
IA pour tous (semaine 1)

L’Intelligence Artificielle (IA) est entrain de transformer tous les secteurs. Quels en sont les possibilités, les limites et les impacts? Le dernier cours d’Andrew Ng (AI for everyone) vous donne les clés pour comprendre cette transformation digitale de notre société ainsi que les outils pour l’appliquer dans vos activités.
Cet article fait partie de la série “Deep Learning in Practice” (à lire également les versions en anglais et en portugais).
Liste des articles “IA pour tous”
- IA pour tous (semaine 1)
- Développer un projet IA (semaine 2)
- Utiliser l’IA dans votre entreprise (semaine 3)
- IA et société (semaine 4)
Introduction
Vous êtes programmateur ou au moins intéressé par le codage? Vous pouvez accéder sur Internet à des dizaines de MOOCs (parfois gratuits) pour apprendre à créer des modèles d’IA (comme des modèle de réseaux neuronaux profonds ou Deep Learning) comme par exemple ceux de Jeremy Howard (fastai) et d’Andrew Ng (deeplearning.ai).
Grâce à ces MOOCs - et avec de la persévérance - toute personne intéressée par le codage et l’IA peut devenir un praticien de l’IA.
Cependant, la transformation digitale par l’IA des organismes publics et des entreprises nécessite également une compréhension des possibilités, limites et impacts de l’IA et cela par l’ensemble des employés, pas seulement par les équipes techniques. En effet, incorporer l’IA dans des processus existants nécessite bien sûr une validation de l’exécutif (qui doit donc en comprendre les enjeux) et peut par ailleurs avoir comme conséquence de modifier partiellement ou totalement les activités existantes.
Il est donc nécessaire de sensibiliser les responsables et décideurs par une approche non technique de l’IA comme l’a fait Omar bin Sultan Al Olama, ministre d’Etat de l’Intelligence Artificielle des Emirats Arabes Unis, avec l’université d’Oxford via un programme d’un an qui a permis de former 94 agents du gouvernement (source).
Le dernier MOOC d’Andrew Ng (AI for everyone) donne les informations clés nécessaires à la mise en place de ce type de formation ainsi qu’un AI Transformation PlayBook en ligne permettant à tout organisme de réfléchir à sa propre stratégie de mutation vers l’IA.
Le contenu de ce MOOC est gratuit et en voici selon nous les éléments clés de la semaine 1.
Crédit: toutes les images de cet article proviennent du MOOC d’Andrew Ng, AI for everyone.
Conseils pour un formateur
Le contenu de cette semaine 1 contient tous les éléments essentiels pour comprendre l’IA, ses possibilités, ses limites et comment la mettre en place dans les processus automatisables d’une entreprise afin qu’elle devienne une entreprise IA (le contenu de la semaine 2 permet d’aller plus en détails sur la méthodologie d’utilisation de l’IA dans les projets).
Le formateur doit présenter l’IA de manière Top-Down en commençant par son impact à court et moyen terme en terme de création de valeur supplémentaire. En effet, en découvrant les prédictions de création de valeur dans son secteur, le participant aura ainsi un intérêt personnel à comprendre l’IA, et donc une motivation supplémentaire.
Le cours doit s’appuyer sur des exemples simples et compréhensibles par tous.
En fin de cours, après avoir présenté la réalité de l’IA sous forme de modèles de Machine Learning (et en particulier de Deep Learning), le formateur présentera les 5 étapes de transformation d’une entreprise en une entreprise IA, puis multipliera les exemples de ce que peut faire l’IA et de ce qu’elle ne peut pas faire.
Points-clés de la semaine 1
. Création de valeur dans tous les secteurs . Des IAs, pas une IA . IA → Machine Learning → Supervised Learning . Pourquoi maintenant? Big Data et GPU . Acquérir des données d’entraînement . Problèmes avec les données . Différences entre Machine Learning et Data Science . Deep Learning . Caractéristiques d’une entreprise IA . 5 étapes pour devenir une entreprise IA . Comment savoir si l’IA peut être utilisée? . Conseils pour obtenir un modèle DL performant
Création de valeur dans tous les secteurs
13 trillions de dollar d’ici à 2030 (Mckinsey, septembre 2018) avec presque 1 trillion dans le commerce (les métiers les moins touchés seront ceux à haute valeur manuelle comme coiffeur ou chirurgien).
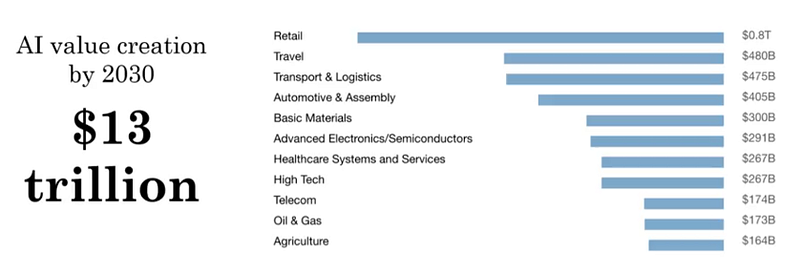
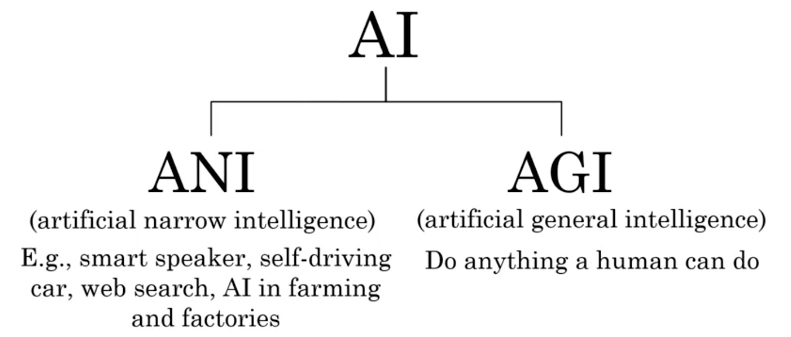
Des IAs, pas une IA
Si l’IA regroupe à la fois les ANI (Artificial Narrow Intelligence) et l’AGI (Artificial General Intelligence), cette dernière n’existe pas (et n’existera pas avant très longtemps). Ce que nous savons développer aujourd’hui, ce sont des IAs, chacune étant spécialisée à réaliser une seule tâche.
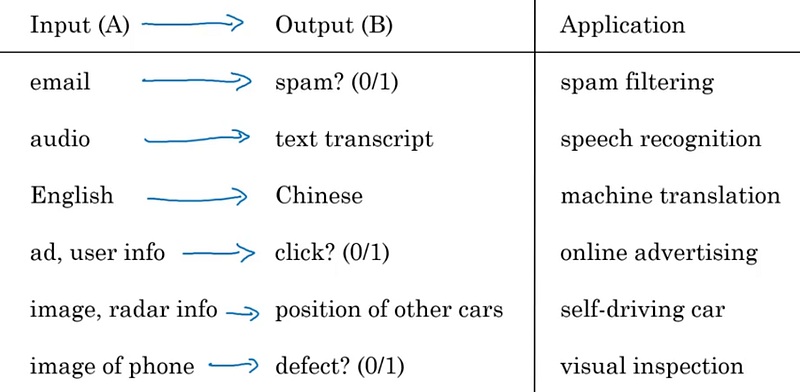
IA → Machine Learning → Supervised Learning
Dans la grande majorité des cas, l’IA est en fait un modèle de Machine Learning (cad un modèle qui apprend à partir d’exemples) dont l’apprentissage se fait de manière supervisée (Supervised Learning). On peut ainsi résumer qu’un modèle IA est très souvent un modèle qui apprend à donner une sortie B (prédiction) à partir d’un entrée A (donnée).
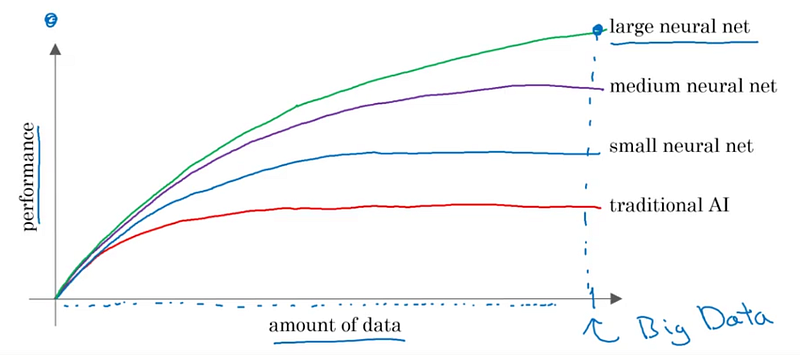
Pourquoi maintenant? Big Data et GPU
Nous disposons aujourd’hui de beaucoup de données (jusqu’au Big Data) et de la capacité computationnelle de les analyser (GPU). Il est donc possible d’entraîner des modèles de réseaux neuronaux profonds (Deep Learning) dont les performances sont supérieures aux autres modèles et croissent avec le nombre de données d’entraînement.
Acquérir des données d’entraînement
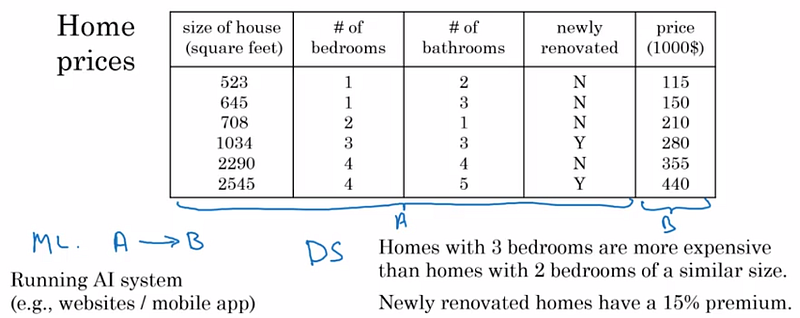
Les données (dataset) pour entraîner un modèle IA se répartissent en 2 groupes: données structurées (structured) et non structurées (unstructured). Dans le premier groupe, on trouve toutes les données sous forme de tableau et dans le second, les données de type texte, voix et image. Dans les 2 cas, chaque donnée est en faite une paire (A,B), B étant la cible/l’étiquette de A. Par exemple, un ensemble de chiffres concernant une maison (A) a comme cible son prix (B) et l’image d’un chat (A) a comme étiquette “chat” (B).
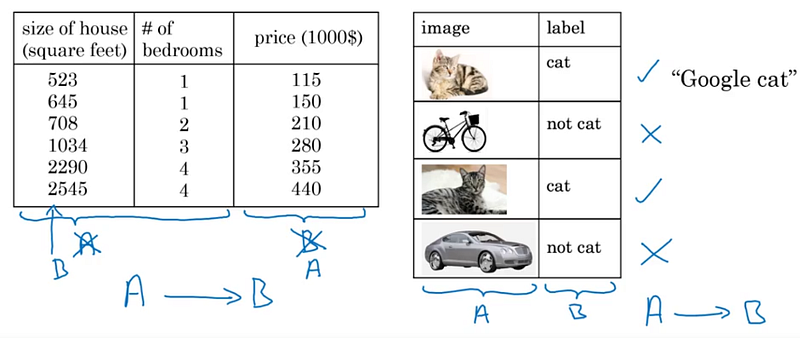
Pour obtenir un dataset qui permettra d’entraîner un modèle IA pour une tâche particulière, il existe 3 possibilités: le créer en l’étiquetant (manual labeling), l’obtenir par enregistrement de données (from observing behaviors) ou le télécharger (download from websites/partnerships).
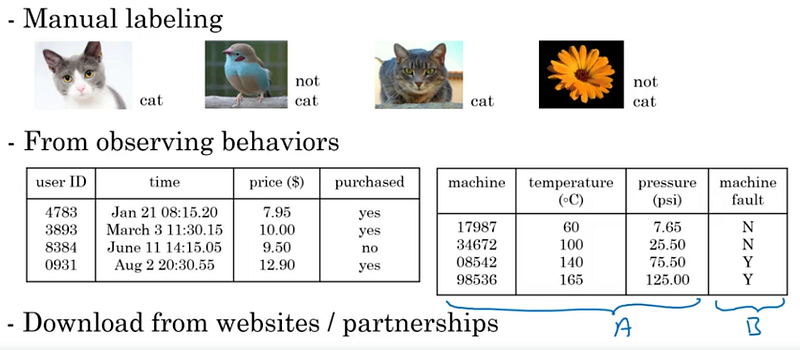
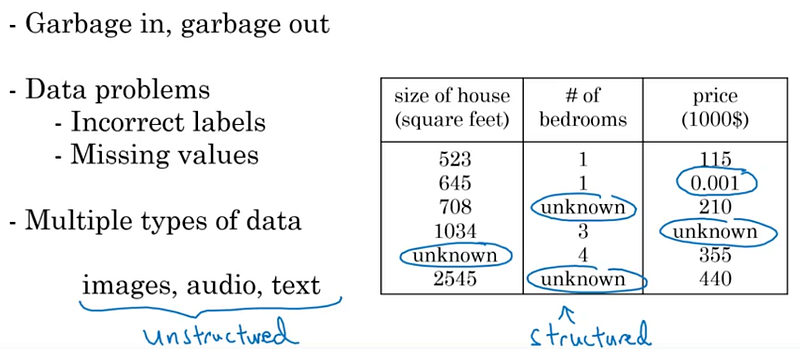
Problèmes avec les données
Si avoir des données est essentiel pour entraîner un modèle IA, son acquisition doit se faire en coopération entre l’équipe IA et l’équipe concernée par le projet (IT s’il s’agit de données sur la technique, Marketing s’il s’agit de données de promotion et ventes, etc.). En effet, l’équipe IA pourra guider l’équipe projet sur la nature, quantité et qualité des données à acquérir pour améliorer la performance du modèle IA (ex.: enregistrement toutes les minutes et pas seulement toutes les 10 minutes, des images en quantité similaire dans les différentes catégories, etc.).

Dans la pratique, il est nécessaire de pré-traiter les données avant de les utiliser pour entraîner un modèle IA car si les données contiennent des erreurs (garbage in), le modèle ne pourra pas être performant (garbage out). Les erreurs peuvent être des étiquettes incorrectes, des valeurs fausses ou manquantes ainsi que des données de nature différente.
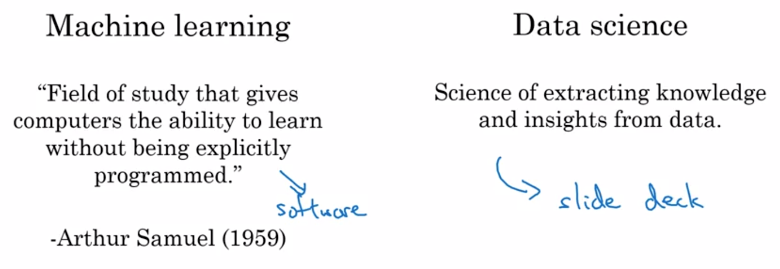
Différences entre Machine Learning et Data Science
Beaucoup d’organismes utilisent déjà la Data Science pour analyser leurs données afin d’en extraire les caractéristiques principales (ex: importance de tel ou tel paramètre sur la valeur de la cible, tendances générales, etc.). Des outils de Business Intelligence (BI) leur permettent aussi d’interagir visuellement avec elles (slide deck). Le Machine Learning génère quant à lui une application prédictive (software) capable de répondre à une seule question. En résumé, la Data Science permet de visualiser le passé et le Machine Learning permet de prédire le futur.
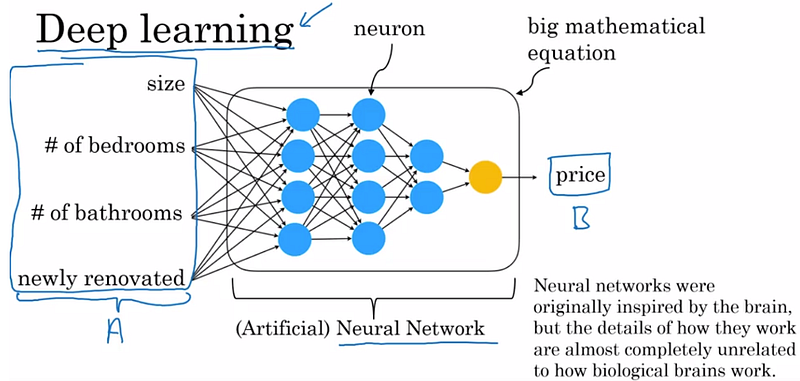
Deep Learning
Le Machine Learning qui est un sous-ensemble de l’IA contient lui-même des sous-ensembles dont le plus performant est le Deep Learning (DL). Originellement inspirés par les réseaux de neurones du cerveau, les modèles de DL sont composés de plusieurs couches d’unités computationnelles (neurones artificiels), chacune capable de détecter des caractéristiques de plus en plus compliquées d’un dataset d’entrainement. En fait, grâce à l’entraînement à partir d’un dataset, un modèle DL se crée une représentation du monde qu’il pourra alors appliquer à toute nouvelle donnée A similaire à celles du dataset pour prédire B.
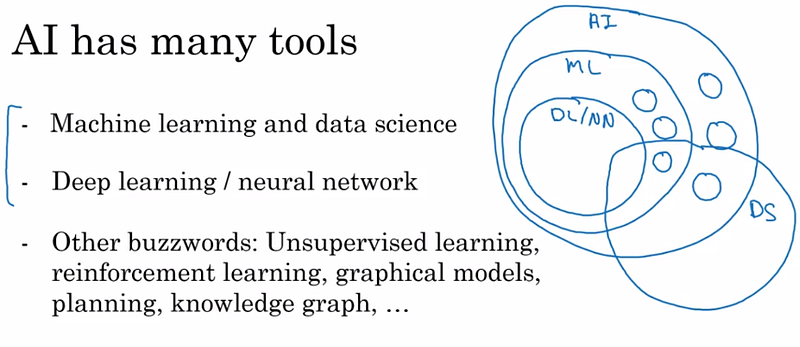
Caractéristiques d’une entreprise IA
Comme avoir un site Internet ne suffit pas pour devenir une entreprise Internet, il ne suffit pas d’utiliser un ou plusieurs modèles DL pour devenir une entreprise IA. L’organigramme de l’entreprise, sa stratégie d’acquisition et de stockage des données et ses processus automatisables doivent prendre en compte l’IA.

5 étapes pour devenir une entreprise IA

Comment savoir si l’IA peut être utilisée?
Une règle empirique imparfaite que vous pouvez utiliser pour décider d’utiliser ou non un modèle IA dans un processus existant est la suivante: tout ce que vous pourriez faire en réfléchissant en moins de une seconde, vous pourriez probablement l’automatiser via un modèle DL du type Supervised Learning.



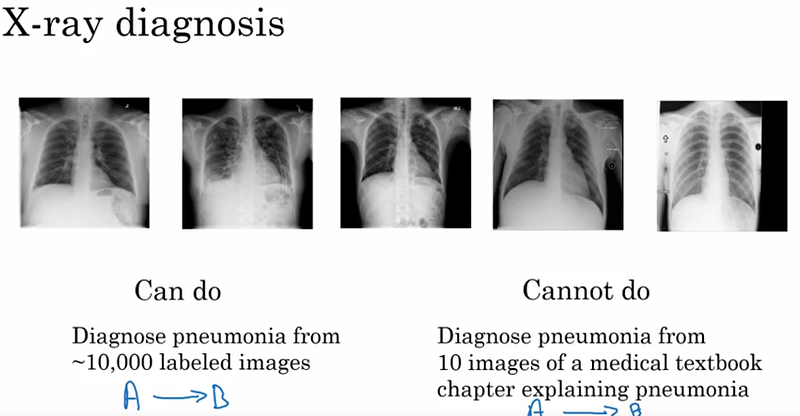
Conseils pour obtenir un modèle DL performant


A propos de l’auteur: Pierre Guillou est consultant en intelligence artificielle au Brésil et en France. Merci de le contacter via son profil Linkedin.