In-Memory vs. Distributed Caching: A Comparative Look with Caffeine
In the fast-paced world of software development, caching is a cornerstone technique for optimizing application performance. This comprehensive guide explores the differences between in-memory and distributed caching, spotlighting Caffeine, a premier in-memory caching library for Java applications. We zero in on Caffeine, a potent in-memory caching library for Java, to illustrate key concepts and implementation nuances, particularly in the context of dynamically caching business configurations.
In-Memory vs. Distributed Caching: A Comparative Look
- In-Memory Caching: Directly accessible and localized, it’s ideal for rapid data retrieval scenarios. While simple to deploy, its scalability is bounded by the server’s memory capacity, posing limitations for growing applications.
- Distributed Caching: This model extends caching capabilities across a network, enhancing data availability and fault tolerance. Despite its scalability benefits, it introduces additional complexity in terms of cache coherence and network latency.
- Unveiling In-Memory Caching
Essence of In-Memory Caching
In-memory caching is the practice of storing data within the primary memory (RAM) of a server or application environment. This method significantly reduces access times, providing swift data retrieval compared to disk-based or networked sources, thereby boosting application speed and responsiveness.
Contrasting In-Memory and Distributed Caching
- In-Memory Caching: Primarily local to the application’s process, it excels in scenarios requiring rapid data access with minimal latency. It’s straightforward in deployment but is constrained by the memory capacity of the hosting server and lacks inherent scalability across multiple nodes or services.
- Distributed Caching: Spreads data across several servers or instances in a network, ensuring availability and resilience in distributed systems. While it addresses scalability and data consistency challenges present in in-memory caching, it introduces complexity in cache management and potential latency due to network overhead.
Caching Strategies
Depending on how often you update your database and whether consistency is a bigger concern than speed, you can choose from various cache strategies: cache aside, read-through, and write-through.
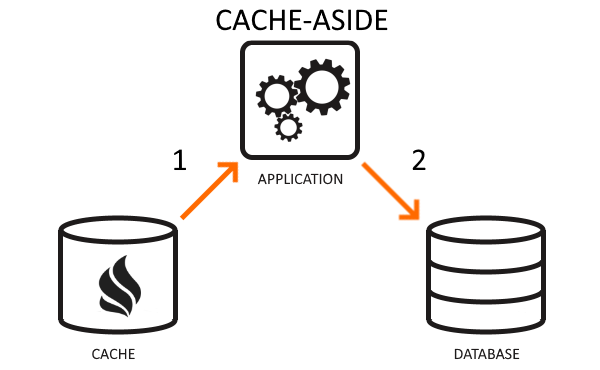
Cache-aside is the standard, simple caching strategy. The application lazy-loads database data on-demand to boost data fetching performance. In this strategy, the application first requests the data from the cache. If data exists in the cache (when a “cache hit” happens), the app retrieves information from the cache. If data is not in the cache (a “cache miss”), the app reads data from the data store and inserts it into or updates it to the cache for later use.
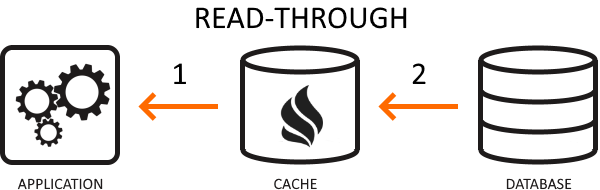
Read-through is a form of lazy-load caching similar to the cache-aside strategy. However, unlike cache-aside, your app is unaware of the data store. So, it queries the database by the caching mechanism instead. By delegating database reads to the cache component, your application code becomes cleaner — but at the expense of configuring extra caching components for database credentials.
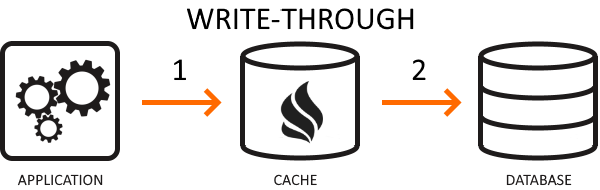
Write-through is a caching strategy where your application delegates database operations to the cache (similarly to the read-through cache, but for writes). Your app updates the cache, which then synchronously writes the new data to the database. This process slows the writing operation but ensures cache consistency and reliability. Developers use this strategy when consistency is a significant concern, and the application doesn’t frequently write data to the cache.
What is Caffeine cache? Caffeine cache is an advanced, high-performance Java caching library, building on insights from Google Guava’s cache and ConcurrentLinkedHashMap to offer an optimized in-memory caching solution. It supports a flexible API for configuring cache behavior, including size limits, expiration, and refresh policies. An example use case is efficiently caching expensive computations, such as graph data:
LoadingCache<Key, Graph> graphs = Caffeine.newBuilder()
.maximumSize(10_000)
.expireAfterWrite(Duration.ofMinutes(5))
.refreshAfterWrite(Duration.ofMinutes(1))
.build(key -> createExpensiveGraph(key));Caffeine excels in scenarios requiring rapid access to large datasets with minimal latency, making it ideal for applications where performance and scalability are paramount. For further details, explore the user’s guide and the API documentation on the Caffeine GitHub page.
The Role of Caffeine in In-Memory Caching
Caffeine stands at the forefront of in-memory caching solutions for Java applications, offering a high-performance, flexible caching mechanism. It’s particularly well-suited for applications requiring efficient, scalable caching of frequently accessed data, like configuration settings in multi-tenant systems.
Unveiling the Power of In-Memory Caching
Core Principles of In-Memory Caching
At its heart, in-memory caching stores temporary data in the server’s RAM, significantly cutting down on data access times. This immediate access to data catapults application performance, making in-memory caching a cornerstone for developing responsive applications.
Caffeine: Elevating Java Caching to New Heights
Caffeine has emerged as a formidable choice for developers seeking efficient and scalable in-memory caching. Its design is informed by lessons learned from Google’s Guava cache, addressing its predecessors’ limitations with a suite of advanced features:
- Automatic Loading: Simplifies cache population, ensuring fresh data is always available.
- Size-based Eviction: Keeps the cache size in check, preventing memory overflow.
- Time-based Expiration: Removes stale entries, maintaining cache relevance.
For an in-depth exploration of Caffeine, its GitHub repository (Caffeine GitHub) is an invaluable resource, offering exhaustive documentation and user guides.
Our Java library stands at the forefront of dynamic configuration management, designed to fetch and cache configurations at runtime efficiently. Utilizing a lazy-loading approach, the cache remains initially empty and is populated on-demand. This methodology is particularly advantageous for real-time data processing scenarios, where the configuration context is not predetermined. Additionally, the library is architected to support multi-tenancy, ensuring strict data separation across different tenants within the in-memory cache.
Choosing Caffeine Cache
After thorough evaluation of various caching solutions, Caffeine cache emerged as the selected framework for its superior performance and flexibility. This choice aligns with our objectives to provide a robust caching mechanism for our Online Embedded Fetcher, capable of handling complex, multi-tenant environments.
Key Implementation Details:
- Unified Cache Instance: A singular cache instance will serve all tenants, streamlining the management of cached data.
- Fallback and Redis Integration: Current limitations in tenant listing and configuration data indexing necessitate a reconsideration of fallback strategies. Discussions are underway to integrate Redis, enhancing our system with tenant-discovery capabilities. This advancement promises a more resilient architecture for data retrieval and fallback processes.
- Resilience and Data Availability: In scenarios where the configuration service becomes temporarily inaccessible, cached data will persist until connectivity is restored. This ensures uninterrupted access to critical configuration data. A monitoring system is in place to detect when the configuration service is available again, enabling timely data refreshes.
- Concurrency Management: To address challenges with concurrent data requests, we are exploring the Actor Model (Akka) for more efficient handling of simultaneous operations, ensuring that data consistency and application performance are maintained.
- Data Integrity and Monitoring: Fetching data from the cache will return cloned objects rather than direct references, preventing inadvertent modifications. Moreover, comprehensive monitoring of the caching mechanism will allow for in-depth analysis of cache performance, including hit rates, memory allocation, and potential bottlenecks.
- Future Enhancements: Considerations are being made to introduce additional layers of cache consistency, potentially leveraging cloud storage solutions like S3 for state persistence.
These strategic implementations underscore our commitment to delivering a high-performance, scalable, and resilient configuration caching solution. By harnessing the power of Caffeine cache and anticipating future integration with technologies like Redis, we are poised to offer an enhanced data management ecosystem for our clients.
Strategic Caching with Caffeine: A Practical Guide
Implementing Caffeine within a caching service demonstrates its versatility. The async capabilities provided by Caffeine are particularly beneficial for non-blocking operations Here is an example from our interface:
public interface ConfigurationCacheManager {
String getConfigurationsCacheEntryKey(String tenantId, String configuration, UUID instanceId);
String getInstancesMetadataCacheEntryKey(String tenantId, String configuration);
String getInstanceNameToIdCacheEntryKey(String tenantId, String configuration, String instanceName);
CompletableFuture<ConfigurationCacheValue> getConfigurationsCacheEntryValue(String entryKey, UUID logCorrelationId);
}This interface showcases how Caffeine can be utilized to enhance the performance and scalability of Java services, making it a staple in the toolkit of modern Java developers.
DynamoDB and Read-Through Caching: A Synergistic Pair
Integrating Caffeine’s read-through caching with DynamoDB leverages the strengths of both technologies, marrying Caffeine’s performance with DynamoDB’s scalability. This combination is particularly effective for read-intensive applications, optimizing data retrieval while managing costs.
Conclusion
The strategic application of Caffeine for in-memory caching, contrasted with distributed caching principles, offers a pathway to significantly improved application performance. By understanding and applying the right caching strategies, developers can ensure their applications are fast, responsive, and scalable.
Further Reading and References
- Caffeine GitHub Repository: https://github.com/ben-manes/caffeine
- Amazon DynamoDB: https://aws.amazon.com/dynamodb/
- Effective Java Caching: ‘Effective Java’ by Joshua Bloch — Offers insights into Java programming best practices, including caching strategies.
- Distributed Systems Principles and Paradigms: By Andrew S. Tanenbaum and Maarten Van Steen — A deeper look into the concepts behind distributed computing, including caching





