
Interview Guide to Boosting Algorithms: Part-2

Table of content to guide you across this article:
- XGBoost: A Scalable Tree Boosting System
- More about XGBoost
- Miscellaneous
XGBoost: A Scalable Tree Boosting System
Machine learning and data-driven approaches are becoming very important in many areas.
- Smart spam classifiers protect our email by learning from massive amounts of spam data and user feedback
- Advertising systems learn to match the right ads with the right context
- Fraud detection systems protect banks from malicious attackers
- Anomaly event detection systems help experimental physicists to find events that lead to new physics.

There are two important factors that drive these successful applications:
Usage of effective (statistical) models that capture the complex data dependencies and scalable learning systems that learn the model of interest from large datasets.
Among the machine learning methods used in practice, gradient tree boosting is one technique that shines in many applications.
Note: Gradient tree boosting is also known as gradient boosting machine (GBM) or gradient boosted regression tree (GBRT).
More about XGBoost:
The most important factor behind the success of XGBoost is its scalability in all scenarios.
The system runs more than ten times faster than existing popular solutions on a single machine and scales to billions of examples in distributed or memory-limited settings.
The scalability of XGBoost is due to several important systems and algorithmic optimizations.

These innovations include:
- A novel tree learning algorithm is for handling sparse data
- A theoretically justified weighted quantile sketch procedure enables handling instance weights in approximate tree learning.
Parallel and distributed computing makes learning faster which enables quicker model exploration. More importantly, XGBoost exploits out-of-core computation and enables data scientists to process hundreds of millions of examples on a desktop.
Sparse BLAS CSC Matrix Storage Format:
Sparse BLAS CSC Matrix Storage Format
Miscellaneous:
Where do boosting algorithms fit in the world of AI/ML?
Neural Networks, logistic regression, SVMs, all of these models answer of how do we learn to solve a particular problem (take specific example of Iris Dataset, classification problem).

But a question that should be asked before this: Is this problem solvable?
To answer this: We use the concept of PAC Learning.
PAC Learning quantitatively defines “is the problem solvable/learnable?”
PAC: Probably Approximately Correct Model
Iris Dataset: Use logistic regression → Reasonably low error
It means that for this particular problem, logistic regression is a strong learner. {If it fits with our definition of threshold, 99% performance (0.01 < 𝟄 with probability > 1-𝛅)}
For more complex problems, a strong learner would need to be more complex {Also we need a lot more learning parameters and a lot more samples for training & we may also have a very high hardware requirement}

If we don’t have above, then:
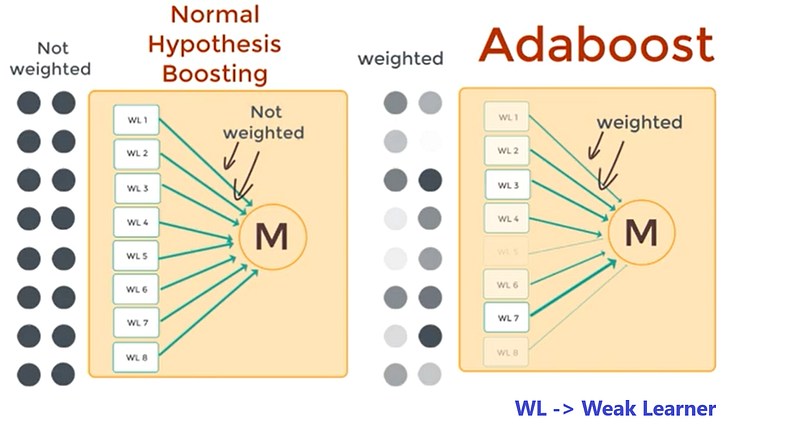
- Weak Learners come to rescue.
- Weak learners are algorithms which perform just slightly greater than random guessing.
- If a problem can be solved by a strong learner then a weak learner should be able to do it too.
- They can do it by introducing a technique called Boosting Mechanism.
- Construct multiple models and then all make predictions and then we go by majority vote.
What’s next for you?
If you enjoyed this article, it would really help if you hit recommend below! Follow me on Twitter, LinkedIn, and Medium
Read my previous post: Interview Guide to Boosting Algorithms: Part-1
Gain Access to Expert View — Subscribe to DDI Intel