
I have asked this cache question to a couple of senior positions
When I see “I boost system performance X times faster by using Y cache”
Cache is hard
There are only two hard things in Computer Science: cache invalidation and naming things.
- - Phil Karlton
When we work with cache, it brings performance, but it also brings problems. the biggest problem is — data consistency.
Let’s walk it through with interview details.
Story#1 — cache in the small world
Many candidates are not aware there is a cache at the CPU level.
“You mentioned here fixed a critical issue in multi-threading code, could you explain what was that?”.
“Sure, I volatile my variable which is shared across multi-threads.”. he answered.
“So what is the value type of this volatile, and why are you using it”?
“It is an integer, to make sure all threads can get the updated value of the variable”, he said.
“Do you know the cost of using it? And could you pls explain why it works?”.
“I’m not sure about it, it just works. without volatile, multiple threads seeing different values,” he said.
Actually, he was not wrong, I just want to dig into more to touch the limit (was a senior role of C#).
“Do you know about CPU cache? And could you tell me what’s the difference between volatile and lock keywords?”.
“I guess using volatile could be faster”, he said.
we discussed something else.
…
don’t get me wrong, I am good with the answer.
In this post, we just to discuss more.
Cpu level cache
When we work in multi-threading code, to ensure thread safety(automatic operation), we use locks or synchronized keywords. under the hood, it uses semaphore or mutex.
In case you are not familiar with semaphore, you can check this post and in case you want to have a general idea about the difference between threading and processing or coroutine, you can check here.
Let’s move on and see a thread race condition problem.
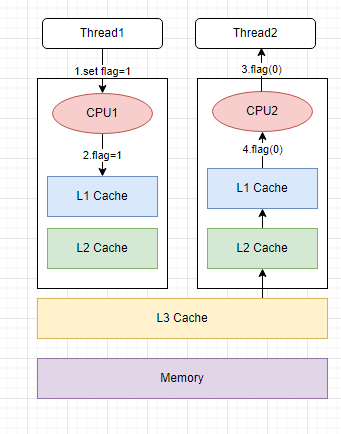
So at the CPU level, there are multi-level caches. L1 and L2 are within “each CPU world”. they have a shared L3 cache, and yes, Memory is hit when the cache is missed in all 3 levels.
As a software(not hardware) developer, we do not need to know many details, only roughly how the cache inconsistency problem happens is enough.
So here as you can see:
- Thread1 updates the variable ‘flag’=1
- And very quickly at the same time when thread2 tries to read the value, it gets flag=0. because CPU2’s L1 or L2 cache is hit which stores the old value.
Eventually, thread2 carries a wrong status value ‘0’ to continue the logic.
So we already know that the lock can make it work. but it is not cheap, what if we only have a boolean variable like ‘flag=true/false’? Is there a cheaper way to make sure this variable is “VISIBLE” to other threads? yes, that’s where the ‘volatile’ keyword comes into play.
How volatile exactly works
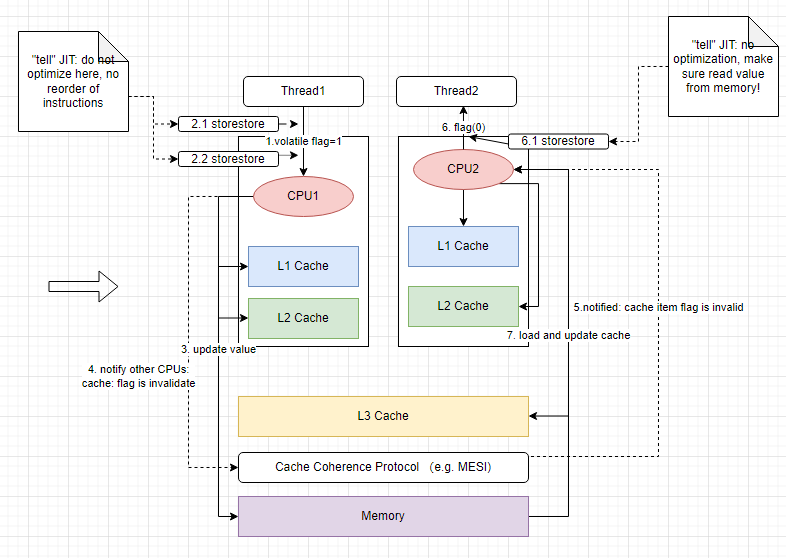
The above picture has a couple of steps but just 3 key points.
- Cache Coherence protocol e.g. MESI. it depends on CPU architecture, there are different cache coherence protocols implemented. so in step 3 above, after the volatile variable is updated, the CPU will “tell” other CPUs that this ‘flag’ variable’s value is updated, pls directly read from memory and update “your cache”.
- Snooping (Bus-based coherence). Snooping is a mechanism used in bus-based cache coherence protocols (e.g., MESI) where each CPU monitors the system bus for changes to memory locations; When a CPU writes to a memory location, other CPUs snoop the bus to detect changes and update their caches accordingly; This mechanism helps maintain cache coherence by ensuring that all CPUs have a consistent view of memory.
- Memory barrier. for languages like Java or C#, there is JIT (just in time) compiler. this command is to “tell” the compiler that “before and after the read or write this volatile variable, do not insert any instructions”. to make sure the read/write is on the main memory.
As you can see, it works completely differently from the lock. and this is the reason why volatile is safe to be used in boolean type, it can guarantee memory visibility, but not automatic operation (still needs lock).
So far good?
Let’s move on to system system-level cache coherence problem.
Story #2 — Cache at system level
“Here you mentioned that increased system throughput 3–4 times by introducing a cache, it was amazing, could you elaborate more?” I asked.
“Sure, it was xx cache. We used it to store yy”. he said.
“How do you make sure cache and database values are in sync? and have you faced any issues with the cache being out of sync with a database?”
“We faced an issue the cache was not updated. Then we used the write-through strategy which solved it”. he said.
“Write through could solve cache coherence issue?” I asked.
“Yes, initially we only deleted cache but not update and having issues then we changed to write-through,” he said.
“Ok, what about this case ….” I described the problem exactly like below.
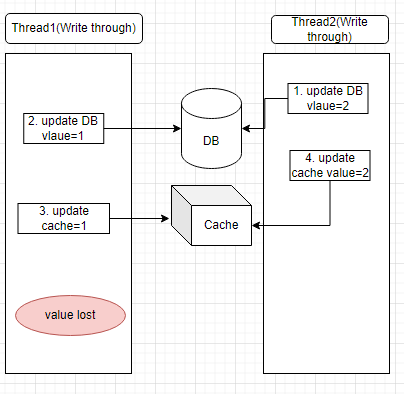
“Sorry, I think we solved the problem not using write-through, but read through”. he said.
“Then how about this case when using read-through, ….” I described the below case to him.
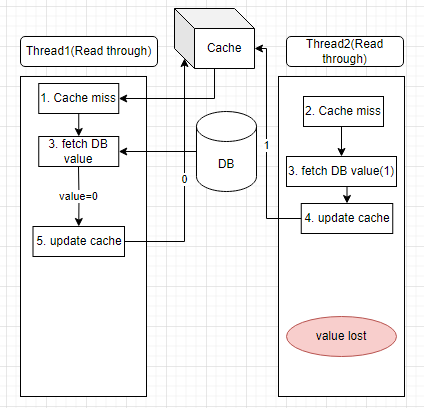
“I can not remember correctly. maybe we delete cache then update the database or update then delete cache can solve the problem?” he said.
I explained to him both the below 2 cases won’t solve the cache coherence issue.
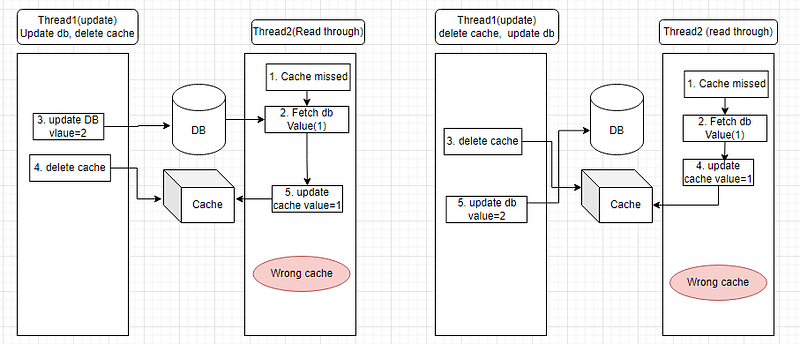
We discussed something else.
…
Let’s try some solutions.
A dirty patch
Whenever we delete the cache, make sure it is not outdated by another racing thread. So what if:
- we delete it again after X minutes (archive eventually consistency).
- X = the max out-of-sync minutes that can be tolerated.
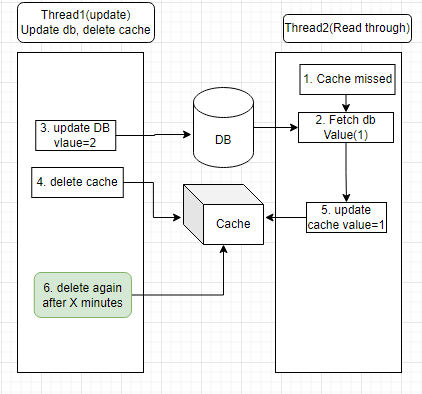
No, what if it is a finance system, we want it 0 minutes out of sync — meaning strong consistency.
Strong consistency
Sure then we have to sacrifice a bit of performance. using the distributed lock. you can either choose a database table or Redis (cluster) to do that.
- When accessing the cache. check the lock record, if no record then insert
- Once done remove the lock record
This way could achieve strong consistency but the lock could be bottlenecked in the system throughput.
What if we want a bit better performance?
Then we need to be a bit more “optimistic”.
Versioning of cache item
When accessing a cache item:
- Get the version of the cache item
- Before updating(or deleting) it, if the version is the same then do update.
Wait, there is a chance that after checking, there is another thread that updated the value very quickly. true, there is such a case, but not always. and that’s why — versioning can not guarantee 100% strong consistency.
If you really need to make sure 100% and want a bit more throughput. maybe can combine it with the above locking, before updating, lock it then update then release the lock.
Multiple nodes
What if my cache is distributed? and when I delete one cache then need to notify other nodes the cache is invalid.
Remember how “CPU” “tells” other “CPUs” that its cache is outdated? just use the same idea. at the CPU level, it uses bus snooping with MESI protocol, at the system level we can use a message queue(or subscribe to Mysql binlog) to do pub/sub.
What if delete failed, Let’s say some nodes never ack the message. retry.
Recap
Nothing is free. including the use of cache.
The cache coherence issue is everywhere. CPU level(lock, volatile), database level(all kinds of locks, MVCC)
When you are asked questions about cache consistency issues during an interview.
5 words and 2 sentences.
- “double” invalidate
- Lock
- Versioning
- Pub/Sub
- Retry
Strong consistency, lock; Better performance, versioning (not guarantee 100% consistency); Balancing performance and data consistency, combine both.
That’s all. hope you enjoyed it. see you in the next post!




