
How to Find the Best Stocks in the Stock Market Using AI
Intelligent Stock Screening using LLMs
Do me a favor real quick. Open a new tab, and type the following into Google, Perplexity, ChatGPT, or whatever service you use to find your information.
Find the top 5 semiconductor or artificial intelligence stocks that had the largest increase in income in the past 3 years. Sort from greatest to least
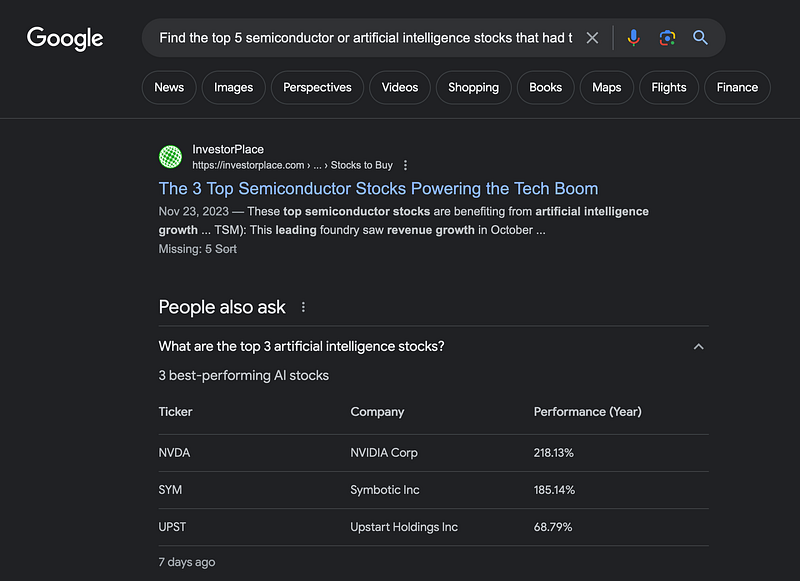
When you search this on the web, you will find information. But they will be popular results, mostly based on what’s trending or some other guy’s “expert opinion”. When investing in stocks, it’s important to have cold-hard facts. Financial platforms don’t give you all of the information you need. So how do you get the real facts?
Today, I’m outlining a design for a new feature in the NexusTrade Platform – intelligent stock screening using Large Language Models. This new feature will allow you to do several things. For one, you can query for stocks belonging in certain industries. Secondly, you can query for stocks that have a certain market cap, revenue, income, EDITBA, and other important financial metrics. With this functionality, you can find the perfect stock that aligns with your investment thesis and financial goals. No more opinionated articles written by some guy with a portfolio full of the stock they are shilling. Just cold, hard facts.
Brief Recap on NexusTrade
NexusTrade is my AI-Powered investing research platform. It’s software that streamlines the process of developing, testing, and deploying automated and semi-automated trading strategies. It’s flagship feature is its AI-Powered Chat that translates plain English into a configuration the platform understands.
In addition to being able to create and test trading strategies, Aurora can also perform financial research. For example, if I tell Aurora to analyze a company’s earnings, here’s what she’ll say.
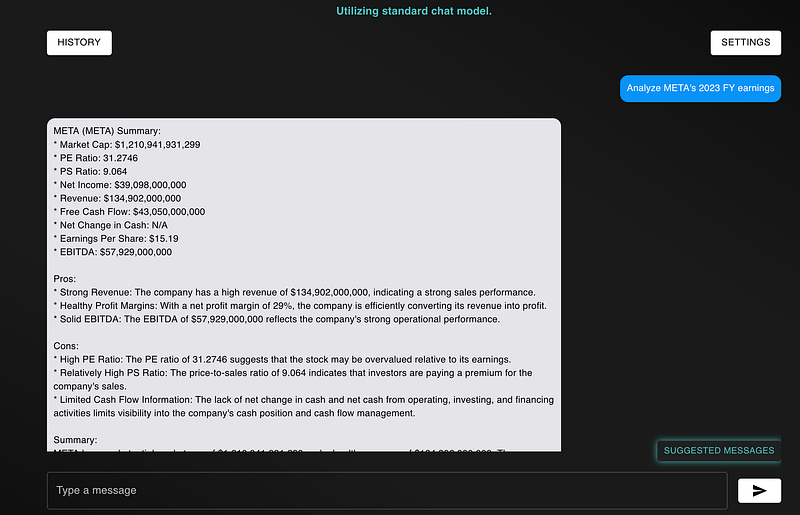
This type of financial analysis is extremely useful. Yet, it also requires you to have prior knowledge on what stocks that you want to search for. If you’re new to investing, trying to find novel stocks, or want to find stocks in niche industries, then this feature isn’t helpful. How can you one better find stocks that meets their investment goals?
Intelligent Stock Screening: Implementation
Let’s return to the first thing I asked you when you opened this article:
Find the top 5 semiconductor or artificial intelligence stocks that had the largest increase in income in the past 3 years. Sort from greatest to least
We can clearly see the value of such a feature. If I believe that AI is the future, and I also believe that profitability, and increasing profitability is important for my investment thesis, then being able to search for this list of stocks in order would be invaluable. Moreover, this type of query could also be extended. For example, I could add something like “and has a PE ratio of less than 30”. As long as my data is structured appropriately, I can intelligently find any stock that fit my goals.
To implement this, we’ll need to
- Populate our database with the data we’ll want to search for
- Generate data using yahoo finance and a Large Language Model
- Understand MongoDB’s aggregation framework
- Perform few-shot learning using LLM function calls.
Let’s go through each of these steps in detail.
Populate our database
The most important step in our intelligent search algorithm is populating our MongoDB Database. This step is critical, and involves designing an elegant, flexible schema that stores all of our relevant stock information.
This step isn’t just important for our intelligent stock screening feature. This schema can also be used for other essential features of the app. For example, it can lay the groundwork for using fundamental indicators within our algorithmic trading strategies. For this reason, it is imperative that we design this schema with great care, and avoid the common pitfalls of algorithmic trading such as look-ahead bias.
An example of a schema can be as follows:
const stockFundamentalDataSchema = new Schema({
date: Date,
stockName: String,
income: Number,
revenue: Number,
ebitda: Number,
// other fundamental indicators
});
const stockIndustriesSchema = new Schema({
is_AI: Boolean,
is_semiconductor: Boolean,
is_biotechnology: Boolean,
// other industries
});Unfortunately, I couldn’t find a good database that has a list of industries a particular company belongs to. So, in order to gather this part of the data, we’ll need to use a Large Language Model.
Generate our data
Our goal is to generate an object with containing a list of industries that our stock is in. Then, we’ll save this (and related data) to a database. For example, if our input is “CRISPR”, we want to generate the following JSON.
Industries: {
biotechnology: true,
healthcare: true,
pharmaceuticals: true,
researchAndDevelopment: true,
biomedicalEngineering: true
}Large Language Models (LLMs) are generally capable of producing satisfactory summaries for many stocks. However, for some specialized or recently introduced stocks, these models might not have information due to their training data being several months outdated. That is why external APIs, like Yahoo Finance, are important when generating our data.
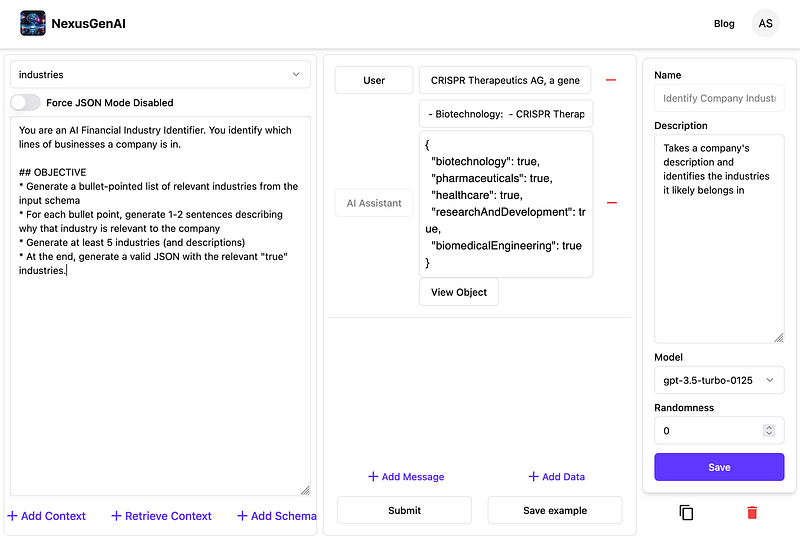
NexusGenAI allows us to create this AI workflow in an easy-to-use UI. It includes the instructions to give the model, the type of model we want to use, and the schema that the model must conform to in its response. As you can see, the model generates a JSON with a list of industries that CRISPR belongs to. These will be saved in our database so we can query it later.
However, just querying one company at a time would take eons. The greatest part about NexusGenAI is, after we’ve configured our workflow in the UI, we can use it as an API directly within our code!
async function main() {
// check the open-source NextTrade for this function implementation
const stockList = await StockData.getListOfAllStocks();
for (const stock of stockList) {
try {
console.log("Fetching data for ", stock.name);
// using the yahoo-finance2 library
const quote = await yahooFinance.quoteSummary(stock.name, {
modules: ["summaryProfile"],
});
const summary = quote["summaryProfile"]["longBusinessSummary"];
const prompt = "Identify Company Industries";
const response: ChatMessage []= await
nexusgenaiServiceClient.chatWithPrompt(prompt, summary);
const description = response[0].content;
const data = response[0].data?.industries;
if (!data) {
throw new Error("No industries found for company");
}
// Save the description and data into the database
} catch (e) {
console.error("Error fetching data for ", stock.name, e);
}
}
}This allows us to keep our prompts out of our source code and in one centralized, manageable location. It also enables us to add new features to NexusTrade in minutes, not months. The limited-availability waitlist is now open!
MongoDB Aggregation Framework
The next important step to executing our intelligent stock screening algorithm is fully understanding the MongoDB Aggregation Framework. This framework will allow us to execute complex queries of our database. The common operations of this framework include $lookup, $unwind, $match, $sort, $group, $project, and $limit. Combined, these operations allow us to execute our request from the beginning of the article. After showing an example of the aggregation pipeline in code, I’ll briefly explain each of the fields.
Query: Find the top 5 semiconductor or artificial intelligence stocks that had the largest increase in income in the past 3 years. Sort from greatest to least
const pipeline = [
{
$lookup: {
from: "stockIndustries", // Assuming this is the collection name
localField: "stockName",
foreignField: "stockName",
as: "industryData"
}
},
{ $unwind: "$industryData" },
{
$match: {
$or: [{"industryData.is_AI": true}, {"industryData.is_semiconductor": true}],
date: {$gte: threeYearsAgo}
}
},
{$sort: {stockName: 1, date: 1}},
{
$group: {
_id: "$stockName",
firstIncome: {$first: "$income"},
lastIncome: {$last: "$income"},
}
},
{
$project: { incomeIncrease: {$subtract: ["$lastIncome", "$firstIncome"]}}
},
{ $sort: {incomeIncrease: -1}},
{ $limit: 5 }
];The components of the pipeline are as follows:
$lookup: This stage joins documents from separate collections using a specified field, functioning similarly to a SQL JOIN, facilitating the aggregation of related data.$unwind: This stage splits documents containing array fields into multiple documents for each array item, enabling individual item processing.$match: This stage filters documents based on specific criteria, akin to the SQL WHERE clause, to narrow down the selection.$sort: This stage orders the documents based on specified field(s), similar to the SQL ORDER BY clause, organizing the data in ascending or descending order.$group: This stage aggregates documents by a specified identifier, similar to the SQL GROUP BY clause, allowing for the application of aggregate functions to each group.$project: This stage reshapes each document, similar to selecting fields in a SQL query, allowing for the addition, removal, or modification of fields.$limit: This stage restricts the number of documents passed to the next stage, akin to the SQL LIMIT clause, useful for controlling the size of the result set.
Combined, these stages create a powerful framework that can perform complex data aggregation tasks. If used properly, it can be used as a building block for our intelligent stock screener functionality.
Function Calling and Few-Shot Learning
Now that we understand the aggregation framework, we can finally use NexusGenAI to perform function-calling. This works similarly as to our other functions in NexusTrade, where we send a request to the model, generate a JSON object, and then use that JSON object to execute some functionality.
This time, the function-calling will be translating plain English text into this MongoDB Aggregation Framework. With NexusGenAI, we can supply many examples of queries, and then, similar requests will be processed accordingly. For example:

From here, we’ll integrate this into the NexusTrade application, and enable our users to execute complex functionality.
This allows us to execute complex queries using natural language. Combining everything, we can search for virtually any stock that meets the criteria we want. Whether its AI, biotechnology, or entertainment, we can find the businesses we want to invest in that aligns with our investment goals.
Conclusion
Most companies have yet to fully realize the power of Large Language Models. Most use-cases are “nice-to-have” features that they show investors to prove they’re integrating with AI.
NexusTrade takes a different, AI-First approach. My goal is focusing on how to deliver value to my users and how AI can help me accomplish. This new feature, while not yet implemented, will be extremely useful. It’ll allow users to search for stocks in way that they never before could. This aligns with my mission to creating and popularizing the new industry of retail algorithmic trading.
Thank you for reading! If you enjoyed this article, please give me some claps and share this article with a friend (or social media)! I have several newsletters you could follow. Aurora’s Insights is the perfect blog if you’re interested in artificial intelligence, machine learning, finance, investing, trading, and the intersection between these disciplines. You can also create a free account on NexusTrade to get access to a next-generation algorithmic trading platform.
NexusGenAI is the platform that hosts NexusTrade’s AI-Powered Chat. It is also open for users on the waitlist!
🤝 Connect with me on LinkedIn
🐦 Follow me on Twitter
👨💻 Explore my projects on GitHub
📸 Catch me on Instagram
🎵 Dive into my TikTok
PS, did you share with a friend? 🤨
Visit us at DataDrivenInvestor.com
Subscribe to DDIntel here.
Have a unique story to share? Submit to DDIntel here.
Join our creator ecosystem here.
DDIntel captures the more notable pieces from our main site and our popular DDI Medium publication. Check us out for more insightful work from our community.
DDI Official Telegram Channel: https://t.me/+tafUp6ecEys4YjQ1




