

Imbalanced Dataset — Machine learning Model From End-to-end Implementation-Tensorflow 2.2
Binary Classification
Introduction:
I will walk through how to handle an imbalanced dataset for binary classification. I will use Tensorflow 2.2 for this demo.
Table of Contents:
- What is an imbalanced dataset?
- How to handle an imbalanced dataset?
- Build a machine learning model using Tensorflow 2.2
1.What is an imbalanced dataset?
According to google developers documentation
A binary classification problem in which the labels for the two classes have significantly different frequencies. For example, a disease dataset in which 0.0001 of examples have positive labels and 0.9999 have negative labels is a class-imbalanced problem, but a football game predictor in which 0.51 of examples label one team winning and 0.49 label the other team winning is not a class-imbalanced problem.
What counts as imbalanced?
It depends

2.How to handle an imbalanced dataset?
- Downsampling
- Upweighting
- SMOTE
Otherways
- Collect more data
- Choose the right evaluation metrics
Downsampling: Downsampling means training on a disproportionately low subset of the majority class examples. Consider an example of the fraud data set, with 1 positive to 200 negatives. We can downsample by a factor of 20, taking 1/10 negatives. Now about 10% of our data is positive, which will be much better for training our model. Remember that validation and test data set should remain the same. No downsampling on the validation and test data sets.
Upweighting: means adding an example weight to the downsampled class equal to the factor by which you downsampled. Since we downsampled by a factor of 20, the example weight should be 20.
{example weight} = { original example weight} X { downsampling factor}
SMOTE: SMOTE stands for Synthetic Minority Oversampling Technique. This is a statistical technique for increasing the number of cases in your dataset in a balanced way. This implementation of SMOTE does not change the number of majority cases. The new instances are not just copies of existing minority cases; instead, the algorithm takes samples of the feature space for each target class and its nearest neighbors and generates new examples that combine features of the target case with features of its neighbors. This approach increases the features available to each class and makes the samples more general.
Collect more data:
The simplest approach to solve the imbalanced dataset is to collect more data. Collecting more data has its own disadvantages. It is expensive and also time-consuming. If the data collection is not time-consuming and not costly then definitely worth collecting more data.
Choose the right evaluation metrics:
Whenever the dataset is imbalanced and the classification metric accuracy is not the correct metric. Accuracy is a good metric when the dataset samples are equal in both classes. Consider a scenario where Class A contains 95% of the samples and Class B is only 5%. In this case, the accuracy is going to be always high above 90% even if it predicts wrong on Class B.So for imbalanced dataset accuracy metrics don’t give you a correct picture. Try to use metric precision, recall, and F1 score for imbalanced datasets.
Build a classification machine learning model using Tensorflow 2.2 with an imbalanced dataset.
I used the below dataset from Kaggle
https://www.kaggle.com/arashnic/imbalanced-data-practice
Building a model to predict whether a customer would be interested in Vehicle Insurance is extremely helpful for the company because it can then accordingly plan its communication strategy to reach out to those customers and optimize its business model and revenue.
We have information about:
- Demographics (gender, age, region code type),
- Vehicles (Vehicle Age, Damage),
- Policy (Premium, sourcing channel), etc.
ML Steps:
- Load the data using pandas.
- Do some EDA.
- Feature Engineering.
- Create train, validation, and test sets.
- Create the keras model.
- Train the model.
- Evaluate the model using various metrics (including precision and recall).
- Try for an imbalanced dataset: 1.Class weighting 2. Oversampling
1.Load the CSV File:
2.EDA:
- Check if the dataset is imbalanced. check the Response column and find the distribution.
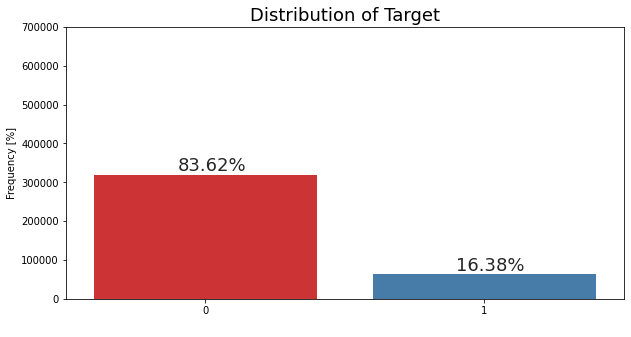
0 319553
1 62601
Name: Response, dtype: int64Examples: Total: 382154 Positive: 62601 (16.38% of total)
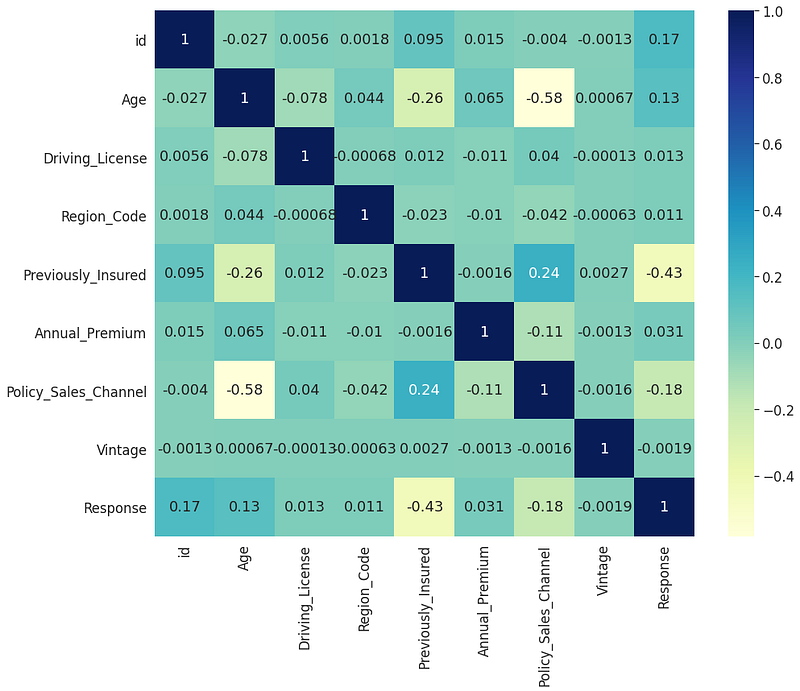
Check the sns pairplot.

A heatmap
Data Preprocessing and Feature engineering:
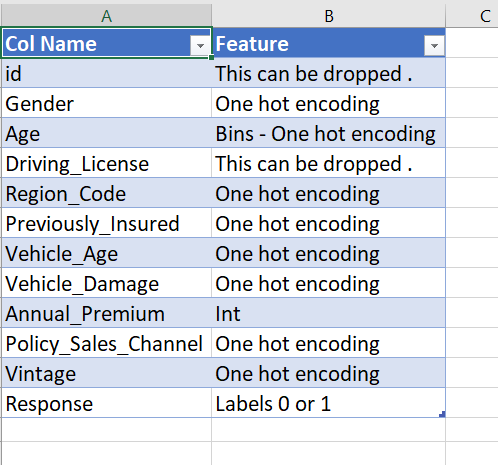
- The ID is not needed and can be dropped.
- The driving_license can also be dropped. People without a license are very few. Also, people without a license and interested in buying vehicle insurance are very few. Hence this feature is not important and can be dropped.
- Convert all the one-hot coding columns from numeric to string and then use the pandas pd.get_dummies.
Split the dataset into training, validation and test :
- Use Sklearn to split the dataset into training, validation, and test datasets.
Normalize the input features using the sklearn StandardScaler. This will set the mean to 0 and standard deviation to 1.The StandardScaler is only fit using the train_features to be sure the model is not peeking at the validation or test sets.
Now the dataset is ready for training. We know the dataset is imbalanced. Lets build the model
- Baseline model-Train a model which can’t handle the class imbalance.
- Train a model with class weights
- Oversampling: Oversample the minority class.
Since the dataset is imbalanced we can’t apply the standard metrics. Accuracy is not a helpful metric for this task. You can 90%+ accuracy on this task by predicting False all the time. In this case, Recall and F1 are the best metrics to evaluate.
Baseline Model:
- A simple neural network with a densely connected hidden layer
- A dropout layer to reduce overfitting
- An output layer with a sigmoid loss function that returns the probability of the output class whether interested in vehicle insurance or not.
- Accuracy = ( True Samples \ Total Samples )
- Precision = ( True Positives \ (True Positives + False Positives)
- Recall = ( True Positives\(True Positives + False Negatives)
- AUC refers to the Area Under the Curve of a Receiver Operating Characteristic curve (ROC-AUC). This metric is equal to the probability that a classifier will rank a random positive sample higher than a random negative sample.
Baseline Model Metrics:
loss : 0.2792171537876129
tp : 3849.0
fp : 3122.0
tn : 73830.0
fn : 11285.0
accuracy : 0.8435484170913696
precision : 0.5521445870399475
recall : 0.25432801246643066
auc : 0.8915838599205017
(True Negatives): 73830
(False Positives): 3122
(False Negatives): 11285
(True Positives): 3849
Total : 15134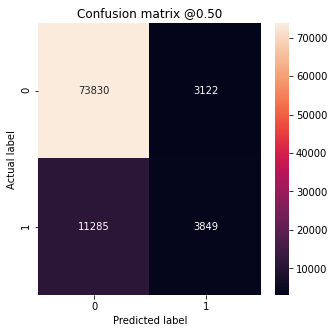
Model with Class Weights:
Weight for class 0: 0.60
Weight for class 1: 3.05Apply the weights
Model With Class Weights Metrics:
loss : 0.3881891071796417
tp : 13815.0
fp : 18721.0
tn : 58231.0
fn : 1319.0
accuracy : 0.7823773622512817
precision : 0.424606591463089
recall : 0.912845253944397
auc : 0.8915590047836304
(True Negatives): 58231
(False Positives): 18721
(False Negatives): 1319
(True Positives): 13815
Total : 15134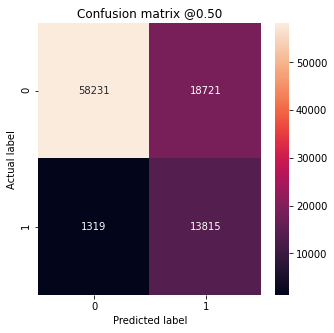
Model: Oversampling: Oversample The Minority class:
This approach is to resample the dataset by oversampling the minority class.
tf.data: provides 2 methods
experimental.sample_from_datasetsexperimental.rejection_resample
We will be using tf.data.experimental.sample_from_datasets
We can usetf.data the easiest way to produce balanced examples is to start with a positive and a negative dataset, and merge them. One approach to resampling a dataset is to use sample_from_datasets. This is more applicable when you have a separate data.Dataset for each class.
Create the dataset tf.data
To use tf.data.experimental.sample_from_datasets pass the datasets, and the weight for each. In our case the code is
Now the dataset produces examples of each class with 50/50 probability.
One problem with the above experimental.sample_from_datasets approach is that it needs a separate tf.data.Dataset per class. Using Dataset.filter works, but results in all the data being loaded twice. The data.experimental.rejection_resample function can be applied to a dataset to rebalance it, while only loading it once. Elements will be dropped from the dataset to achieve balance.data.experimental.rejection_resample takes a class_func argument. This class_func is applied to each dataset element, and is used to determine which class an example belongs to for the purposes of balancing.
Model With Resampled Dataset Metrics:
loss : 0.39975816011428833
tp : 14057.0
fp : 20528.0
tn : 56573.0
fn : 928.0
accuracy : 0.7670004367828369
precision : 0.4064478874206543
recall : 0.9380714297294617
auc : 0.8911738395690918
(True Negatives): 56573
(False Positives): 20528
(False Negatives): 928
(True Positives): 14057
Total : 14985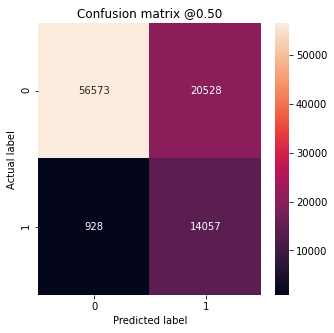
Models Comparison:

When no class weights added or no resampling then the accuracy is higher with 84% which is exactly the percentage of the negative class in the dataset. The dataset is imbalanced with 83% of one class and 17% of other classes. After adding class weights the recall went higher and also when you did the oversampling like increase the samples from the minority class, then the recall went higher.
The full code is below
Conclusion:
It is difficult to predict using an imbalanced dataset. It is always better to collect more data if it is not expensive and time-consuming. Also feature engineering is more important so that your features can extract the most from the minority class. Also, standard metrics won’t apply to imbalanced datasets. Try to change the evaluation metrics based on the datasets and try different methods like adding class weights, resampling, SMOTE to address the imbalanced datasets.
Please feel free to connect with me on LinkedIn
References:
[1] https://www.tensorflow.org/tutorials/structured_data/imbalanced_data [2]https://www.tensorflow.org/guide/data [3]https://towardsdatascience.com/handling-imbalanced-datasets-in-machine-learning-7a0e84220f28