
B+Tree Index Seek vs Index Scan

In this article I explore the performance impact of database index seek vs index scan. While these are mostly SQL Server terminologies, they are fundamental to how B+Tree are searched in DBMS platforms.
To Seek or To Scan
An Index Seek traverses the B+Tree from the root node to look up a single value in a leaf page. This causes at least 2 I/Os depending on the depth of the B+Tree. An Index Scan however works by scanning the B+Tree leaf pages which are already ordered and linked.
Index scans are better suited for range queries or large values that are close to each other while seeks are great for more selective queries that return very few results.
To better illustrate this, the students table with ID integer fields among others. We are particularly interested in the B+Tree index on ID field.
Assuming a page size that can carry up to 2000 elements (key value) the structure might look like this.
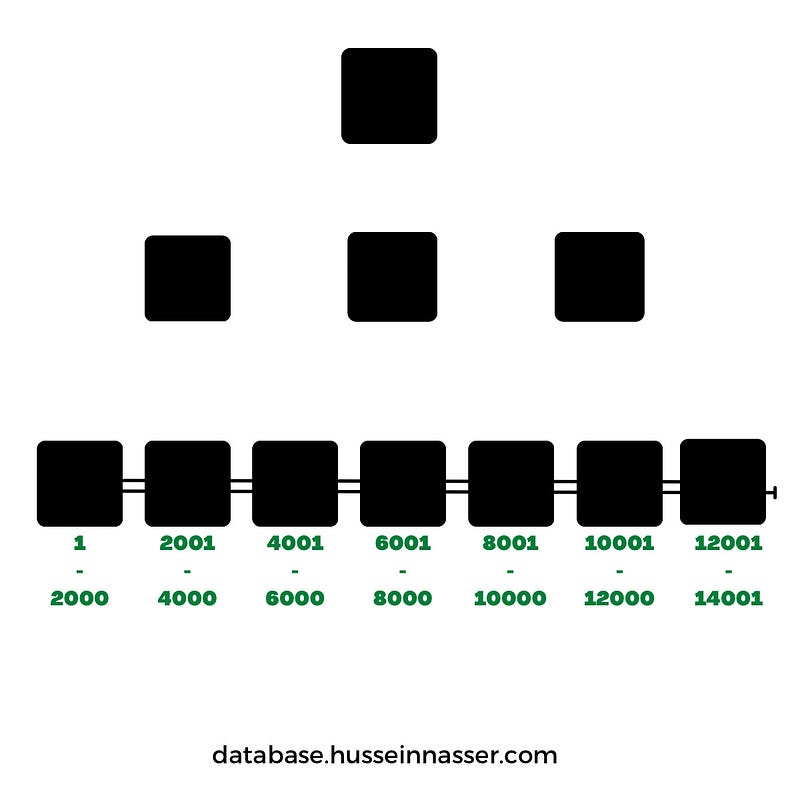
Lets take some examples.
Index Seek Example
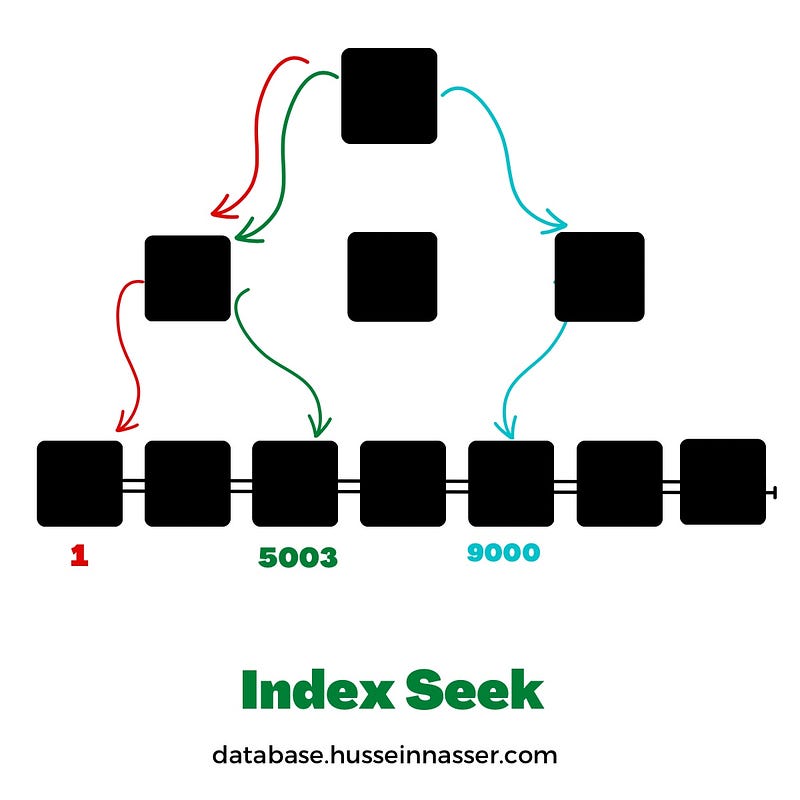
Consider the following query against the students table
SELECT *
FROM STUDENTS
WHERE ID = 1 OR ID = 5003 or ID = 9000The query needs to do 3 index seeks for each of the values 1, 5003 and 9000 on the index on the ID field. Each of the value is on a different page which means there is no cache hit.
Of course once we have the key value element pair, the value would be the row id which point us to the table to get all fields. This differs between database systems depending whether the ID is primary index and if it is clustered or not.
Note: If ID = 2 was in the filter, that would be satisfied by the same page that 1 lives on which we already fetched. Cache hits are key.
Index Scan Example
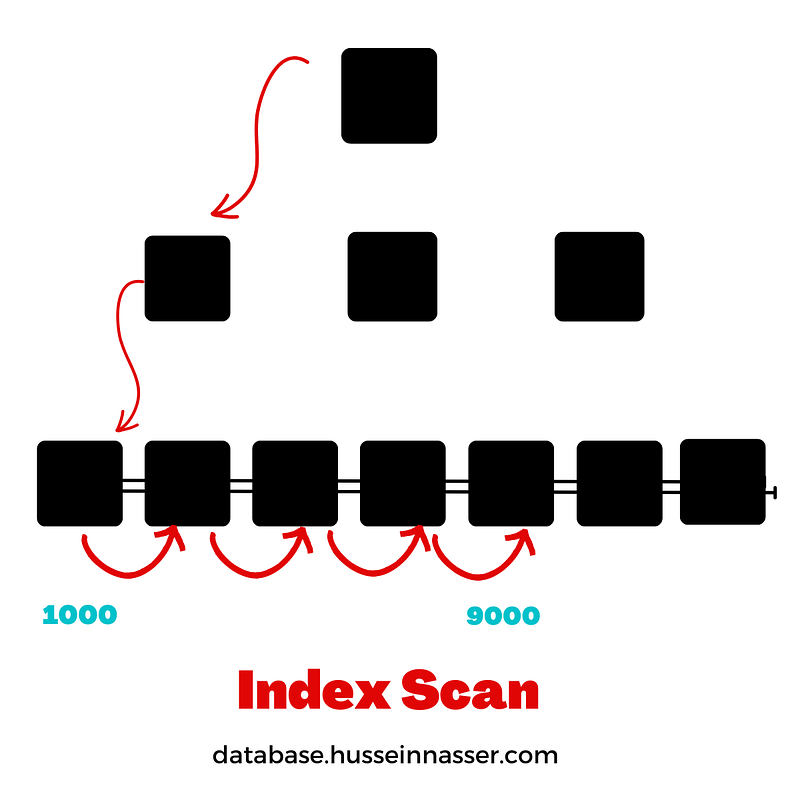
On the same table let us execute the following query.
SELECT *
FROM STUDENTS
WHERE ID BETWEEN 1000 and 9000Depending on the implementation, the query will probably do a seek on the lowest element in the range (1000) to find the lowest page and then walk the linked leaf pages until it reaches the page which has the entry 9000 that is when the index scan stops.
This is possible because entries in the leaf pages are ordered and the linked to each other.
Each leaf page points to the next, a property of B+Tree.
We do we need a seek and a scan?
Using a seek on every single value between 1000 and 9000 results in more I/O and slows down the query. While in the first example doing a scan from the page which has the value 1 to the page that has 9000 looking for 1, 5003 and 90000 is a waste of IO. The database ends up fetching pages in between that it doesn’t need.
Where it breaks down
There are cases where a scan or a seek is obvious, the examples I provided above are like that. But not all cases are as simple.
There are cases where the planner might choose a different plan based on the result of an inner query result.
Take this query where we want full student row who scored higher than 90. The grades are in separate tables STUDENTS_GRADES.
SELECT *
FROM STUDENTS
WHERE ID IN
(SELECT ID
FROM STUDENTS_GRADES
WHERE GRADE > 90
) The inner query might might return a single value or it may return thousands IDs all over the place. The planner might opt in for a scan or a seek depending on the output.
The larger the inner query result set the more ineffective the use of the index becomes. The fragmented IDs will be distributed among many pages which causes excessive I/Os. In some cases, the planner might skip the index together for a full table scan to avoid unnecessary I/Os.
Frankly I don’t like queries where results are unpredictable it just annoying. I would try to eliminate unpredictability even at a cost of schema changes.
Summary
How do you know which is better? A scan or a seek? The planner tries its best but at the end of the day it may miss and pick the wrong plan. So it is up to us to write our queries in a predictable way if possible. I know that is not always the case but knowing what is happening behind the scenes is the first step.
For those interested to learn more about fundamentals of database engineering like this one grab a copy of my udemy course and discount coupon here https://database.husseinnasser.com




