
Image Super-Resolution: An Overview of the Current State of Research
A review of popular techniques and remaining challenges

In a previous article, an overview of super-resolution (SR) and why it has become an important research topic was given. To recap, it is the process in which low-resolution (LR) images are up-sampled to recover the underlying high-quality image. Apart from the resolution, an SR method typically needs to cater for other factors such as blurring, sensor noise, and compression that may also degrade the image quality.
There exist numerous approaches to tackle SR, which can be broadly categorised as being either ‘non-blind’, where the degradations afflicting an image are assumed to be known, or ‘blind’, where the exact degradations afflicting an image are not known.
Whatever the method, they must all define a degradation model that is used to determine the type of LR images to be used. Given that most modern approaches are based on deep learning, much research has been made with regards to the loss functions and evaluation metrics to be used, which can significantly affect the appearance and quality of the end result.
All of this will be discussed in a-bit more detail, along with an overview of the most popular and state-of-the-art approaches in the SR field.
To summarise, the topics that will be covered in this article are as follows:
- Degradation Models
- Non-Blind SR Methods
- Blind SR Methods
- Loss Functions and Evaluation Metrics
- Conclusions and Future Directions
Degradation Models
One of the key components of any SR algorithm is not actually related to the method itself, but rather the data used. Specifically, a degradation model is applied in order to formulate what sort of data is to be used.
Most approaches tend to be supervised learning-based approaches, requiring the use of the ground truth information (corresponding to the original HR images in the case of SR) so that an algorithm knows what the end result should look like when super-resolving a given LR image. Hence, such degradation models are applied directly to the HR images to yield a low-resolution image. Typically, parameters such as the magnitudes of the degradations considered are varied to yield multiple LR images.
The ‘classical’ degradation model is the most commonly used, which considers down-sampling, blurring, and noise:
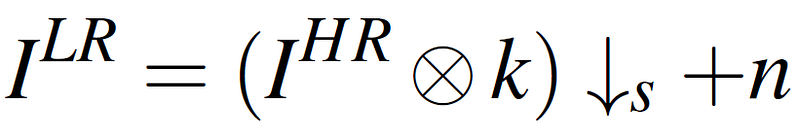
where ⊗ represents a convolution operation, k is a kernel (typically a Gaussian blurring kernel, but it can also represent other functions such as the Point Spread Function (PSF)), n represents additive noise, and ↓s is a downscaling operation that is typically assumed to be bicubic down-sampling with scale factor s.
This model has been criticised for being too simplistic, with methods utilising it being unable to generalise well to more complex degradations that are typically found in real-world images. Hence, recent efforts have attempted to design more realistic degradation models, such as through the inclusion of artefacts caused by compression that are highly prevalent in images:
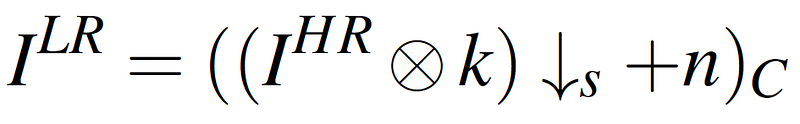
where C is a compression scheme such as JPEG.
Other schemes have also been proposed, such as by applying the classical degradation model more than once, random shuffling of the order in which degradations are applied, and most recently using a ‘random gate controller’ that randomly selects which base degradations are to be used.
The aim of SR is to then reverse whichever degradation process is considered, to retrieve the original underlying high-fidelity image. An overview of popular methods to perform this task will now be provided.
Non-Blind SR Methods
Most works tend to have knowledge on what sort of degradation model was used and are thus known as ‘non-blind’ methods. This is opposed to ‘blind’ models which cannot ‘see’, and thus have no knowledge on, the degradations which could have affected an image. While non-blind methods are not as realistic, they have formed the basis of more complex methods including blind SR methods.
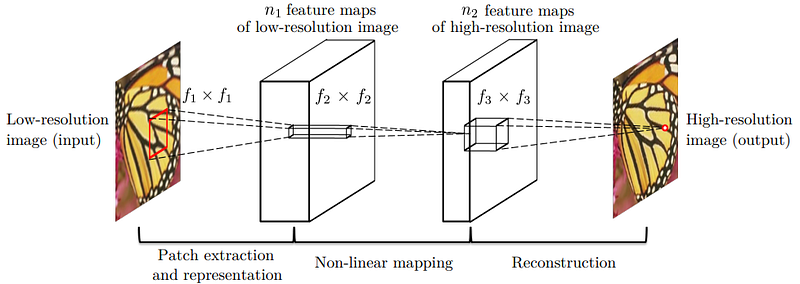
The Super-Resolution Convolutional Neural Network (SRCNN) [1, 2] is considered to be the pioneering work in using deep learning and convolutional neural networks for the task of SR. It only consists of three layers and requires the LR image to be up-sampled using bicubic interpolation prior to being processed by the network, but it was shown to outperform the state-of-the-art methods of the time such as A+ [3] and the sparse-representation-based method in [4]. It was also shown that sparse-coding-based methods are equivalent to convolutional neural networks, which influenced SRCNN’s hyper-parameter settings.
While SRCNN has been used as a benchmark by numerous researchers, it is now comprehensively outclassed and is no longer used so frequently for comparison purposes. However, due to its relative simplicity, it could serve as a good starting point for anyone interested in foraging into the field of deep learning-based SR.
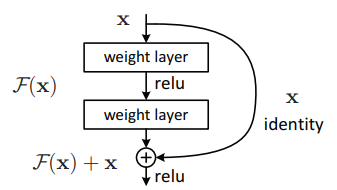
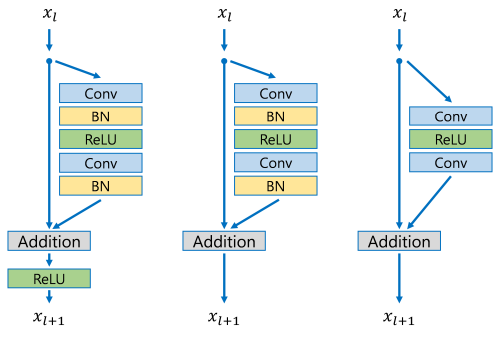
The Residual Network (ResNet) architecture [5, 6] was primarily designed to ease the training of networks as the number of layers increases. Indeed, while many works in literature have indicated that deeper networks provide superior performance, there comes a point when accuracy gets saturated and then quickly degrades. It is shown that this is not due to overfitting, but due to the difficulty in optimising and training very deep networks. In particular, it was noted that deep networks may find it hard to learn identity functions.
To counter this problem, a number of skip/shortcut connections are utilised to directly feed feature maps at any given level of the network to higher layers, thus corresponding to the identity function. In this way, the network would only need to learn a function that suppresses the responses (drive the outputs to zero) of intermediary layers.
ResNet was applied to the SR domain to create SRResNet in [7], where it was also used as the basis of a Generative Adversarial Network (GAN)-based network termed SRGAN.
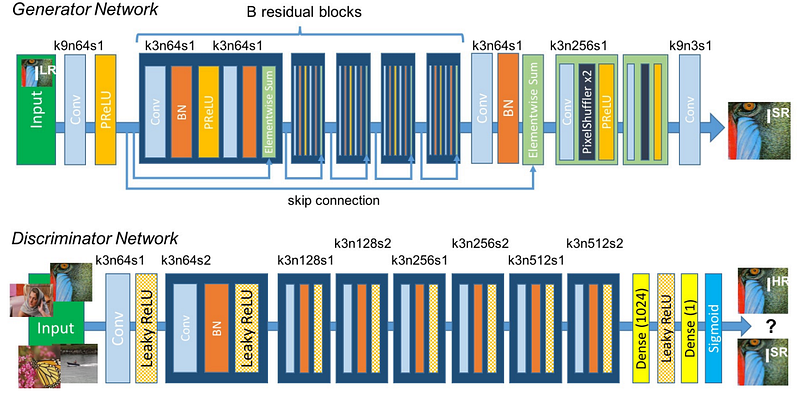
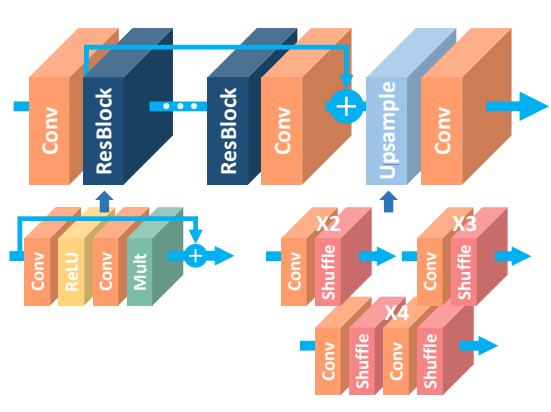
The Enhanced Deep Super-Resolution (EDSR) method [8] was also based on ResNet, and incorporated conclusions reported in previous works such as SRResNet. One of the contributions of the proposed method was the removal of batch normalisation layers, to disable restriction of the feature values and reduce memory usage during training which allows more layers and filters to be used. Residual scaling was also used to ensure stability of the network (especially when using a large number of features).
A multi-scale network called Multi-scale Deep Super-Resolution (MDSR) was also designed, which essentially incorporates a common network for three different up-sampling factors (2, 3, 4) together with scale-specific modules at the pre-processing stage and up-sampling modules at the end of the network composed of convolutional and ‘shuffling’ layers. Hence, the proposed methods do not require the input image to be bicubically-interpolated as in some other works such as SRCNN. The proposed approaches were shown to exceed the performance of methods evaluated in the NTIRE 2017 competition [9].
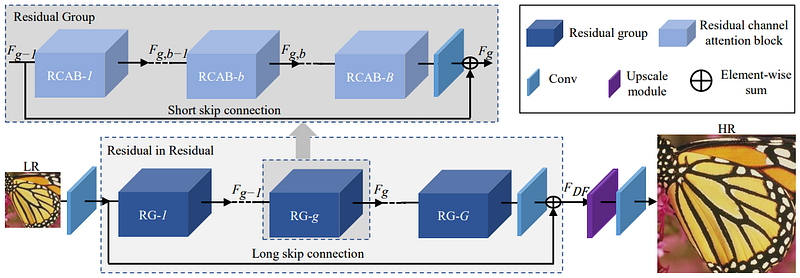
The Residual Channel Attention Network (RCAN) was proposed in [10] to counteract both the difficulty in training very deep CNNs and the assignment of equal importance of the low-frequency information across channels. Thus, RCAN is composed of ‘residual groups’ that each contain a number of ‘residual channel attention blocks’. A ‘long skip connection’ is used with the residual groups, enabling propagation of information from the early stages to the final stages of the network, whereas a ‘short skip connection’ is used within the residual blocks, serving to propagate information at finer levels. The authors also state that this residual-in-residual architecture enables the training of very deep CNNs (more than 400 layers).
RCAN was shown to outperform methods such as SRCNN and EDSR, and remains quite competitive with more modern approaches. It was also shown to be effective for object recognition, where the up-sampled image output by RCAN enables higher accuracies to be achieved when compared to images up-sampled by other methods.
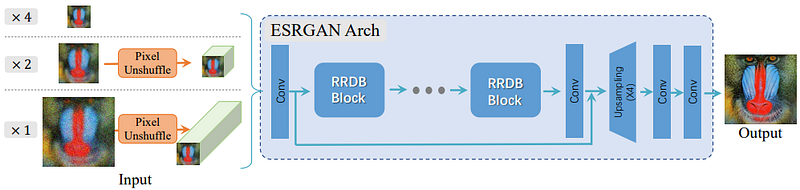
SRGAN was improved in [11] to yield Enhanced SRGAN (ESRGAN), with improvements focused on: (i) the network architecture, where batch normalisation is removed (similarly to EDSR) and the Residual-in-Residual Dense Block (RRDB) is proposed as the basic building block of the network to enable higher network capacity and facilitate training, (ii) the adversarial loss which is modified to determine the relative ‘realness’ of an image (i.e. if an image is more realistic than fake data or less realistic than real data, rather than if it is simply real or fake) as inspired by the relativistic GAN approach [11], and (iii) the perceptual loss, by using the features computed right after the convolution has taken place (i.e. before activation) to reduce the sparsity of features and better supervise brightness consistency and texture recovery. ‘Network interpolation’ also enables a user to balance the trade-off between perceptual quality and PSNR.
Compared to other methods including SRCNN [1, 2], EDSR [8], RCAN [10], and SRGAN [7], it was shown that ESRGAN produces images with sharper edges and better textures, while reducing undesirable artefacts. ESRGAN also won the PIRM2018-SR Challenge [12].

Transformers, originally proposed for use in the Natural Language Processing (NLP) domain, are deep learning models that use an attention mechanism to decide which parts of a sequence are most important. They have become a hot research topic and have also been applied for computer vision tasks, with the Vision Transformer (ViT) considered to be pioneering work in this area [13]. Recently, the application of a transformer-based approach was presented in [14], named the Efficient Super-Resolution Transformer (ESRT).
The Lightweight Transformer Backbone (LTB) is tasked with capturing long-term spatial dependencies across local regions within an image. This is particularly useful if an image contains similar patches at different locations. A CNN is also used as part of the Lightweight CNN Backbone (LCB), which can dynamically adjust feature sizes to extract deep features while maintaining low computational cost. It was shown that ESRT can achieve a very good balance between performance and computational complexity.
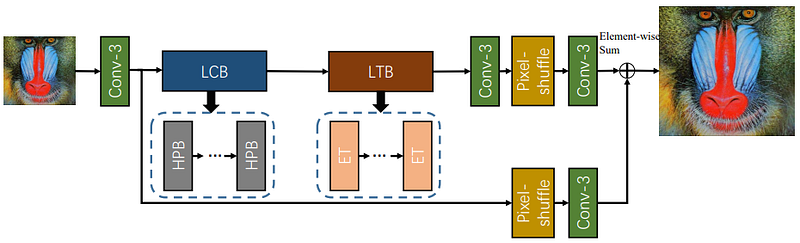
Blind SR Methods
While the non-blind methods mentioned above have provided numerous useful insights into the development of networks for SR, they tend to not be entirely applicable to real-world scenarios. This is because such methods assume a known fixed degradation process, and thus tend to fail when approached with different and more complex degradations than those for which they were specifically trained upon, as are often found in the real world. Moreover, the type of degradations afflicting an image are generally unknown.

Blind SR methods attempt to be more robust to this problem by reducing the assumptions made, even if most approaches still do make some assumptions on the input degradations. A survey by Liu et al. [15], which counts the first author of the seminal SRCNN (C. Dong) as one of its authors, proposes a taxonomy based on the type of data used and how it is modelled.

One group of methods perform SR by allowing other features representing the estimated degradations to be input in addition to the LR image. Hence, the main task of such methods is in how to best use this additional information.
The 12-layer Super-Resolution network for Multiple Degradations (SRMD) [16] is one such method, which considers Gaussian blurring, noise, and down-sampling. A ‘dimensionality stretching’ approach is used, where the blur kernel is vectorised and projected into a smaller dimensionality using Principal Component Analysis (PCA), which is then concatenated with the noise level of the degraded image. Each dimension (element) in this vector is then replicated to obtain a matrix whose width and height are the same as those of the input LR image.
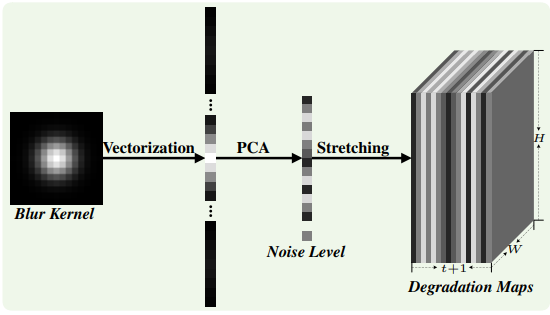
Techniques to extend existing non-blind methods to utilise degradation information have also been proposed [17, 18]. The drawback of this type of methods is that they require accurate degradation information (which is not a trivial task), since any deviations in the estimated inputs lead to kernel mismatches and can thus be detrimental to performance.
To alleviate these issues, methods have been proposed to estimate the degradation kernel during the SR process, such as Iterative Kernel Correction (IKC) [19]. This approach leverages the observation that any kernel mismatches are likely to cause regular patterns, enabling the estimation of the kernel and correcting it in an iterative manner using a corrector network to progressively improve the super-resolved image. In conjunction with a non-blind network also proposed in [19], the Spatial Feature Transform Multiple Degradations (SFTMD) network, superior performance to methods such as SRMD was reportedly achieved.
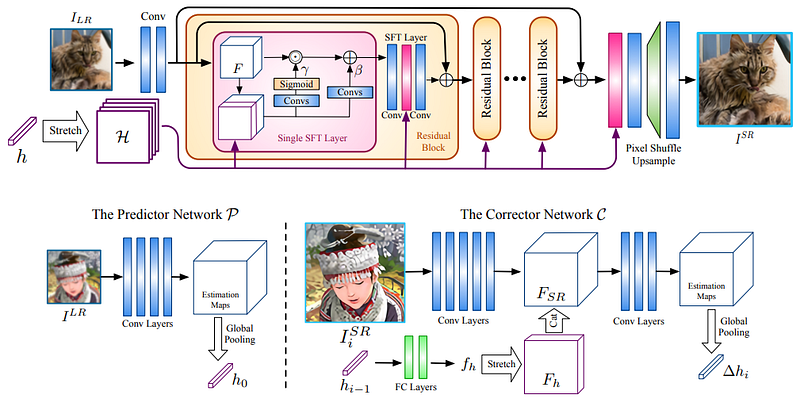
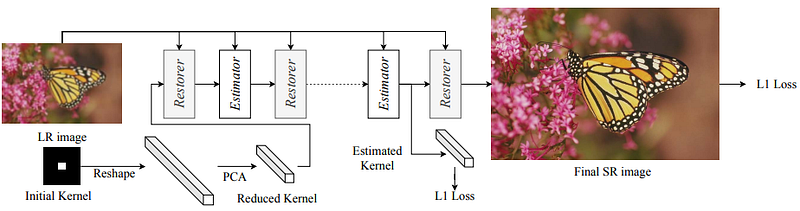
The Deep Alternating Network (DAN) [20] (also known as DANv1) and its updated version DANv2 [21] build upon IKC by unifying the SR and kernel corrector networks within a single end-to-end trainable network, which can make the two networks operate more effectively with each other. To improve the kernel estimation robustness, the corrector was also modified to use the LR input conditioned on intermediate SR results, rather than conditioning the super-resolved images on the estimated kernel as performed in IKC.
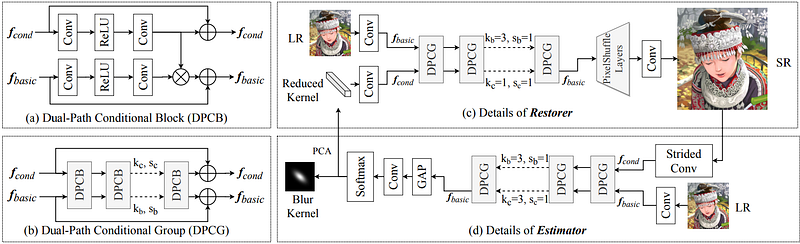
The Kernel-Oriented Adaptive Local Adjustment network (KOALAnet) [22] considers spatially-variant characteristics within an image, and thus attempts to perform local adaptation. This enables a distinction to be made between blur caused due to undesirable effects, and blur caused intentionally for aesthetic purposes (e.g. Bokeh effect).
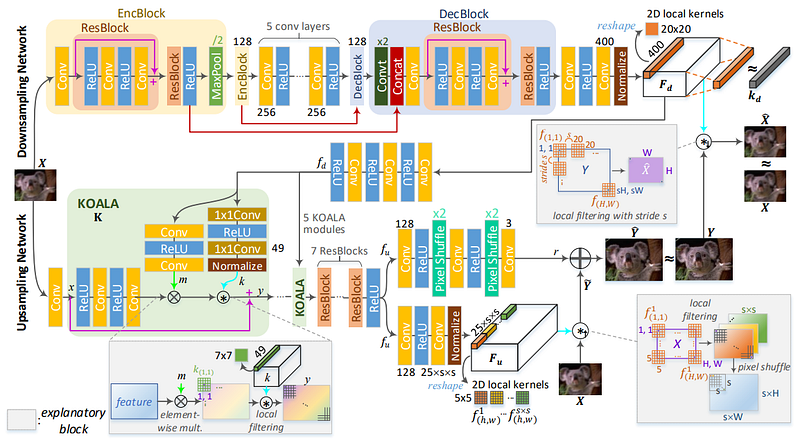
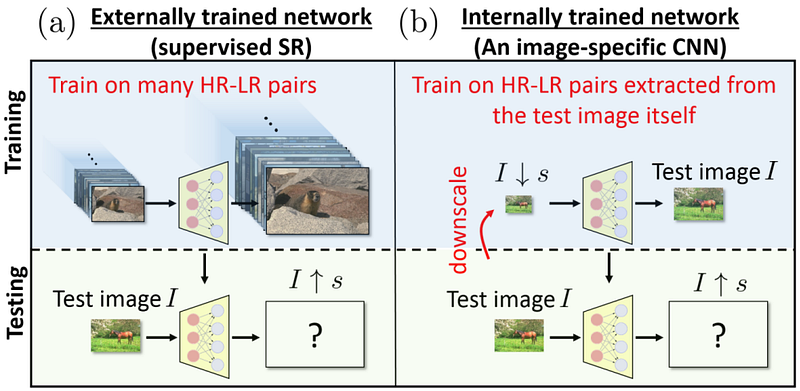
The above approaches may still exhibit poor performance if the LR images contain different degradations than those considered whilst training the models, given that they rely on kernel estimation. Hence, another group of methods such as KernelGAN [23] and “Zero-Shot” SR (ZSSR) [24] leverage internal statistics of natural images and the observation that some patterns are repeated within scales (i.e. at different locations within an image), and across scales (i.e. essentially different sizes). This allows models to be self-supervised and adapt to a single image at a time.
However, it has been argued that the assumption of having recurring patches within and across scales may not hold true for all images (e.g. those containing a wide variety of content or conversely with mostly homogeneous regions).
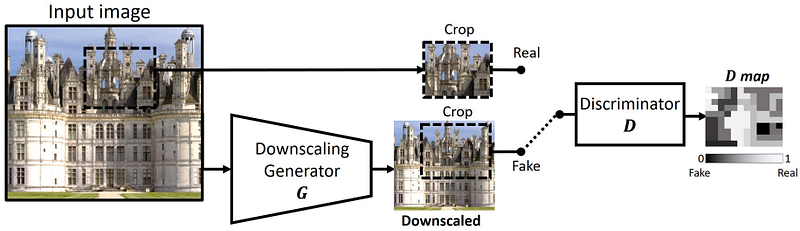
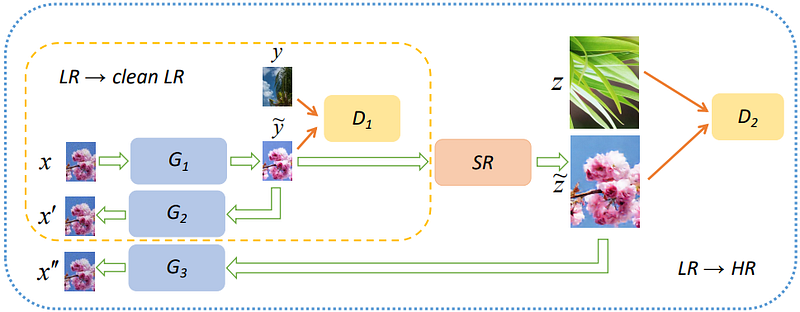
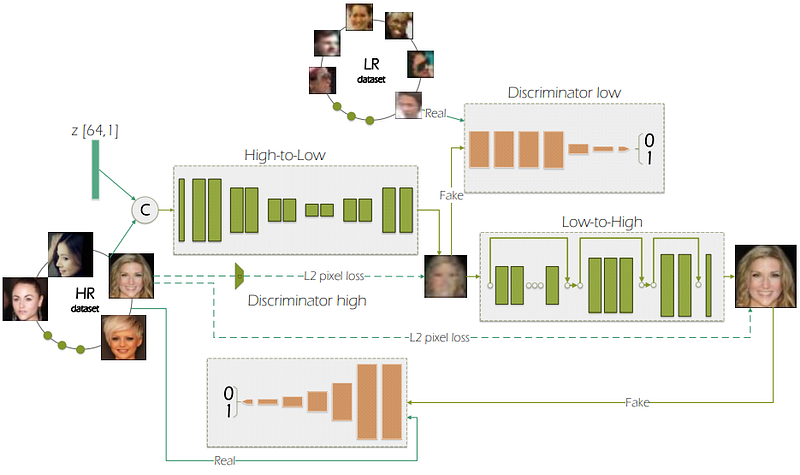
Another group of methods attempt to implicitly model the underlying degradation model, in order to be more robust to real-world LR images where the HR image is not available and thus unknown. Cycle-in-Cycle GAN (CinCGAN) [25] is one such approach, which consists of two CycleGAN [26] networks. The first network attempts to denoise the input image (to yield a ‘clean LR’ image), whereas the second network then learns the mapping from the LR space to the HR space, along with an SR network based on EDSR [8].
Another approach, Real-ESRGAN [27], is an extension of ESRGAN [11] that generates synthetic images using a ‘high-order’ degradation process where a degradation model is essentially applied twice. The main drawback with such methods is that they tend to require vast amounts of data.
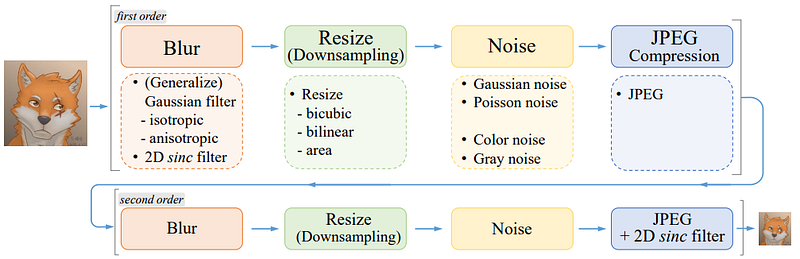
While approaches such as Degradation GAN [17] have attempted to resolve this issue by learning the HR to LR degradation process and thus allow realistic LR samples to be generated and used during the training process of the SR model, most models designed for implicit degradation modelling tend to use GANs which are not easy to train and can introduce fake textures or artefacts that can be detrimental for some applications such as forensics or old photo restoration.
Some approaches also consider multiple modelling modes and data sources, such as Mixture of Experts (MoESR) [28] where different degradation kernels are each handled by specific SR networks (called ‘experts’). The best expert is then used for kernel prediction, while an image’s internal statistics are then utilised to perform fine-tuning.
A recent stream of research that has seen a resurgence is contrastive learning, which has also been applied for SR in methods such as the Degradation-Aware SR (DASR) network [29] and the approach in [30] which was designed for remote sensing images. Contrastive learning is a form of self-supervised learning where the feature representations obtained from image samples exhibiting similar characteristics to an ‘anchor’ representation (typically known as ‘positive’ samples) are brought closer together, while representations that have been acquired from samples bearing different characteristics to the anchor (typically known as ‘negative’ samples) are pushed apart.
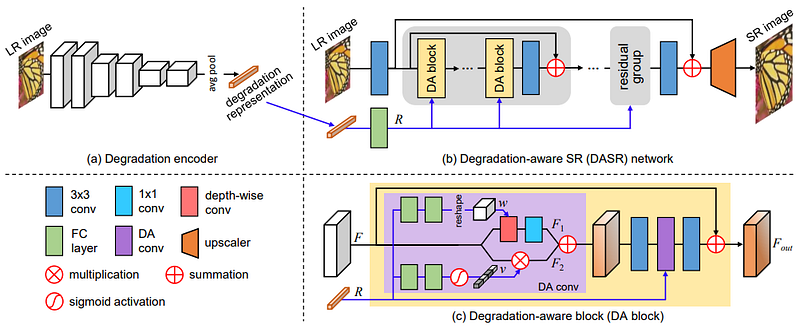
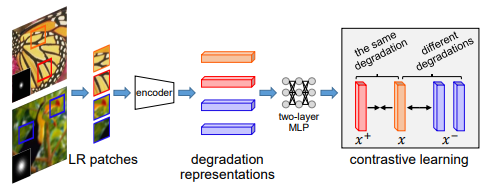
Loss Functions and Evaluation Metrics
All of the above methods use machine learning, where some way to determine if the learned parameters are moving towards the right direction is needed. Any adjustments are then performed to further optimise these parameters and in turn yield (hopefully) more satisfactory results. This is performed using what are known as loss functions, which measure the quality of the results output by a network during the training stage.
The most commonly used loss functions directly compare the LR image with the target (HR) image, such as the L2 loss that forms the basis of Mean Squared Error (MSE) and the closely related Peak Signal-to-Noise Ratio (PSNR). These so-called Full-Reference Image Quality Assessment (FR-IQA) metrics essentially measure the differences between the corresponding pixels of HR and LR images in the case of super-resolution. The task of a training function is to ideally minimise the MSE to zero and conversely maximise PSNR as much as possible.
However, these metrics have long been criticised for not being very well correlated to subjective perceptions of quality, since they perform pixel-wise averaging of possible solutions that consequently lead to blurry results. Hence, images that look perceptually more pleasing may yield lower PSNR values than images that appear to be of lower quality. Moreover, shifting the image even by one pixel in the vertical or horizontal directions can cause the MSE to become large (and the PSNR very low), even if the picture to be evaluated is identical to the original image.

The above issues have given rise to the use of perceptual metrics, which are designed to measure the overall quality of an image that is correlated with how humans perceive quality. The Structural SIMilarity index (SSIM) [32] was designed to counteract this issue, and is very commonly used in the development and evaluation of SR methods.
However, SSIM still compares the image under evaluation with the original HR image and as such is still sensitive to some factors. Moreover, numerous methods that have been shown to be better correlated with human perception of image quality have been developed since SSIM’s creation.
So why aren’t these better-correlated methods used instead? Well, MSE, PSNR, and SSIM are simple metrics that are very fast to compute (handy when you need to evaluate thousands or even millions of images) and are implemented in many common programming libraries, making them very convenient and easy to use. Moreover, they are differentiable, a property that is required to enable deep learning methods to update their parameters.
Perceptual metrics that do not require the original HR image have also been designed, termed No-Reference IQA (NR-IQA) metrics. Examples include BRISQUE [33] and NIQE [34], but these tend to be used primarily during evaluation since they are not differentiable.
An approach that has become quite prevalent in enforcing perceptually pleasing images is the extraction and use of intermediary features from other networks, to yield a type of perceptual loss.
For example, in the case of face SR, networks such as VGG-Face [35] that are designed and trained for face recognition could be used to enforce that intermediary features obtained when processing the HR image and the features obtained when using the super-resolved images are similar with each other. In this way, the loss is computed at the feature level rather than the image level.
Moreover, given that a network trained for faces extracts salient features that are mostly relevant to discerning faces, then the enforcement of feature similarity also enforces the identities and characteristics of the faces to be similar. This helps to prevent the network from ‘hallucinating’ new details that may not have been present in the original image, thereby preventing a change in identity that can be detrimental in several applications as discussed in the previous article.
Perceptual loss functions can be used for virtually any SR application, not just for faces. Indeed, the perceptual loss was initially applied on the super-resolution of generic image content [36].

In the image above, it can be noted that the PSNR value for the method acquired using the perceptual loss is lower (worse) than the result obtained using the per-pixel loss, while the SSIM value is only slightly higher. Moreover, both PSNR and SSIM are lower than the values obtained not only for the image super-resolved by SRCNN, but also for the image up-sampled by the basic bicubic interpolation.
However, it can be argued that the perceptual loss-based result is actually sharper and closer to the ground truth image than the images derived using the pixel-based loss and SRCNN. The authors of [36] state that a slight cross-hatch pattern visible under magnification harms the PSNR and SSIM values compared to the baseline methods. This highlights the need to use IQA metrics that better correlate with subjective perceptions of quality.
Despite the drawbacks of metrics such as PSNR, they are still useful in ensuring that the super-resolved image’s content remains similar to the original image. In other words, if pixel-wise comparisons are not performed, a network could drastically change the image content without being penalised if the image is simply nice to look at. Indeed, this is one of the drawbacks (and also an advantage in some applications) of GANs, which tend to yield good looking images at the expense of synthesising textures and content that may not have been present in the original image.
As mentioned, this can be detrimental in some applications such as face SR where the wrong person could be convicted if the identity is changed, while the actual perpetrator may not be identified. For instance, in Figure 5 of the work proposed by Yu et al. (2018), the super-resolved results of the proposed method look rather good, especially considering that the low-resolution images to be super-resolved have a size of just 16 × 16 pixels. However, one could argue that the identities of some of the individuals are different than those in the original images.
Tuning a network for one loss function type tends to reduce the performance in terms of the other type of loss functions, and vice versa. For example, SRResNet outperforms SRGAN in terms of PSNR, but is then inferior in terms of perceptual quality. Thus, a trade-off usually needs to be performed between the two types of metrics, to enforce that the image content remain similar to the original whilst making the result perceptually pleasing. Obviously, this is dependent on the target application, such that more importance might need to be given to one type of metric over the others.
Conclusions and Future Directions
As can be observed, much work has been done in the area of SR, but there still exist many challenges that need to be overcome. One of the main issues is in the development of SR methods that are truly capable of operating on real-world images in a blind setting where no information about the degradations that could be afflicting an image are assumed.
Moreover, the above discussion has focused on generic image content; there are methods that are designed for specific applications such as face SR. These methods also operate on a single image at a time, thereby termed Single Image SR (SISR) methods; whilst work has also been done to use multiple images (e.g. in videos and multi-spectral satellite imagery) to extract more information and thus improve performance, progress in this area has been more limited compared to SISR.
In conclusion, there are many avenues for future research, which at least guarantees one thing: the future of SR is bright (even if things might look blurry and distorted sometimes 😉)!
Do you have any thoughts about this article? Please feel free to post a note, comment, or message me directly on LinkedIn!
Also, make sure to Follow me to ensure that you’re notified upon publication of future articles.
The author is a post-doctoral researcher at the University of Malta in the Deep-FIR project, which is being done in collaboration with Ascent Software and is financed by the Malta Council for Science & Technology (MCST), for and on behalf of the Foundation for Science & Technology, through the FUSION: R&I Technology Development Programme.
References
[1] C. Dong, C. C. Loy, K. He, and X. Tang, Learning a deep convolutional network for image superresolution (2014), European Conference on Computer Vision (ECCV 2014)
[2] C. Dong, C. C. Loy, K. He, and X. Tang, Image super-resolution using deep convolutional networks (2016), IEEE Transactions on Pattern Analysis and Machine Intelligence
[3] R. Timofte, V. D. Smet, and L. V. Gool, A+: Adjusted Anchored Neighborhood Regression for Fast Super-Resolution (2014), Asian Conference on Computer Vision (ACCV 2014)
[4] J. Yang, J. Wright, T. S. Huang, and Y. Ma, Image super-resolution via sparse representation (2010), IEEE Transactions on Image Processing
[5] K. He, X. Zhang, S. Ren, and J. Sun, Deep residual learning for image recognition (2016), IEEE Conference on Computer Vision and Pattern Recognition (CVPR 2016)
[6] K. He, X. Zhang, S. Ren, and J. Sun, Identity mappings in deep residual networks (2016), European Conference on Computer Vision (ECCV 2016)
[7] C. Ledig, L. Theis, F. Huszr, J. Caballero, A. Cunningham, A. Acosta, A. Aitken, A. Tejani, J. Totz, Z. Wang, and W. Shi, Photo-realistic Single Image Super-Resolution using a Generative Adversarial Network (2017), IEEE Conference on Computer Vision and Pattern Recognition (CVPR 2017)
[8] B. Lim, S. Son, H. Kim, S. Nah, and K. M. Lee, Enhanced deep residual networks for single image super-resolution (2017), IEEE Conference on Computer Vision and Pattern Recognition Workshops (CVPRW 2017)
[9] E. Agustsson and R. Timofte, NTIRE 2017 Challenge on Single Image Super-Resolution: Dataset and Study (2017), IEEE Conference on Computer Vision and Pattern Recognition Workshops (CVPRW 2017)
[10] Y. Zhang, K. Li, K. Li, L. Wang, B. Zhong, and Y. Fu, Image super-resolution using very deep residual channel attention networks (2018), European Conference on Computer Vision (ECCV 2018)
[11] X. Wang, K. Yu, S. Wu, J. Gu, Y. Liu, C. Dong, Y. Qiao, and C. C. Loy, ESRGAN: Enhanced super-resolution generative adversarial networks (2018), European Conference on Computer Vision (ECCV 2018)
[12] Y. Blau, R. Mechrez, R. Timofte, T. Michaeli, and L. Zelnik-Manor, The 2018 PIRM Challenge on Perceptual Image Super-resolution (2018), arXiv
[13] A. Dosovitskiy, L. Beyer, A. Kolesnikov, D. Weissenborn, X. Zhai, T. Unterthiner, M. Dehghani, M. Minderer, G. Heigold, S. Gelly, J. Uszkoreit and N. Houlsby, An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale (2021), International Conference on Learning Representations (ICLR 2021)
[14] Z. Lu, J. Li, H. Liu, C. Huang, L. Zhang, and T. Zeng, Transformer for Single Image Super-Resolution (2022), IEEE Conference on Computer Vision and Pattern Recognition Workshops (CVPRW 2022)
[15] A. Liu, Y. Liu, J. Gu, Y. Qiao and C. Dong, Blind Image Super-Resolution: A Survey and Beyond, (2022), IEEE Transactions on Pattern Analysis and Machine Intelligence
[16] K. Zhang, W. Zuo, and L. Zhang, Learning a single convolutional super-resolution network for multiple degradations (2018), IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR 2018)
[17] A. Bulat, J. Yang, and G. Tzimiropoulos, To learn image super-resolution, use a GAN to learn how to do image degradation first (2018), European Conference on Computer Vision (ECCV 2018)
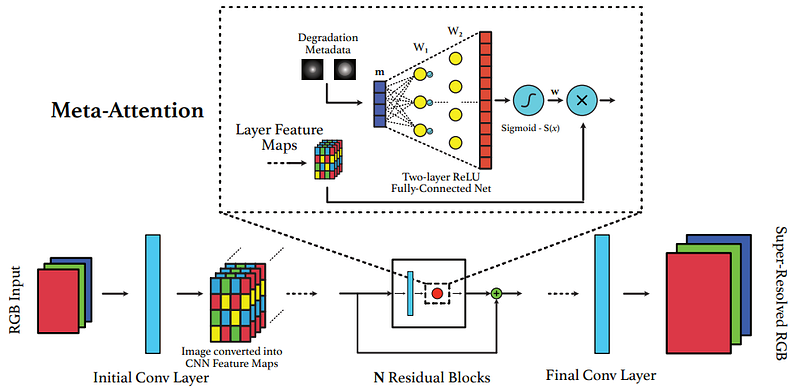
[18] M. Aquilina, C. Galea, J. Abela, K. P. Camilleri, and R. A. Farrugia, Improving super-resolution performance using meta-attention layers (2021), IEEE Signal Processing Letters
[19] J. Gu, H. Lu, W. Zuo, and C. Dong, Blind super-resolution with iterative kernel correction (2019), IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR 2019)
[20] Z. Luo, Y. Huang, S. Li, L. Wang, and T. Tan, Unfolding the alternating optimization for blind super resolution (2020), Advances in Neural Information Processing Systems (NeurIPS)
[21] Z. Luo, Y. Huang, S. Li, L. Wang, and T. Tan, End-to-end alternating optimization for blind super resolution (2021), arXiv
[22] S. Y. Kim, H. Sim, M. Kim, KOALAnet: Blind Super-Resolution using Kernel-Oriented Adaptive Local Adjustment (2021), IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR 2021)
[23] S. Bell-Kligler, A. Shocher, and M. Irani, Blind Super-Resolution Kernel Estimation using an Internal-GAN (2019), Advances in Neural Information Processing Systems (NeurIPS)
[24] A. Shocher, N. Cohen, and M. Irani, “Zero-Shot” Super-Resolution using Deep Internal Learning (2018), IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR 2018)
[25] Y. Yuan, S. Liu, J. Zhang, Y. Zhang, C. Dong, and L. Lin, Unsupervised image super-resolution using cycle-in-cycle generative adversarial networks (2018), IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW 2018)
[26] J. Zhu, T. Park, P. Isola, and A. A. Efros, Unpaired Image-to-Image Translation using Cycle-Consistent Adversarial Networks (2017), IEEE International Conference on Computer Vision (ICCV 2017)
[27] X. Wang, L. Xie, C. Dong, and Y. Shan, Real-ESRGAN: Training Real-World Blind Super-Resolution with Pure Synthetic Data (2021), International Conference on Computer Vision Workshops (ICCVW 2021)
[28] M. Emad, M. Peemen, and H. Corporaal, MoESR: Blind Super-Resolution using Kernel-Aware Mixture of Experts (2022), IEEE/CVF Winter Conference on Applications of Computer Vision (WACV 2022)
[29] L. Wang, Y. Wang, X. Dong, Q. Xu, J. Yang, W. An, and Y. Guo, Unsupervised degradation representation learning for blind super-resolution (2021), IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR 2021)
[30] G. Yin, W. Wang, Z. Yuan, W. Ji, D. Yu, S. Sun, T.-S. Chua, and C. Wang, Conditional hyper-network for blind super-resolution with multiple degradations (2022), IEEE Transactions on Image Processing
[31] M. S. M. Sajjadi, B. Schlkopf, and M. Hirsch, EnhanceNet: Single Image Super-Resolution Through Automated Texture Synthesis (2017), IEEE International Conference on Computer Vision (ICCV 2017)
[32] Zhou Wang, A. C. Bovik, H. R. Sheikh and E. P. Simoncelli, Image quality assessment: from error visibility to structural similarity (2004), IEEE Transactions on Image Processing
[33] A. Mittal, A. K. Moorthy and A. C. Bovik, No-Reference Image Quality Assessment in the Spatial Domain (2012), IEEE Transactions on Image Processing
[34] A. Mittal, R. Soundararajan and A. C. Bovik, Making a “Completely Blind” Image Quality Analyzer (2013), IEEE Signal Processing Letters
[35] O. M. Parkhi, A. Vedaldi, and A. Zisserman, Deep face recognition (2015), British Machine Vision Conference (BMVC 2015)
[36] J. Johnson, A. Alahi, L. Fei-Fei, Perceptual Losses for Real-Time Style Transfer and Super-Resolution (2016), European Conference on Computer Vision (ECCV 2016)