
I Fine-Tuned GPT-2 on 100K Scientific Papers. Here’s The Result
Content writing by AI is common, but is it possible for an AI to write technical essays?

Artificial agents are widely used nowadays and are able to achieve superhuman performance in multiple tasks. Text generation is one of the emerging applications of AI and is used in several scenarios. Freeform text generation, Q&A, and abstractive summarization are only some of them.
To investigate whether an AI could write technical essays I trained a casual language model on about 100K machine learning papers.
What is the quality of the result? What are the limitations of the proposed approach? Is it possible to get GPT-2 to write a full paper? These are the question that I will try to answer.
Introduction
The Generative Pre-Trained Transformer (GPT) 2 is an artificial intelligence developed by OpenAI in 2019 and allows for several purposes: text summarization, translation, question-answering, and text generation. GPT-2 is pre-trained on a large English data corpus, furthermore can be fine-tuned for a specific task.
In this article, I will use the Huggingface Distilled-GPT2 (DistilGPT2) model. DistilGPT2 has 82 million parameters and was developed by knowledge distillation, moreover is lighter and faster than GPT-2.
1. Importing Tools
I started by importing all the required tools and libraries.
2. Importing the baseline model and tokenizer
Then, I used TFAutoModelForCasualLM and AutoTokenizer to automatically load the correct model based on a specific checkpoint. A checkpoint contains the weights of a pre-trained model.
In this case, I imported the DistilGPT-2 checkpoint. I also set the end-of-sequence token as a padding token.
3. Importing Data
The dataset for the fine-tuning operation is available on the Huggingface Hub, and it’s a subset of a bigger dataset hosted on Kaggle.
The original dataset, published by Cornell University, contains titles and abstracts of 1.7M+ scientific papers belonging to the STEM category. The subset hosted on the Huggingface Hub contains information on around 100K papers pertaining to the machine learning category.
I decided to fine-tune DistilGPT-2 on abstracts only. I started by loading the dataset from the Huggingface Hub.
The dataset consists of 117592 rows and has 4 columns (two of them are useless).
After this step, I decided to visualize the length distribution of the abstracts (in terms of words) with a histogram.
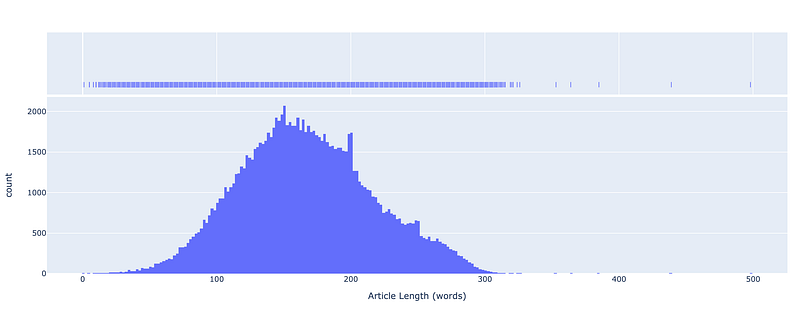
Most of the abstracts are between about 100 and 250 words in length, and only a few are over 300 words. In particular: mode=150, mean=167, and median=164.
In addition to giving information about the dataset, the histogram allowed me to determine the maximum length of the inputs to be fed to the model.
I decided to set the maximum input length to 300 tokens: abstracts longer than this will be truncated. This is because all inputs must be padded to the same length, and long sequences of text greatly increase the training time.
4. Split into Train and Validation Set
Next, I split the dataset into train and validation sets with train_test_split() . It is also possible to specify the partition sizes with the test_size parameter.
train_test_split() returns a dictionary of Datasets, formerly a DatasetDict. While it is possible to work with a DatasetDict, I prefer to use two separate Datasets: train and val.
5. Tokenize Data with HF Tokenizer
To tokenize the data I defined a generic tokenization function, and then I applied this function to all the samples by using map(). Inside the tokenization function, I used the tokenizer imported in the beginning.
The tokenizer has some important parameters to set:
- column to tokenize. In this case “abstract”.
- padding. In this case = “max_lenght” to pad a sequence to the maximum length specified by the max_length parameter.
- truncation. If true, truncates sequences longer than the maximum length, specified by the max_length parameter.
- max_length. Specifies the maximum length of a sequence.
Please note that by default the map() method sends batches of 1000 samples.
6. Adding Labels to Train and Validation Sets
In Casual Language Modeling, the labels are the input tokens (input_ids) right-shifted. This operation is automatically done by the Huggingface transformer, thus I created a labels column in the datasets with a copy of the tokens (input_ids).
After this operation, the train and validation sets had three columns: input_ids and attention_mask from the tokenization process, and labels from the create_labels() process.
7. Converting Train and Validation Sets to TF Datasets
Next, I converted the datasets to tf.data.Dataset, that Keras can understand natively; for this purpose I used Model.prepare_tf_dataset().
With respect to the Dataset.to_tf_dataset() method, Model.prepare_tf_dataset() can automatically determine which column names to use as input and provides a default data collator.
Note that I only shuffled the train data. After some experiments, I found that the optimal batch size = 16.
8. Compiling, Fitting, and Evaluating the Model
Before fitting the model, I set up a learning rate scheduler and an optimizer. I used the ExponentialDecay scheduler from Keras and the AdamWeightDecay optimizer from Huggingface.
Learning rate decay is a technique to reduce the learning rate over time. With exponential decay, the learning rate is reduced exponentially.
Next, I compiled the model. Transformers models generally compute loss internally and there is no need to specify a loss parameter. For language modeling the selected loss is cross-entropy.
At this point, I set up a callback to the Huggingface Hub to save the fine-tuned model.
I also set up a callback to Tensorboard.
Finally, I fitted the model by calling the fit() method. I specified the train and validation sets and the number of epochs.
After the training step, I evaluated the model and got its cross-entropy loss on the validation set.
Loss=2.2371. Generally, the quality of a language model is measured in ‘perplexity’. To convert cross-entropy to perplexity, I simply raised e to the power of the cross-entropy loss.
In this case perplexity=9.37.
9. Generating Text Using a Pipeline
At this point, I leveraged the pipeline functionality provided by Huggingface to see the model in action.
I set up a text-generation pipeline and specified the fine-tuned model, the tokenizer, and the framework to use. max_new_tokens allows specifying the maximum number of tokens (words) to generate in addition to the initial prompt provided.
Two lines of code are enough to generate text with a pipeline:
The pipeline is not the only way to use a model: it is possible to manually tokenize the prompt, generate new tokens, and decode the tokens to natural language. Here’s an example:
12. Results Analysis
After fine-tuning the model, I wanted to understand what the model has learned and how the generated text is influenced by the fact that paper abstracts were used for training.
First, I generated a sample text by using “the role of recommender systems” as a prompt. This is the output generated by the model:
'the role of recommender systems in the real-world is still largely to be demonstrated by the lack of data and the need for data. Hence, for many recommendation systems such as Amazon or Spotify, it is necessary to provide a user knowledge of the content that has been clicked during the recommendation and provide a user knowledge of the user preferences. The previous works attempt to exploit data related to items they have clicked during an appropriate time frame. But little attention has been paid to the problem of item classification where a suitable time-frame is available for user prediction. In this paper, we propose a multi-task learning approach to address the problem of item classification. For each task, we apply the contextual cues introduced by the user, and then learn to predict the user's purchased items' interests. Since the contexts of user preferences, we consider the feature that the user's preference (the time-frame) is present at the time of recommendation. In particular, we propose an alternative method for attribute-aware learning that utilizes the contextual cues in the sequence and the user's preferences to learn a classifier that classifies the user according to the contextual cues. This is done by maximizing the mutual information between the user's rating and the content-aware prediction task. The experimental results show that our model achieves better accuracy than the existing state-of-the-art methods, achieving up to 33.6% more accuracy on real-world recommendation tasks compared to the state-of-the-art methods. Our source code is available at http://github.com/J-medylerFashion/jmedian.github.'This result sounded somehow copied & pasted from one of the existing abstracts, but after a check with some anti-plagiarism solutions, I realized that it is 100% unique.
During learning, the model captured common features of the abstracts and learned how to replicate them while still generating fresh text. Interestingly, the model used scientific language and common expressions: The previous works…, In this paper…, We propose…, The experimental result….
The model also learned that sometimes a repository is added to the abstract: in this example, the text generated contains an URL to a GitHub repository. The URL and the repository don’t exist, thus have been generated by the model (and not copied).
As a second experiment, I generated a sample text by using “clustering” as a prompt. In this case, the prompt consisted of only one word, so the text generation is not driven by additional context. This is the output:
'clustering can be used to extract clusters from data points. However, in many real-world scenarios, data points often appear in non-Euclidean relaxations, which allows different clusters to be discovered simultaneously without the need for specific optimization. In this paper, we consider a class of applications where clustering methods are applied. A common example is that in image selection problems, we show to the optimizer that the expected improvement will be obtained by minimizing the average performance of the clustering method. Our main contribution is a characterization of optimization problems with respect to clustering methods. Specifically, we present a generalization of the optimal transport method for which our special bounds in terms of the maximum number of clusters are derived. We apply this algorithm to classification of human brain tumors, showing that it is computationally efficient. We show that based on our analysis of a particular type of tumor, our analysis leads to faster convergence to the optimal solution.'Also in this case the text is reported to be unique and there are common expressions: In this paper…, Our main contribution…, We present….
For the third experiment, I used “transformers for text generation”. Here’s the result:
'transformers for text generation are becoming increasingly popular in computer vision, and so are the prevalent datasets that contain high-dimensional representations without manual feature engineering. We propose two algorithms for image generation from convolutional networks. We give the first procedure to remove important parts of this architecture and propose a novel architecture dubbed Multi-scale Text Generation Network (MTVGNet). Our MTVGNet-like architecture produces a compact set of representations without changing the model architecture or the pre-trained convolutional network. The resulting representation is compact and can be used as both training examples in training and inference in inference. Extensive numerical experiments on image synthesis and computer vision demonstrate that MTVGNet-like improves generative model performance by up to 32% over state-of-the-art methods for unconditional image generation, while incurring only 20% higher frame quality.'Even in the third example, there are multiple elements common to scientific abstracts, and the overall quality is slightly better than the previous one.
The cited Multi-scale Text Generation Network (MTVGNet) seems to be an “invention” of the model since I cannot find references in the literature.
I’d like to conclude this section with some word clouds. The first one represents the most frequent words in all the abstracts in the dataset. The others depict the most common words in 10 text samples generated from different prompts.
It is possible to immediately notice the similarity of words between the dataset abstracts and the generated samples.

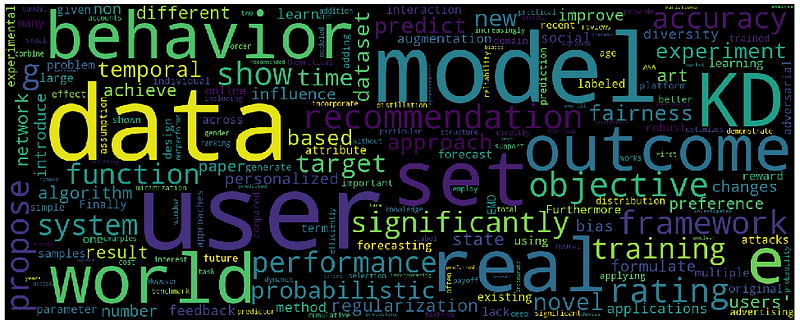

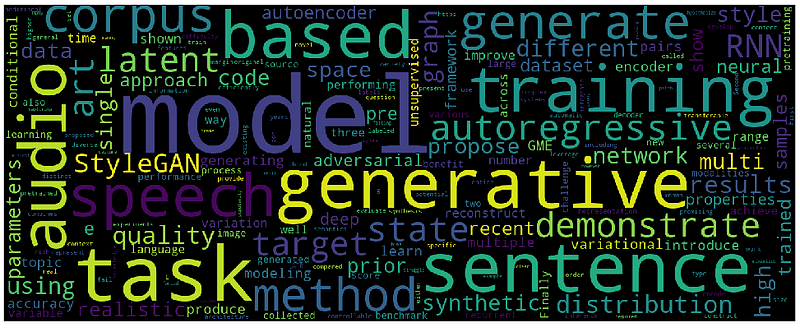
Conclusions
In this article, I fine-tuned a transformer on scientific paper abstracts. What is the quality of the result? What are the limitations of this approach? Is it possible to get GPT-2 to write a full paper?
The model has learned how abstracts are generally written and tries to replicate the same style. The results are not bad considering the available data and only one training epoch.
The model seems to be able to generate technical text about different machine learning topics, but the result does not always make complete sense and sometimes there are mistakes.
Certainly, this approach has some limitations, one of which is the length of generated text. Although it is possible to overcome the problem by generating multiple blocks of text, at some point it would be hard to logically connect the different sections generated.
In conclusion, even if the model cannot write an entire technical article, I am still surprised and convinced that some of the achievable results can still be inspiring or cueing.
Thanks for reading!
Additional Resources
- E. Bianchi, Fine-Tuning GPT-2 for Text Generation with Tensorflow (2022), Google Colaboratory
- Hugging Face, Documentation (2022)
- Hugging Face, Distilgpt2 (2022)
- Cornell University, arXiv Dataset on Kaggle (2022)
- CShorten, ML-ArXiv-Papers dataset (2022)
- Wikipedia contributors, Perplexity (2022)
- Wikipedia contributors, Cross Entropy (2022)
- Wikipedia contributors, GPT-2 (2022)
- Keras team, Keras Documentation: ExponentialDecay (2022)
More content at PlainEnglish.io. Sign up for our free weekly newsletter. Follow us on Twitter, LinkedIn, YouTube, and Discord. Interested in Growth Hacking? Check out Circuit.





