
Perceptron, Neural Networks & Deep Learning
An introduction to Neural Networks and their building blocks
Background
Despite working as a Data Scientist for two years, I have never used neural networks or any form of deep learning. This is primarily due to the type of problems I work on (forecasting and optimisation) where neural networks aren’t the most optimal choice.
Nevertheless, as a practitioner, I would feel like a slight fraud (in my opinion) if I didn’t have a working knowledge of neural networks as they are arguably the coolest part of data science and machine learning. Not to mention they are used everywhere: reinforcement learning, medical diagnoses, marketing—the list goes on.
Therefore, my next series of articles will break down the key building blocks and fundamentals of neural networks and how we can implement them in PyTorch.
But first, make sure to subscribe to my YouTube Channel!
Click on the link for video tutorials that teach you core data science concepts in a digestible manner!
What Are Neural Networks?
In a nutshell, I like to think of neural networks as a large mathematical expression or optimisation engine that is trying to predict something from a given set of features. In reality, it’s not trying to achieve anything different from a decision tree or even ordinary linear regression.
Its name derives from its structure as a network of multiple inter-connected computational units called neurons. This structure was inspired by the human brain and biological neural networks. The connection between each neuron is a number that is calculated from the multiple inputs going into said neuron. Each input has a corresponding weight, and the goal of training the neural network is to find the optimal weights that give us the most accurate predictions.
I appreciate the above all seems very arbitrary. But, hopefully, as we work through this series of articles, the above paragraph will make much more sense!
Perceptron: The Simplest Neural Network
Overview & Algorithm
Ostensibly, neural networks seem to be this ‘shiny new thing’ that is powering this current AI revolution. However, they are actually relatively old. They originate from something called the perceptron, which was invented by Frank Rosenblatt in the 50s inspired by the work from Warren McCulloch and Walter Pitts around a decade earlier.
Let’s take a look at how it works:
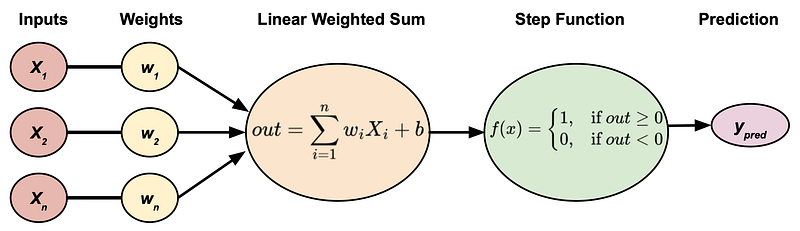
This diagram essentially explains the whole perceptron algorithm, which is used for binary classification problems. Let’s break it down step by step:
- Inputs: These are the features of our data.
- Weights: Some coefficients we multiply the inputs by. The goal of the algorithm is to find the most optimal weights.
- Linear Weighted Sum: Sum up the products of the inputs and weights and add a bias/offset term, b.
- Step Function: If the value of the linear weighted sum is greater than 0, then we predict a 1, otherwise a 0. This is known as an activation function in the field.
The weights are optimised through the following learning algorithm called the delta rule:
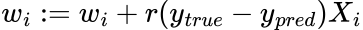
Where r is the learning rate. This is a simpler version of the more well-known algorithm back-propagation and is based on gradient descent.
You might notice that the perceptron is very similar to logistic regression. They key difference is that the latter uses the sigmoid activation function to transform the output between 0 and 1. Modern day neural networks can be thought of as a string of logistic regression models.
Limitations & Problems
Nowadays, the perceptron is rarely used due to its limitations and better-existing algorithms. The main limitation of the perceptron is that it is strictly a linear classifier, as the step function is linear. This means it will struggle for any data that is not linearly separable.
Another issue is that the perceptron can’t learn the XOR function/logic gate. However, this is solved by stacking perceptrons together, which we will get into in a second!
If you want to understand more about the benefits of non-linearity in a neural network, check out my previous post:
Multi-Layer Perceptron
Overview
The regular perceptron is also known as a single-layer neural network, where the single-layer refers to the network having one neuron layer that the data is passed through.
However, all modern-day neural networks consist of multiple neurons stacked together. After all, we can’t have a network with only one neuron! This is where the multi-layer perceptron comes in, where we stack and interconnect several perceptrons together.
Architecture
Below is an example architecture of a basic multi-layer perceptron:
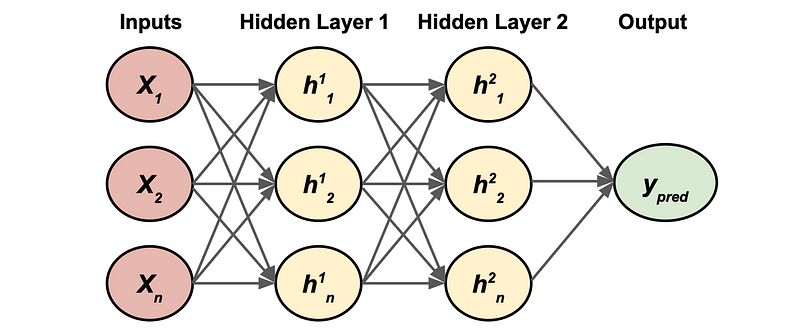
Let’s break down the diagram:
- Inputs: These are the n features of our data.
- Hidden Layer: This is where the multiple perceptrons are stored, each neuron is a perceptron that we discussed earlier. The superscript refers to the layer and the subscript to the neuron/perceptron in that layer.
- Edges/Arrows: These are the weights for the network from the corresponding inputs, whether it be the features or the hidden layer outputs. I have omitted them in the plot to not make is messy.
All that’s different here is that we have the output from a perceptron flowing into another perceptron, this is happening between the two hidden layers. Apart from that, this is the same as the perceptron algorithm but with more parameters.
As an example, the calculation of h¹_1 would be:
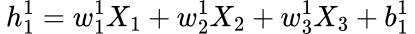
Where w are the weights and b is the bias for the corresponding neuron in that layer, in this case, it is neuron 1 in layer 1. This calculation is repeated for every other neuron in the first hidden layer. Then, those outputs are fed as inputs to the second hidden layer. It’s really that simple!
This compute is often vectorised and carried out by the dot product. See here for an example.
Fun fact: The multi-layer perceptron is a common misnomer for the modern neural network because the perceptron uses the step activation function that is linear, but modern-day networks use non-linear.
Limitations & Problems
The problem with the multi-layer perceptron is that it will still fit a linear function to classify the data. There is no ‘step’ in the algorithmic process where linearity is broken to allow the network to learn non-linear functions.
What do we do?
Activation Functions!
Certain activation functions make the output non-linear, thus allowing us to satisfy something called the universal approximation theorem. This states that a neural network can fit to any function to a reasonable degree if it contains non-linear activation functions.
In my next article, we will cover this topic and also the activation functions that allow this process!
A multi-layer perceptron or network with linear activation functions can be shown to be a form of linear regression!
Summary & Further Thoughts
In this post, we have run down the key concept and building block behind a neural network, the perceptron. This is a simple algorithm that takes in an input, multiplies it by some weights, sums it all up, and then outputs a zero or one depending it is greater or equal to zero. This algorithm, which can be referred to as a neuron, can be stacked together to form layers. This structure is what is referred to as a multi-layer perceptron, colloquially known as a neural network.
Next post in the series:
References & Further Reading
- Great article on neural nets
- Another intro to neural nets
- Andrej Karpathy lecture on neural nets
- Book on perceptrons
- Book on neural nets
Another Thing!
I have a free newsletter, Dishing the Data, where I share weekly tips for becoming a better Data Scientist. There is no “fluff” or “clickbait,” just pure actionable insights from a practicing Data Scientist.





