
Implementation of GoogLeNet on Keras
1. Introduction
GoogLeNet is a deep convolutional neural network that was proposed by Szegedy et al. [1]. This network won the ImageNet Large-Scale Visual Recognition Challenge 2014 (ILSVRC-2014) where 92.3% classification performance was achieved. In particular, this model was designed in a special architecture that allows for increasing the depth and width of the network but keeping the computing resource.
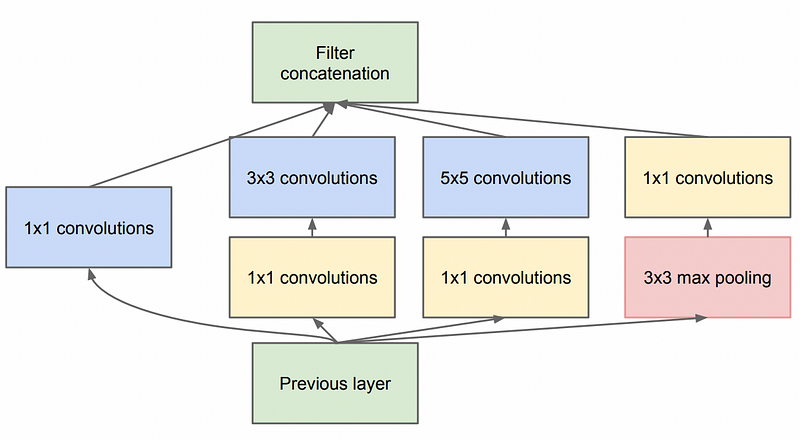
The VGG model has in total 22 layers and it is composed of 9 Inception blocks. Each Inception block consists of four parallel paths at which convolution layers with different kernel sizes are applied [Figure 1]:
- The first path uses a convolutional layer with a window size of 1 × 1.
- In the second and the third paths, a convolutional layer of size 1 × 1 is used before applying two expensive 3 × 3 and 5 × 5 convolutions. The 1×1 convolution helps to reduce the number of filter channels, thus reducing the model complexity.
- The fourth path uses a max-pooling layer to reduce the resolution of the input, and it is followed by a 1 × 1 convolutional layer to reduce the dimension.
These four paths use appropriate padding so that the input and output have the same size. The concatenation of these four paths allows scanning the input in different resolutions. Especially, the model complexity is minimized thanks to the application of a 1 × 1 convolutional layer in each path.
Here is the structure of GoogLeNet with all bells and whistles:
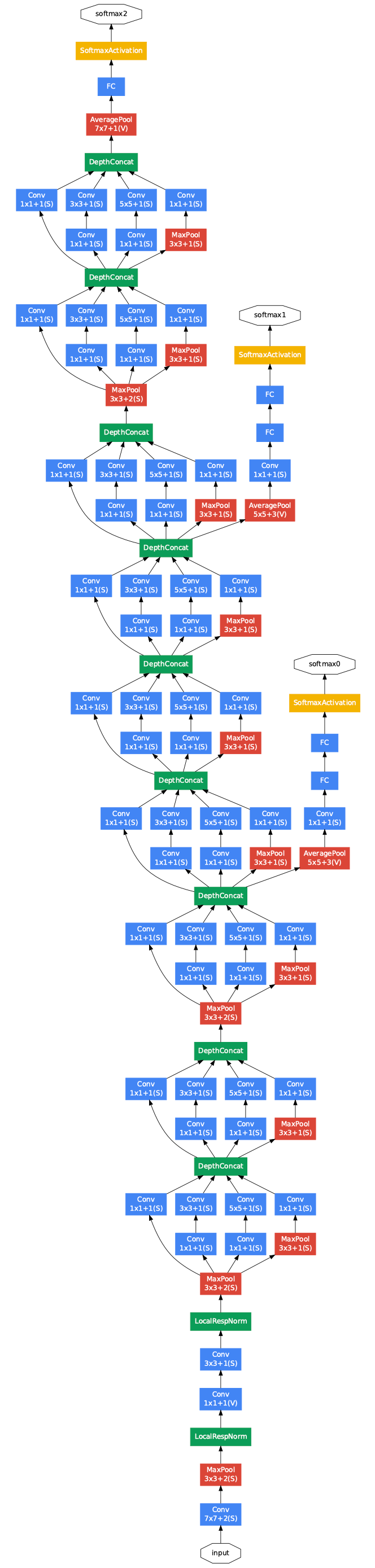
- The input size image is 224 × 224.
- There are nine Inception blocks in this network.
- There are four max-pooling layers outside the Inception blocks, in which two layers are located between blocks 3–4 and block 7–8. These max-pooling layers help to reduce the size of the input data, thus reduce the model complexity as well as the computational cost.
- This network inherits the idea of using an average pooling layer from NiN, which helps to improve the model performance and reduce overfitting.
- A dropout layer (with 40%) is utilized before the linear layer. This is also an efficient regularization method to reduce the overfitting phenomena.
- The output layer uses the softmax activation function to give 1000 outputs which are corresponding to the number of categories in the ImageNet dataset.
Besides, some extra networks are added on the side, which encourages discrimination in the lower stages in the classifier, increases the gradient signal that gets backpropagation, and provides additional regularization. The structure of these networks includes:
→ An average pooling layer with pooling size 5 × 5 and stride 3.
→ A 1 × 1 convolutional layer with 128 filters for dimensional reduction and a rectified linear activation.
→ A fully connected layer with 1024 units and a rectified linear activation.
→ A dropout with a ratio of 70% of outputs.
→ An output layer that used a softmax activation function to classify the object into one of 1000 classes.
2. Implementation of GoogLeNet on Keras
Firstly, we need to import some necessary libraries:
Create an Inception block:
Function to implement the GoogLeNet model:
The total parameter number of this model is 10, 532, 397. Please refer to my code for detailed information on this model.
Although the model is complicated to implement, the parameter number of the whole model is not large. The Dense layers always take a majority of parameters. Besides, the appearance of the global average pooling layers helps to reduce significantly the parameter number, thus reducing the computational complexity of the model.
Conclusion: We have discovered the architecture as well as the implementation of the GoogLeNet model on the Keras platform. It is composed of Inception blocks. Each block has a special architecture where it extracts simultaneously the input features through four parallel paths. Besides, the 1×1 convolutional layers are maximum applied in these paths to reduce channel dimensionality. Moreover, the application of the max-pooling layer between some Inception blocks plays a role in reducing the resolution, thus reducing the computational complexity. In summary, the parameter number of this model is 6x smaller than the Alexnet model and much smaller than the VGG model. Especially, it outperforms these models. This interesting architecture of GoogLeNet is also an inspiration for the appearance of later models.
I hope this post is helpful for you.
Thanks for reading!
____________________________________________________________
References:
[1] Szegedy, Christian, et al. “Going deeper with convolutions.” Proceedings of the IEEE conference on computer vision and pattern recognition. 2015.




