

In my first article, I spoke about Argo CD. This time it’s going to be Argo Workflow which is again from Argo project, Spark on Kubernetes and how do we make both work together.
Argo Workflow
Argo Workflow is a container native workflow engine where we can orchestrate jobs having sequence of tasks (each step in a workflow as a container). Using workflow definition we can capture the dependencies between the task using a DAG. An alternative to Airflow? Well.. maybe! If you’re looking at something native to kubernetes, I’m sure Argo Workflow will not disappoint you.
Deploying Argo Workflow to K8s (Please do create a namespace for argo workflow):
1. Install helm:
curl -fsSL -o get_helm.sh https://raw.githubusercontent.com/helm/helm/master/scripts/get-helm-3chmod 700 get_helm.sh./get_helm.sh
2. Add argo repo to helm and install
helm repo add argo https://argoproj.github.io/argo-helmhelm repo updatehelm install argo-wf argo/argo -n argo-wf -f values.yaml
In values.yaml, you can enable ingress (if ingress controller is available in your cluster)
ingress: enabled: true annotations: kubernetes.io/ingress.class: nginx kubernetes.io/tls-acme: “true” hosts: - argo.example.comYou will have argo workflow up and running in no time!
The workflow automation in Argo is driven by YAML templates. Argo has provided rich documentation with examples for the same. We can even submit the workflows via REST APIs if you’re looking at automation. I’m not going to deep dive much here as the documentation is detailed and well explained. Let’s move on to the next topic.
Spark on Kubernetes
Starting from Spark 2.3, you can use Kubernetes to run and manage Spark resources. Spark can run on clusters managed by Kubernetes. This feature makes use of native Kubernetes scheduler that has been added to Spark. We can run on demand spark driver and executor pods which means no dedicated spark clusters.. cool right?
There are two ways to run Spark on Kubernetes: by using Spark-submit and Spark operator.
Spark-submit: By using spark-submit CLI, you can submit Spark jobs with various configuration options supported by Kubernetes.
spark-submit delegates the job submission to the Spark on Kubernetes backend which prepares the submission of the driver via a pod in the cluster and finally creates the related Kubernetes resources by communicating to the Kubernetes API server.
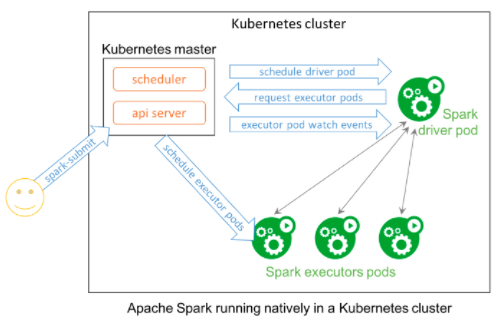
Spark-submit is the easiest way to run Spark on Kubernetes. If you review the code snippet, you’ll notice two minor changes. One is to change the Kubernetes cluster endpoint. Second, is the container image that hosts your Spark application.
./bin/spark-submit \ — master k8s://https://<KUBERNETES_CLUSTER_ENDPOINT> \ — deploy-mode cluster \ — name spark-pi \ — class org.apache.spark.examples.SparkPi \ — conf spark.executor.instances=3 \ — conf spark.kubernetes.container.image=aws/spark:2.4.5-SNAPSHOT \ — conf spark.kubernetes.driver.pod.name=sparkpi-test-driver \ — conf spark.kubernetes.authenticate.driver.serviceAccountName=spark local:///opt/spark/examples/jars/spark-examples_2.11–2.4.5-SNAPSHOT.jarPlease refer this link for all the available parameters/properties.
Spark operator: Spark operator (What are operators?) provides a native Kubernetes experience for Spark workloads. In addition, you can use kubectl and sparkctl to submit Spark jobs. Examples for these can be found here.
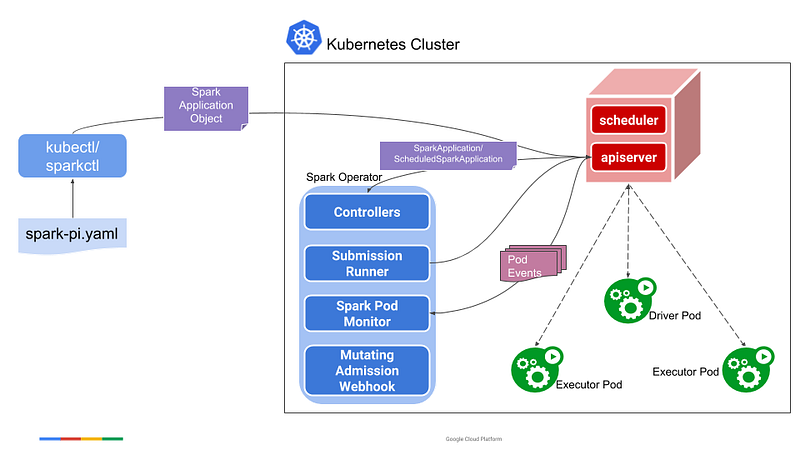
Spark operator is still in phase 4 capability level
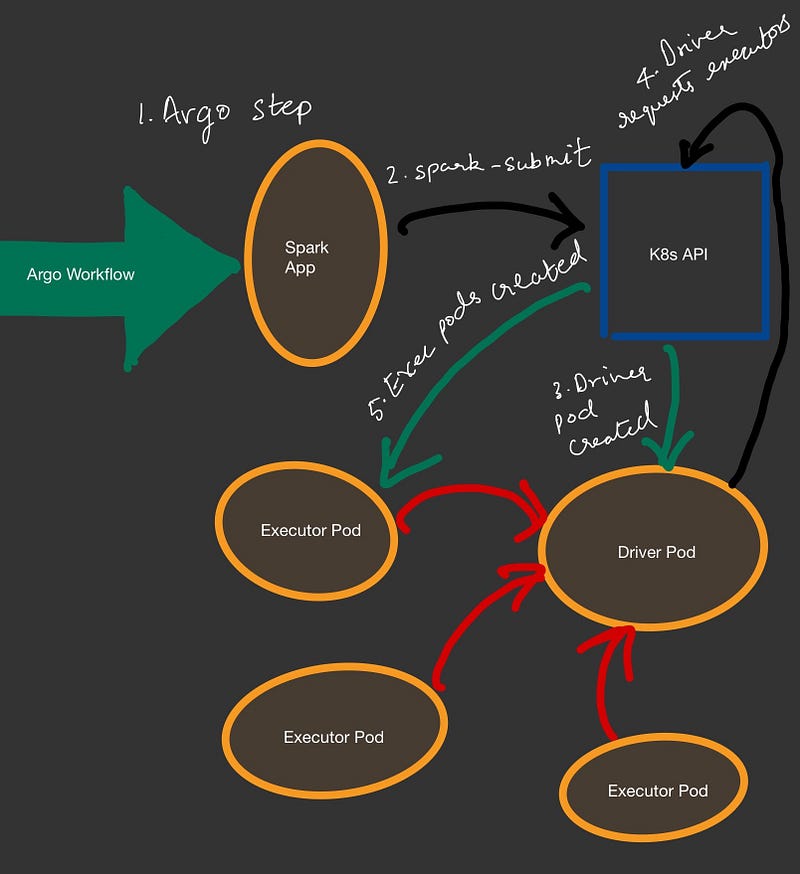
Now how do we submit a spark job from Argo Workflow?
Spark-submit:
apiVersion: argoproj.io/v1alpha1kind: Workflowmetadata: name: wf-spark-pi namespace: argospec: arguments: {} entrypoint: sparkapp templates: - arguments: {} container: args: - /opt/spark/bin/spark-submit - --master - k8s://https://kubernetes.default.svc - --deploy-mode - cluster - --conf - spark.kubernetes.namespace=spark-apps - --conf - spark.kubernetes.container.image=sparkimage - --conf - spark.executor.instances=2 - --class - org.apache.spark.examples.SparkPi - local:///opt/spark/examples/examples/jars/spark-examples_2.12-2.4.2.jar command: - shimage: sparkimage
imagePullPolicy: Always name: "" resources: {} inputs: {} metadata: {} name: sparkapp outputs: {}Spark operator:
We can use Argo Workflow resource template to achieve this. Examples are provided in the link.
For creating spark images this is a good reference.
Please do read this blog for optimizing spark performance on AWS EKS.
I couldn’t find anything online having both Argo Workflow and Spark working together. It was scattered here and there, so thought of collating into one. Hence this article. Hope it helps!





