained Transformer architecture to directly generate output from the image. The model was tested on various documents, and the results showed that it achieved state-of-the-art performance in terms of speed, accuracy and memory usage. Additionally, the authors proposed a technique for generating synthetic data, which was used to pre-train the model. All of this makes the Donut model a great option for document understanding applications.
Also, if you’d like to support me as a writer, consider signing up to become a Medium member. It’s just $5 a month and you get unlimited access to Medium.




